効果検証入門 5章回帰不連続デザイン 俺俺メモ
効果検証入門を買った。因果推論系はあまりちゃんと手を動かしていないので、気になったところのみ自分なりにまとめる。

- 作者:安井 翔太
- 発売日: 2020/01/18
- メディア: 単行本(ソフトカバー)
過去記事
5章回帰不連続デザイン
回帰分析なり傾向スコアなりでは、介入群と非介入群それぞれで同質のサンプルが確保されている必要があった。しかし、例えば「30歳以上は介入」のように決定する場合は両群で同質のサンプルを確保することができずに年齢によるセレクションバイアスが生じる。
このような場合は回帰不連続デザイン(RDD)をおこなう。これは要するに、「30歳前後の29歳と30歳は性質的に変わらんでしょ」ということを利用している。
線形関係
以下のようなRCTデータに対して、visitとlog(history)が線形関係と仮定したモデルで考える。

また、このデータを加工してlog(history)=5.5を閾値として施策がされる状態に加工したRDDデータを作成する。

RCTデータでは、以下のような結果から施策効果は0.08ほどになる(サンプルコードではコメントアウト部だったが変更)。
## RCTデータ # male_data %>% # filter(history_log > 5, history_log < 6) %>% # group_by(treatment) %>% # summarise(count = n(), # visit = mean(visit)) # サンプルコードは集計だが後のコードに合わせて回帰でやる male_data %>% filter(history_log > 5, history_log < 6) %>% lm(data = ., formula = visit ~ treatment) %>% summary() %>% tidy() %>% filter(term == "treatment") term estimate std.error statistic p.value <chr> <dbl> <dbl> <dbl> <dbl> 1 treatment 0.0792 0.00611 13.0 3.24e-38
ちなみに、上記サンプルコードではlog(history)=5.5前後0.5(5.0~6.0)でフィルタリングしている。これは、後のRDDと同様の位置に対する比較(推定したいものが閾値付近のデータ)をしたいから条件を整えている。仮に施策変数log(history)が増加する毎にYが増加する、というような関係がない場合はデータ全体を使った結果と一致する。逆に、施策変数が増加するとYも増加するというような関係があるならば閾値付近での施策効果と全体での施策効果は一致しないことになるので、RDDは全体に対するRCTとも一致しないことになる(閾値付近でのRCTとは一致)。
また、RDDでは閾値付近で施策変数(今回はhistory)以外のYに影響がある変数も閾値付近で大きく変わらない(連続している)という前提(Continuity of Conditional Regression Functions)もあるため施策変数自体を目的変数としてRDDをするなどで確認が必要。
更に、介入されるかどうかを自身で調整できない(non-manipulation)という前提も必要となる。例えば、「本来は非施策群だが、あと少しだけ買い物をしたら施策群に入ることを知っているので本来より少し買い物をして施策群になる」といったようなことがおこなわれると本来の非施策群が施策群になってしまうことでそれぞれの群の分布が歪んでしまう。これは閾値前後のサンプル密度をみて不自然に密度に差がないか確認することができる。
これらの前提はつまり、「閾値付近の範囲内であればRCTと同様の状況になっているといっていいための条件」と考えるとイメージしやすい。
