atmaCup #12に参加して覚えたことメモ②lightGBM関係
これはなにか
データ分析コンペのatmaCup #12に参加して、他の人のコードを読んで覚えたことのメモです。
コンペのdiscussionで公開されているコードの書き方がとても勉強になったのですが、自分のエンジニアリング力がゴミで読解に時間がかかったので解釈用にどういう処理がされてるか読解したメモです。
コンペはよく「Discussion読もうぜ!」と聞きますが、エンジニアリング力が弱いと「そこで書かれているコードが何のコードかはコメントでなんとなくわかるけど処理がよくわからんのでただコピペしてるだけ。それを利用したり加工したりはできない・・・」となってしまうのでちゃんと書いているコードの意味も紐解きながら理解する必要があるかなぁと思います。
なお、コンペ自体はクローズドなのでポリシーに違反しないようにtitanicデータを使ってますが、一部解釈用コメントを追加したりデータに合わせて処理を加工したりしていますが元のコードコメント含めてコアとなるコードはコピペです。
また、コピペ参考元のコンペリンクは貼っているものの、コンペ参加者以外は404エラーになるのでご注意ください。そのため参考コードは引用元がわかるようTwitterリンクを貼るとともに許可を得て掲載しています。
この記事はlightGBMの処理に関して。なお、特徴量作成に関しては別記事にまとめている。
下準備
titanicを加工したデータを使う。最低限の前処理したデータをtrain testとして、それらをArrayでX,yにする
X = train.drop(['Survived'], axis=1).values y = train['Survived'].values
また、前回の記事同様に時間計測があると便利なので@nyker_gotoさん作成のTimer Classを使っている。
from time import time class Timer: def __init__(self, logger=None, format_str="{:.3f}[s]", prefix=None, suffix=None, sep=" "): if prefix: format_str = str(prefix) + sep + format_str if suffix: format_str = format_str + sep + str(suffix) self.format_str = format_str self.logger = logger self.start = None self.end = None @property def duration(self): if self.end is None: return 0 return self.end - self.start def __enter__(self): self.start = time() def __exit__(self, exc_type, exc_val, exc_tb): self.end = time() out_str = self.format_str.format(self.duration) if self.logger: self.logger.info(out_str) else: print(out_str)
Cross Validationをいい感じに実行する
Cross Validationをやるにあたり、sklearn.model_selection.cross_val_predictとかで予測値は出せるものの、各validationでのOOFの予測や学習状況、モデルや精度などを取り出すことはできない。だが、各validationで変な偏りなどが生まれていないかなどのチェックにあたってこの情報は大事。そのため、それらを取得できるように関数を作る。
内容としては、関数のパラメータとしてcross validationのFoldの取り方をlistとして渡すことで関数内部でtrainとvalidationを作成し、モデルの学習・OOFの予測・確率のラベル変換・評価をおこないモデルとOOF予測を保存・・・ということを各FoldでおこなうことでOOFの複合、つまりtrainデータに対する予測(各インスタンスはそのインスタンス学習で使われてないモデルで予測)および各Foldでのモデルを返します。また、合わせて学習時間も返します。
これは@tawatawaraさんのDiscussionを参考にさせてもらっている。
from sklearn.metrics import f1_score import lightgbm as lgbm def fit_lgbm( X, y, cv, model_params, fit_params, ): """lightGBM を Cross Validation で学習""" models = [] n_records = len(X) n_labels = len(np.unique(y)) # training data の target と同じだけのゼロ配列を用意してoofの予測値をあとで入れる oof_pred = np.zeros((n_records, n_labels), dtype=np.float32) for i, (trn_idx, val_idx) in enumerate(cv): X_trn, y_trn = X[trn_idx], y[trn_idx] X_val, y_val = X[val_idx], y[val_idx] trn_data = lgbm.Dataset(X_trn, label=y_trn) val_data = lgbm.Dataset(X_val, label=y_val) with Timer(prefix="fit fold={} ".format(i)): clf = lgbm.train( model_params, trn_data, **fit_params, valid_sets=[trn_data, val_data]) pred_i = clf.predict(X_val, num_iteration=clf.best_iteration) # binaryのpredictは1の確率のみを返すので0,1どちらともの確率となるように作り変える # 多値分類だと各ラベルの確率がpredixtが返ってくるのでこの処理は不要 pred_i_2d = [] for i, j in zip(1-pred_i, pred_i): pred_i_2d.append([i, j]) pred_i = np.array(pred_i_2d) # ======== ここまで多値分類だと不要 ======== oof_pred[val_idx] = pred_i models.append(clf) # 予測値は確率になっているので argmax でラベル化する y_pred_label = np.argmax(pred_i, axis=1) # 指標を計算する score = f1_score(y_val, y_pred_label) print(f" - fold{i + 1} - {score:.4f}") oof_label = np.argmax(oof_pred, axis=1) score = f1_score(y, oof_label, average="macro") print(f"{score:.4f}") return oof_pred, models
この関数で学習をおこなう。
Cross Validationは通常のKFoldでおこなう。
from sklearn.model_selection import KFold fold = KFold(n_splits=5) cv = fold.split(X, y) cv = list(cv) # split の返り値は generator なので list 化して何度も iterate できるようにしておく
パラメータは暫定的に以下
model_params = {
"boosting_type": "gbdt",
"objective": "binary",
"metric": "binary_logloss",
#"metric": None,
"learning_rate": 0.05,
"max_depth": 12,
"reg_lambda": 1.,
"reg_alpha": .1,
"colsample_bytree": .5,
"min_child_samples": 10,
"subsample_freq": 3,
"subsample": .8,
"random_state": 999,
"verbose": -1,
"n_jobs": 8,
# 特徴重要度計算のロジック
"importance_type": "gain",
"random_state": 71,
}
fit_params = {
"num_boost_round": 20000,
"early_stopping_rounds": 200,
"verbose_eval": 100,
"fobj": None,
"feval": None,
}
そして以下のように学習を実行
oof, models = fit_lgbm(X, y, cv, model_params, fit_params) ''' 学習過程ログ Training until validation scores don't improve for 100 rounds. Did not meet early stopping. Best iteration is: [99] valid_0's binary_logloss: 0.449694 fit fold=0 0.728[s] - fold1 - 0.7009 Training until validation scores don't improve for 100 rounds. Did not meet early stopping. Best iteration is: [53] valid_0's binary_logloss: 0.459678 fit fold=1 0.669[s] - fold2 - 0.7660 Training until validation scores don't improve for 100 rounds. Did not meet early stopping. Best iteration is: [99] valid_0's binary_logloss: 0.376929 fit fold=2 0.698[s] - fold3 - 0.8182 Training until validation scores don't improve for 100 rounds. Did not meet early stopping. Best iteration is: [100] valid_0's binary_logloss: 0.427503 fit fold=3 0.703[s] - fold4 - 0.7143 Training until validation scores don't improve for 100 rounds. Did not meet early stopping. Best iteration is: [91] valid_0's binary_logloss: 0.342852 fit fold=4 0.705[s] - fold5 - 0.8320 0.7676 '''
