Classを用いて、特徴量作成を仕組み化する@ぐるぐる
atma#10を読んでいて、運営の初心者用講座の「よりたくさんの特徴量の作成」あたりがとてもよかったので自分なりにまとめてみる。
なお、再解釈などはおこなっているが上記リンクをベースに色々と書くだけなので、端的に知りたい場合は上記リンクを読んでください。
これはなにか
特徴量を作成する際に、各処理を1ブロックとして記載することで可読性を上げたり、テストがしやすかったり、train/testで共通のインスタンスを対象とする際にそれぞれで計算をしなくてもすむなど色々と利便性が高かったので使っていきたい。そのため自分用に整理をおこなう。
自作関数での処理との違い
特徴量作成関数の構造 第一回目では関数形式での実装方法をお伝えしました。関数形式でも問題はないのですが、少し不満があります。それは学習時とテスト時で同じ用な計算をしなくてはならない、という点です。
例えば CountEncoding のコードを思い出しましょう。CountEncoding は出現回数の計算を行なう必要がありますが、テストデータやあるいは新しい別のデータに対して CountEncoding する場合には、過去に計算したカウント情報を使って単に変換だけを行なうべきでしょう。(#1でやった方法では学習・推論で二回カウント計算が走っていることに注意してください。) このように機械学習の特徴量変換は
1.学習時に内部状態を記憶しておいて 2.推論時には 1 でつくった情報を用いて変換をする という構造をもっていることが非常に多いです(これは機械学習モデル自体も同様の構造ですね)。ですのでこの論理的な構造をコードにも反映して行きたいと思います。
上引用の例としてCountEncoding(FrequencyEncoding)が出ています。これは 過去に計算したカウント情報を使って単に変換だけを行なうべきでしょうとあるように「あるカテゴリカル特徴量に対して、TrainとTestで共通の値にする」ということになります。
これは何故かというと、TrainとTestで別の値を持つ場合そのカテゴリカル特徴量がTrainとTestで意味合いが変わる、つまりある意味では別の特徴量なのに同じ特徴料として解釈させて予測させるようなことになるからです。そのため、TrainとTestを合わせた全体でCountをおこなったり、TrainだけでCountした値をそのままTestにも使うのが一般的です。
また、別の理由としてTrain,Test片方にしか存在しないカテゴリがある場合に学習器が機能しないという問題を解決するという意図もあります。
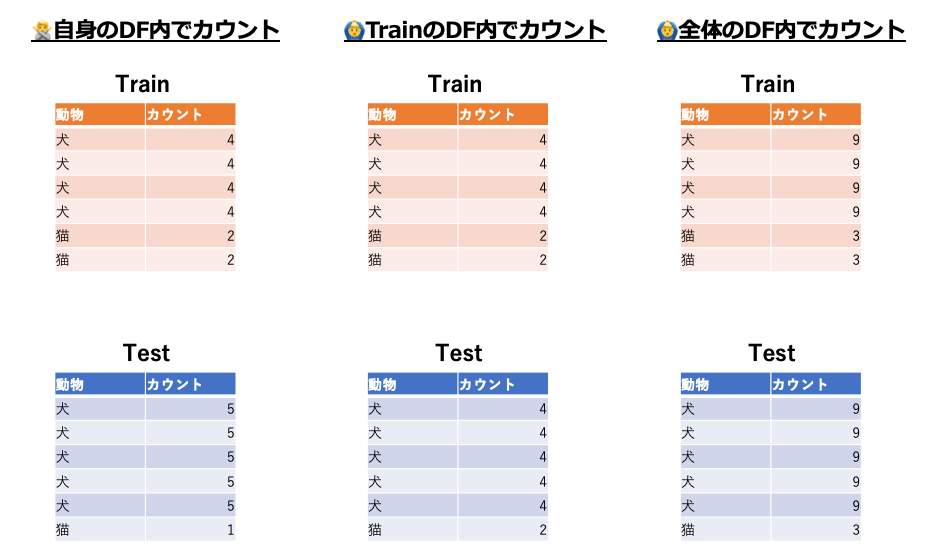
例えばLabelEncoding(OrdinalEncoding)で以下のようなデータを考えます。
Train
| 動物 |
|---|
| 犬 |
| 猫 |
| 犬 |
| 犬 |
| 猫 |
| 犬 |
Test
| 動物 |
|---|
| 猿 |
| 豚 |
| 猿 |
| 豚 |
| 犬 |
| 犬 |
このとき、Train/Testがどう変換されるか考えるとそれぞれ以下のようになります
| 動物 | 動物(LabelEncoding) |
|---|---|
| 犬 | 0 |
| 猫 | 1 |
| 犬 | 0 |
| 犬 | 0 |
| 猫 | 1 |
| 犬 | 0 |
Testでは
| 動物 | 動物(LabelEncoding) |
|---|---|
| 猿 | 0 |
| 豚 | 1 |
| 猿 | 0 |
| 豚 | 1 |
| 犬 | 2 |
| 犬 | 2 |
みてわかるように、「動物」という特徴量で同じ値、例えば0が指すものがTrainでは犬、Testでは猿となり意味合いが変わってしまいます。また、Trainのみを使ってTestにLabelEncodingしようにもTrainには値「猿」「豚」がないのでエラーとなってしまうのでTrainとTestを合体させたデータでLabelEncodingの変換ロジックを作成する必要があります。
これと同様のことがCountEncodingでもいえます。
話を戻すと、このように全体のデータを使って計算する特徴量は関数で処理している場合、Trainデータに対する処理・Testデータに対する処理
この記事の口座#1のコードではCountEncodingを関数で処理をしているのでコードをみてみると以下のようになってます。
def create_count_encoding_feature(input_df): use_columns = [ 'acquisition_method', 'title', 'principal_maker', # and more ] out_df = pd.DataFrame() for column in use_columns: vc = train_df[column].value_counts() out_df[column] = input_df[column].map(vc) return out_df.add_prefix('CE_')