# 閾値以外も含めて推定 male_data %>% #filter(history_log > 5, history_log < 6) %>% lm(data = ., formula = visit ~ treatment) %>% summary() %>% tidy() %>% filter(term == "treatment") term estimate std.error statistic p.value <chr> <dbl> <dbl> <dbl> <dbl> 1 treatment 0.0766 0.00339 22.6 1.27e-112
RDD用データで同様にvisit ~ treatmentで回帰をすると以下になる。
# (6) 回帰分析による分析 ## 線形回帰による分析 rdd_data %>% mutate(treatment = ifelse(segment == "Mens E-Mail", 1, 0)) %>% lm(data = ., formula = visit ~ treatment) %>% summary() %>% tidy() %>% filter(term == "treatment") term estimate std.error statistic p.value <chr> <dbl> <dbl> <dbl> <dbl> 1 treatment 0.133 0.00487 27.4 2.07e-162
treatmentの効果はRCTより0.05ほど増加している。これは、log(history)をもとに割り振りを決めているため、共変量log(history)でコントロールする必要がある。
rdd_data %>% mutate(treatment = ifelse(segment == "Mens E-Mail", 1, 0)) %>% lm(data = ., formula = visit ~ treatment + history_log) %>% summary() %>% tidy() %>% filter(term == "treatment") term estimate std.error statistic p.value <chr> <dbl> <dbl> <dbl> <dbl> 1 treatment 0.114 0.00798 14.2 8.40e-46
treatmentの効果はlog(history)でコントロールしなかったときより0.02ほどRCT時に近づいた。なお、このとき回帰分析の性質上、閾値付近のデータの影響が大きい。つまり、実質的に使用されているサンプルは閾値付近と同じ意味(閾値周辺の効果LATEが推定される)となる(のように読み取れる内容)・・・と本書では書いてるけど下記のように結果がかなり変わるのでうーん・・って感じ。他の章での記載を読む感じ、正確には「閾値付近ほど推定値への影響力が高くなる」のであって「閾値だけの結果とイコールではない」ってことなんだろうけど。
また、そもそもデータからわかるようにこのデータは非線形関係のデータに対して上記では線形のモデルを立てている一方で、サンプルを絞った場合はノンパラメトリックになっているからその乖離か?はじめから関係性が正しいモデルであれば近くなるのだろうか(後述)。
なお、実際にサンプルを閾値付近のみにした場合(後述のノンパラメトリックRDD)はRCTにかなり近い値になった。
rdd_data %>% filter(history_log > 5, history_log < 6) %>% # 閾値付近のみ mutate(treatment = ifelse(segment == "Mens E-Mail", 1, 0)) %>% lm(data = ., formula = visit ~ treatment + history_log) %>% summary() %>% tidy() %>% filter(term == "treatment") term estimate std.error statistic p.value <chr> <dbl> <dbl> <dbl> <dbl> 1 treatment 0.0738 0.0172 4.29 0.0000179
非線形関係
介入変数と目的変数の関係が非線形な場合を捉えたい場合は乗数をいくつもモデルに組み込む。しかし、2乗がいいのか3乗がいいのか...といった高次の多項式(polynomial)を試すのは面倒だが、rddtoolsを使うと楽(らしいが、Rが3.0系でしか対応してない?。