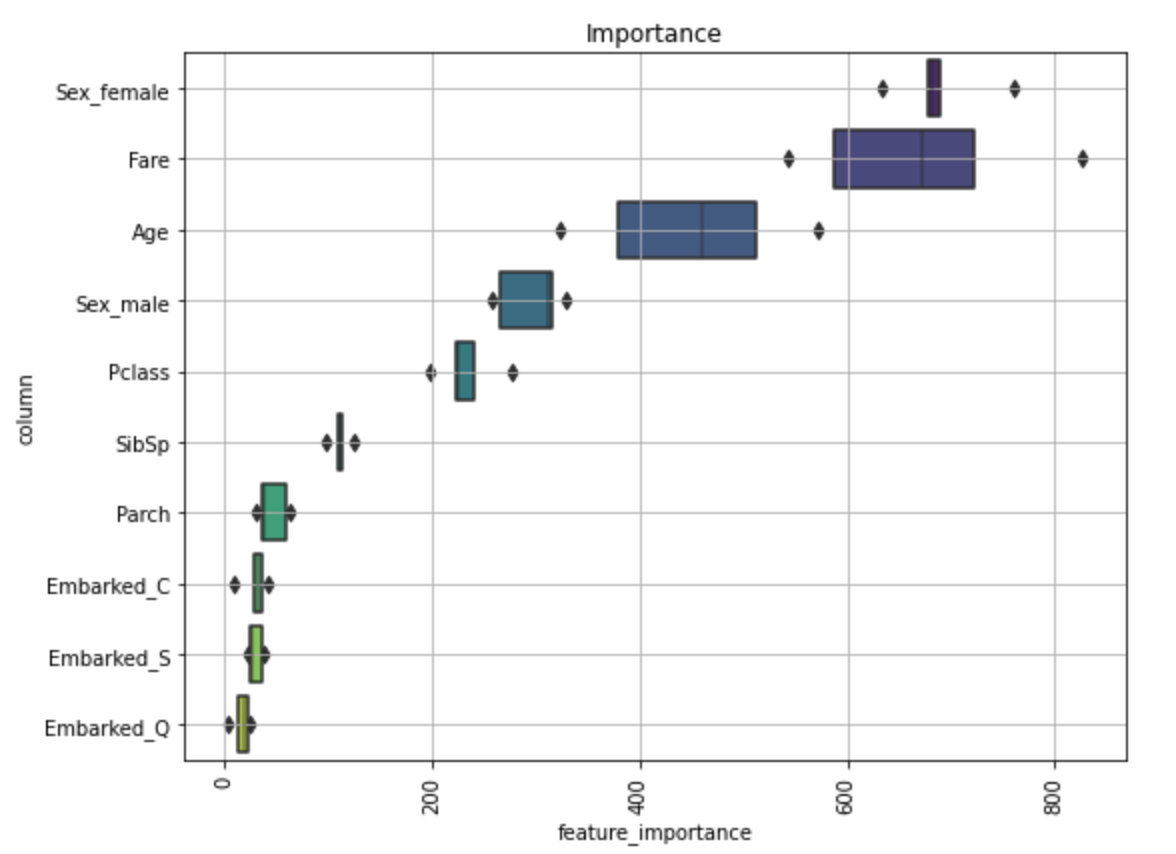
なお、modelsに各foldのモデルが保存されているのでモデル毎の重要度のブレつきで変数重要度をみることができる。
これは@nyker_gotoさんのdiscussionを参考にしました。
import matplotlib.pyplot as plt import seaborn as sns def visualize_importance(models, feat_train_df): """lightGBM の model 配列の feature importance を plot する CVごとのブレを boxen plot として表現します. args: models: List of lightGBM models feat_train_df: 学習時に使った DataFrame """ feature_importance_df = pd.DataFrame() for i, model in enumerate(models): _df = pd.DataFrame() _df["feature_importance"] = model.feature_importances_ _df["column"] = feat_train_df.columns _df["fold"] = i + 1 feature_importance_df = pd.concat([feature_importance_df, _df], axis=0, ignore_index=True) order = feature_importance_df.groupby("column")\ .sum()[["feature_importance"]]\ .sort_values("feature_importance", ascending=False).index[:50] fig, ax = plt.subplots(figsize=(8, max(6, len(order) * .25))) sns.boxenplot(data=feature_importance_df, x="feature_importance", y="column", order=order, ax=ax, palette="viridis", orient="h") ax.tick_params(axis="x", rotation=90) ax.set_title("Importance") ax.grid() fig.tight_layout() return fig, ax X_train = train.drop(['Survived'], axis=1) fig, ax = visualize_importance(models, X_train)
カスタムメトリクスを使う
訓練時の損失関数を自作のものにしたい場合、上記fit_lgbm関数に渡すパラメータfit_paramsのfevalに計算したい関数を指定する。また、model_paramsのmetricはNoneにしておく。理由としては何も指定しない場合はearly stoppingが、
metric になにも渡さない場合は objective (今回は binary logloss)に対応したものが metric に使用
とあるように、early stoppingが想定外の動きになることがあるため。
今回はaccuracyを損失関数にする。このcustom metricsに指定する関数は引数としてpreds(list or numpy 1-D array)、train_data(Dataset)を取り、returnとして eval_name, eval_result, is_higher_betterとなるようにする。
例えばF1-macroを使いたい場合は以下のようになる。なお、is_higher_betterはF1-macroの場合高いほどよいのでTrueにする。
def f1_macro_score(preds, data): y_true = data.get_label() y_pred = preds.reshape(len(np.unique(y_true)), -1).argmax(axis=0) score = f1_score(y_true, y_pred, average='macro') return 'macro_f1', score, True
また、今回はbinaryなので問題ないが下記の記事
注意点として、モデルが予測した値は多値分類問題であっても一次元の配列になっているため reshape する必要がある。 評価指標を計算する関数では、返り値として評価指標の名前、スコア、そしてスコアが大きい方が優れているのか否かを表す真偽値を返す。
の点は注意する。