関数内でtrain_dfのあるカテゴリカル特徴量に対してvalue_counts()をしてCountEncodingで変換したものを引数で渡したDataFrameに渡して上書きしています。
実際にこの関数を使う際は、train_df, test_dfそれぞれにこの関数を走らせます。つまり、vc = train_df[column].value_counts()の部分を計2回走らせることになります。しかし、これは引数にtrain_df, test_dfどちらでもまったく同じことをやるので計算の無駄、1回計算してその値を保持しておけばいいよね、というのが引用の
1.学習時に内部状態を記憶しておいて 2.推論時には 1 でつくった情報を用いて変換をする
で書いていることになります。
参考記事をトレス
ここからは、本論の「Classを用いて特徴量を作成していく」について。
上述のような状態管理のために、Classを用いて特徴量を作成します。この構成としては、AbstractBaseBlockという抽象クラスを作成し、各特徴量作成処理毎にAbstractBaseBlockclassを継承して実装していきます。
各classの中身としては、学習(どう変換などをしていくか)のためのfit関数で状態を更新し保持し、推論(特徴量化)のためのtransform関数でinputしたDFに対して特徴量を作成し、作成された特徴量のDFを返す実装となります。
なお、どの特徴量作成処理classでも共通した名前(中身は異なる)なので、後に説明するように各特徴量作成処理classを一括で処理することができます。
この各特徴量作成処理classをブロックという単位で作成していき、最終的にそのブロックをつなぎ合わせて一括で処理をおこないます。
なお、ここからはしばらく元記事中にあるコードをコピーしつつコメントをしていきます。
ブロックを使った特徴量作成処理(コピペ)
ベースとなるAbstractBaseBlock は以下
class AbstractBaseBlock: def fit(self, input_df: pd.DataFrame, y=None): return self.transform(input_df) def transform(self, input_df: pd.DataFrame) -> pd.DataFrame: raise NotImplementedError()
抽象クラスなので、fitとtransformを仮定義。作成したい特徴量によっては内部状態の更新(fit)をしないこともありますが、推論(transform)は必ずおこなうので実装が矯正されます。
内部状態が更新されるブロック例・ CountEncoding
ここでは、CountEncodingのように何かしら状態を保持し、それを用いて特徴量を作成するような処理をブロックで実装します。なお、使用した特徴量の接頭にCE_とつけた新特徴量になる実装となってます。
前述のCountEncodingをおこないます。またこのとき、train,testの全体を使う必要があるので、ついでにtrain,testを結合して読み込むread_whole_df関数も実装します。
まずは前述のようにAbstractBaseBlockclassを継承します。今回はCountEncodingなので、変換したい列名をattributeとして持っておき(__init__)、fitでラベルの出現回数をそれぞれカウントしその値(状態)をattributeに保持し、transformでCountEncodingを適応したいDF(input_df : train_df or test_df)に対して、保持した結果を用いて**CountEncodingをおこないます。
なお、fitでは返り値にtransformの結果が返ってくるのでfit_transformの方がわかりやすい気がしなくもない。