コードが動かないので、結果だけ書くと4次の多項式で、施策効果の推定値は0.074となるようだ。
前説で
はじめから関係性が正しいモデルであれば近くなるのだろうか
と記載したが、今回も線形のときと同様に全データを使っているが推定値は0.074となりRCTとの違いは0.05で非常に近くなっている。
ノンパラメトリックRDD
また、先程は関係を仮定していた(パラメトリック)が仮定せずに使えるノンパラメトリックなRDDもある。これは、閾値付近のみにデータを絞って回帰をおこなうやりかたとなっている。
以下は横軸が閾値から前後にどれくらいの範囲内でのサンプルに絞っているかを示す。縦軸は、施策効果の推定値となり範囲が狭まっているほどバイアスが少なくなる一方でサンプル数が少なくなるので分散は大きくなる。*1
# (7) 分析に使うデータの幅と分析結果のプロット bound_list <- 2:100/100 result_data <- data.frame() for(bound in bound_list){ out_data <- rdd_data %>% filter(between(history_log, 5.5 - bound, 5.5 + bound)) %>% group_by(treatment) %>% summarise(count = n(), visit_rate = mean(visit), sd = sd(visit)) late <- out_data$visit_rate[2] - out_data$visit_rate[1] N <- sum(out_data$count) se <- sqrt(sum(out_data$visit_rate^2))/sqrt(N) result_data <- rbind(result_data, data.frame(late, bound, N, se)) } result_data %>% ggplot(aes(y = late, x = bound)) + geom_ribbon(aes(ymax = late + 1.96*se, ymin = late - 1.96*se), fill = "grey70") + geom_line() + theme_bw()

rddパッケージを用いるとノンパラメトリックRDDが簡単に実行できる。
# (8) nonparametric RDD ## ライブラリの読み込み library("rdd") ## non-parametric RDDの実行 rdd_result <- RDestimate(data = rdd_data, formula = visit ~ history_log, cutpoint = 5.5) ## 結果のレポート summary(rdd_result) # => 後述のキャプチャ ## 結果のプロット plot(rdd_result)
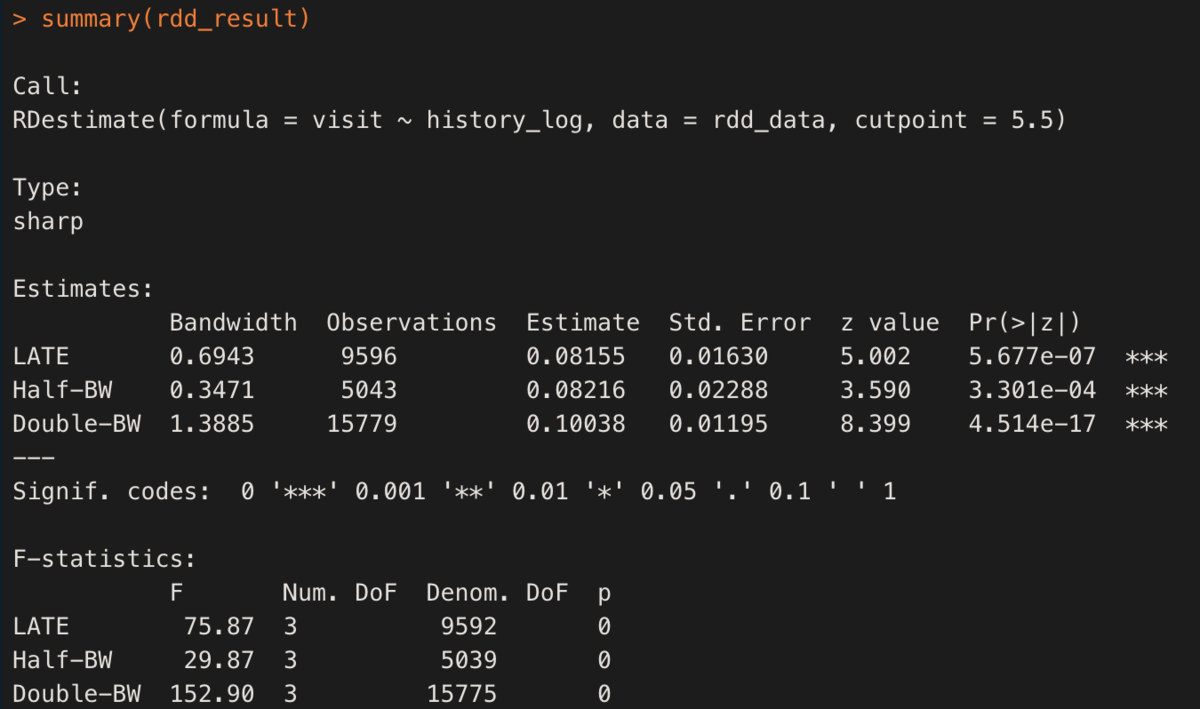
このとき、LATE を見るとBandwith(範囲)はCrossValidationによって自動で決定され(bwオプションで任意の値を指定することも可能)、そのときの推定値などが表示される。Half-BWはBandwiseを半分、Double-BWは2倍にしたときの結果となる。
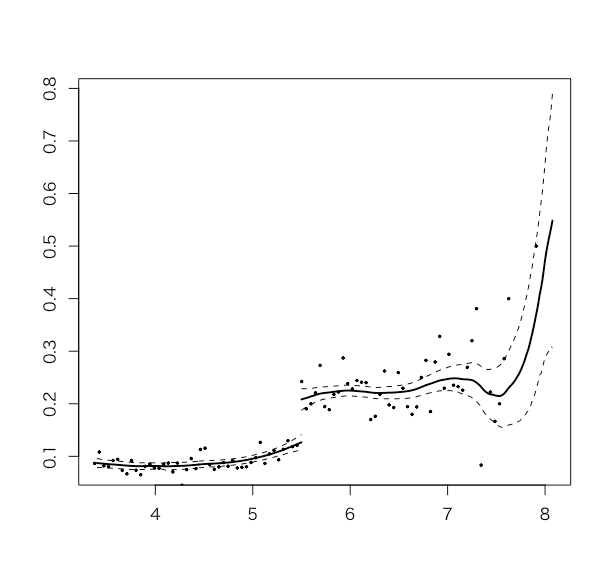
また、このときどのような回帰がされたかをplotできる。このときの閾値前の回帰線と閾値後の回帰線を用いた閾値でのYの推定値の差分が施策効果(Estimate)として出ている。
前述のnon-manipulationの前提をDCdensityによって、manipulationされていないかの確率(p値)の出力として確認ができる。
## manipulat DCdensity(runvar = rdd_data %>% pull(history_log), cutpoint = 5.5, plot = FALSE) # => 0.6302935
*1:施策効果の推定は各期待値の差から求まる