def accuracy(preds, data): """精度 (Accuracy) を計算する関数""" y_true = data.get_label() y_pred = np.round(preds) # 0.5を閾値に変換 score = np.mean(y_true == y_pred) # name, result, is_higher_better return 'accuracy', score, True model_params = { "boosting_type": "gbdt", "objective": "binary", #"metric": "binary_logloss", "metric": None, # Noneに指定 "learning_rate": 0.05, "max_depth": 12, "reg_lambda": 1., "reg_alpha": .1, "colsample_bytree": .5, "min_child_samples": 10, "subsample_freq": 3, "subsample": .8, "random_state": 999, "verbose": -1, "n_jobs": 8, # 特徴重要度計算のロジック "importance_type": "gain", "random_state": 71, } fit_params = { "num_boost_round": 20000, "early_stopping_rounds": 200, "verbose_eval": 100, "fobj": None, "feval": accuracy, # accuracyで計算 } oof, models = fit_lgbm( X, y, cv, model_params, fit_params) ''' 学習過程ログ Training until validation scores don't improve for 200 rounds. [100] training's accuracy: 0.896067 valid_1's accuracy: 0.810056 [200] training's accuracy: 0.925562 valid_1's accuracy: 0.798883 Early stopping, best iteration is: [60] training's accuracy: 0.882022 valid_1's accuracy: 0.815642 fit fold=0 1.601[s] - fold1.8786250989595632 - 0.7886 Training until validation scores don't improve for 200 rounds. [100] training's accuracy: 0.903226 valid_1's accuracy: 0.825843 [200] training's accuracy: 0.928471 valid_1's accuracy: 0.825843 Early stopping, best iteration is: [86] training's accuracy: 0.897616 valid_1's accuracy: 0.837079 fit fold=1 1.781[s] - fold1.055654839644024 - 0.8313 Training until validation scores don't improve for 200 rounds. [100] training's accuracy: 0.896213 valid_1's accuracy: 0.865169 [200] training's accuracy: 0.920056 valid_1's accuracy: 0.859551 Early stopping, best iteration is: [77] training's accuracy: 0.889201 valid_1's accuracy: 0.876404 fit fold=2 1.694[s] - fold1.5276741576164063 - 0.8667 Training until validation scores don't improve for 200 rounds. [100] training's accuracy: 0.900421 valid_1's accuracy: 0.797753 [200] training's accuracy: 0.928471 valid_1's accuracy: 0.808989 [300] training's accuracy: 0.938289 valid_1's accuracy: 0.803371 Early stopping, best iteration is: [166] training's accuracy: 0.920056 valid_1's accuracy: 0.808989 fit fold=3 2.211[s] - fold1.943120167044094 - 0.7926 Training until validation scores don't improve for 200 rounds. [100] training's accuracy: 0.893408 valid_1's accuracy: 0.870787 [200] training's accuracy: 0.911641 valid_1's accuracy: 0.865169 Early stopping, best iteration is: [65] training's accuracy: 0.882188 valid_1's accuracy: 0.882022 fit fold=4 1.599[s] - fold1.7834760820013806 - 0.8685 0.8304 '''