DIDと傾向スコアを用いた手法の使い分け
なにを書くか
岩波DS vol.3(因果推論)のp.91で傾向スコアを用いて「スマホアプリ利用時間」に対する「CM接触効果」を調べるようなデータについて。本文中では、傾向スコア(Propensity Score)を用いて平均CM接触効果(ATE)を測っているが、これはCM施策前後の比較としてDID(Difference In Difference)でもできるのでは?と考えて調べました。

- 発売日: 2016/06/10
- メディア: 単行本(ソフトカバー)
では、そもそも どういうときに傾向スコアを用いて、どういうときにDIDを使うのか? という疑問がわいたので、主に使い分けについて記載します。
なお、各手法の概要は以前書いた以下を参照。
結論
それぞれ使用するにあたり 前提として置く仮定に必要となる共変量の性質が違う ため、利用可能な共変量に従って使う。
ただし、DID・傾向スコアどちらも使用ができる場合は、DIDでは固定効果によるバイアスを無視できるのでDIDを使う。
それぞれの前提となる仮定
DID
DIDに置いている仮定として、 「共通ショック仮定(common shocks assumption)」と「平行トレンド(Common trend assumption)仮定」 がある。
また、基本的なことだが、 施策前と後の2時点の目的変数が必要。
以下、説明のためにTJOさんのブログから画像をお借りする。
統計的因果推論(1): 差分の差分法(Difference-in-Differences)をRで回してみる - 渋谷駅前で働くデータサイエンティストのブログ
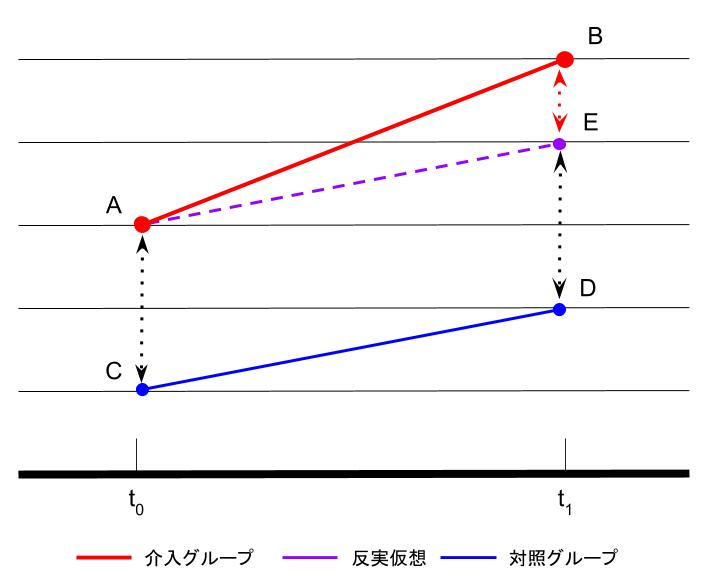
共通ショック仮定
効果を見たい施策以外に、と
の間で目的変数に影響を与えるイベントがなかった、あるいは介入群と対照群に全く同じ影響があった、という仮定。
平行トレンド
介入群に介入が行われなかった場合、対照群と同じ推移をする、という仮定(反実仮想)。
施策を受けなかったならば(C-D)と全く同じ振る舞いをするという仮定を置くことで、 実際観測できない(A-E)を計算することができる 。
2群の間に平行トレンドがない場合は、 目的変数に影響を与えるが 2群で与える影響が違う共変量を用いる ことで統制をおこない、平行トレンドとなるように調整をおこなう。
介入群と対照群について
この推定は介入群の点Aから、平行トレンドの(C-D)を用いることで介入群の点Eを推定している。そのため、介入群自体の異なる時点のデータをベースにしており、対照群は平行トレンド部分のみを利用する。
つまり、施策前の介入群から施策後の介入群を推定している。同じ群を用いているので、次に紹介する傾向スコアと違い、介入群と対照群に属する人の性質の分布の違いを気にする必要はない。
傾向スコア
あえて先程と同じ図を用いる。下図でいうところ、時点のみが必要で介入群の点Bと、介入群が仮に介入を受けなかった場合の点Eを比較することで効果をみたい。
ただし、当たり前だが点Eは実際に観測することができない。そのため、介入を受けていない対象群の点Dを使いたい。
しかし、RCTではない多くの場合は介入を受けるかどうかの割当は属性で偏りがあるので、介入群と対照群で所属する人の属性分布が違うので (B - E) ≠ (B - D)となる。
言い方を変えると、所属する人の属性分布が同じであるならば(B - E) = (B - D)となる。そのため、介入群と対照群が同じ分布となるように 介入を受けるかどうかに関係がある共変量を用いて 統制をおこなう。
このとき、IPW(Inverse Probability Weighting)推定やDR(Doubly Robust)推定においては、施策群に割り当てられるかを確率で表すことで、共変量をひとまとめにした傾向スコアを用いることで調整をおこなっている。
また、傾向スコアに置いている仮定として、"strong ignorability"の仮定がある。
これは 「どちらの群に割り当てられるかは観測された共変量にのみ依存し、目的変数の値とは無関係(共変量を条件付けると目的変数と割当は独立)」 という仮定。
介入群と対照群について
この推定は対照群の点Dを用いて介入群の点Eを推定している。
つまり、推定において別の群を用いているので、DIDと違い、介入群と対照群に属する人の性質の分布の違いを気にする必要がある。
DIDと傾向スコアで必要となる共変量がどう違うか
傾向スコアを用いた手法は、strong ignorabilityの仮定を満たすための 介入を受けるかどうかの割当を調整するための共変量 が必要になり、この共変量を用いた傾向スコアを用いることで 割り当てを統制する。
DIDの場合は、平行トレンド仮定を満たすために 目的変数に影響を与えるが、2群で与える影響が違う共変量 が必要になり、この共変量で トレンドを統制する。
このように、仮定を満たすのに必要となる共変量が異なっているので使える共変量によって手法を使い分ける。
どちらとも使える場合はどうするか
一般的に、「介入を受けるかどうかの割当を調整するための共変量」にも「目的変数に影響を与えるが、2群で与える影響が違う共変量」にもなる、各サンプル固有の時間不変の 固定効果 がある(例:地域性や個人の能力など)。
ただし、この固定効果は定量的な観測が不可能な性質を持つ。
そして、観測が不可能ということはそれぞれの共変量に入れることができないのでバイアスが生じる。
・・・が、DIDの場合、差を用いるため時間不変の固定効果の影響を消すことができるためバイアスが生じない。
つまり、固定効果によってDIDではバイアスが生じないが、傾向スコアを用いた手法ではバイアスが生じる。
そのため、DID・傾向スコアを用いた手法どちらとも使える場合はDIDを用いた方が推定精度がよくなる。
おまけ。傾向スコアを用いる場合のIPW推定量とDR推定量の違い
傾向スコア自体の推定精度が低いとIPW推定量の推定精度も悪くなる。また、IPW推定量は傾向スコアを推定した後の目的変数の周辺分布の母数推定に際して、対照群のデータの共変量の情報を用いていないため、データから得られる情報の一部を無駄にしている。
これらの欠点を改善したのがDR推定量。なにがDoblyでRobustなのかというと、
- 傾向スコアの確率を求める式
- 共変量を用いて目的変数を説明する回帰式
このどちらかが誤っていてもバイアスのない推定ができる、という意味でDoblyでRobust。そのため、傾向スコアを用いる場合は常にIPW推定ではなくDR推定をおこなう。
その他
傾向スコア関係のRパッケージの使用例。
調査観察データにおける因果推論(3) - Rによる傾向スコア,IPW推定量,二重にロバストな推定量の算出 - About connecting the dots.
参考
調査観察データにおける因果推論(1) - 無作為割り当てされていないことの問題 - About connecting the dots.
調査観察データにおける因果推論(2) - 傾向スコアとIPW推定量,二重にロバストな推定量 - About connecting the dots.
因果効果の推定!Rで実践 - 傾向スコア,マッチング,IPW推定量 - - Data Science by R and Python
www.slideshare.net
差分の差分分析(Difference-in-differences design) – 医療政策学×医療経済学
プロペンシティスコア(Propensity score; PS)(2)-PSに関する5つの誤解 – 医療政策学×医療経済学