def read_whole_df(): return pd.concat([ read_csv('train'), read_csv('test') ], ignore_index=True) class CountEncodingBlock(AbstractBaseBlock): """CountEncodingを行なう block""" def __init__(self, column: str): self.column = column def fit(self, input_df, y=None): # vc = input_df[self.column].value_counts() master_df = read_whole_df() vc = master_df[self.column].value_counts() self.count_ = vc return self.transform(input_df) def transform(self, input_df): out_df = pd.DataFrame() out_df[self.column] = input_df[self.column].map(self.count_) return out_df.add_prefix('CE_')
これでCountEncoding処理をおこなうブロックが作成されました。
内部状態更新が行われないブロック例・StringLength
次に、 内部状態の更新がされないブロックを作成していきます。
ここでは入力される元のデータをそのまま加工するような処理をブロックで実装します。 そのまま加工で何かしらの内部状態を更新して保持する必要はないのでfit関数はオーバーロードする必要はありません。
記事中の例では文字数をカウントする処理StringLengthBlockを実装しています。なお、使用した特徴量の接頭にStringLength_とつけた新特徴量になる実装となってます。
class StringLengthBlock(AbstractBaseBlock): def __init__(self, column): self.column = column def transform(self, input_df): out_df = pd.DataFrame() out_df[self.column] = input_df[self.column].str.len() return out_df.add_prefix('StringLength_')
各特徴量処理ブロックをまとめて処理
内部状態を更新するCountEncodingBlock、内部状態を更新しないStringLengthBlockの2ブロックを走らせるためのrun_blocks関数を定義します。
まずはどのブロックをどう使用するかをfeature_blocksとして定義します。
feature_blocks = [
*[CountEncodingBlock(c) for c in ['art_series_id', 'title', 'description', 'long_title',
'principal_maker', 'principal_or_first_maker', 'sub_title',
'copyright_holder', 'more_title', 'acquisition_method',
'acquisition_date', 'acquisition_credit_line', 'dating_presenting_date',
'dating_sorting_date', 'dating_period', 'dating_year_early',
'dating_year_late',]],
*[StringLengthBlock(c) for c in [
'title', 'description', 'long_title',
'principal_maker', 'principal_or_first_maker', 'sub_title',
]]
]
ここでは、各ブロックとそのブロックに使用したい特徴量を組み合わせて記載してます。
ちなみに、この[*[counter for counter in iterator]]という表現は
- リスト内表記
*演算子によるunpacking
の組み合わせです。
リスト内表記は [counter for counter in iterator] の形でfor loopが実行されます。コード中のここのみ抜き取ると以下のような結果になります。
また、*演算子はiterator(タプル、リスト、セット)の中身をバラすことができます。つまり、ここでは*なしだと各ブロック数の多次元配列になるので*を用いることで1次元配列にしています。
そのため、このような書き方をすることで全ブロック処理から生成されたclassオブジェクトを1次元配列に格納しています。
次に、この各classオブジェクトのリストが格納されたfeature_blocksを用いて各classオブジェクト実際に走らせるrun_blocksについて。
def run_blocks(input_df, blocks, y=None, test=False): out_df = pd.DataFrame() print(decorate('start run blocks...')) with Timer(prefix='run test={}'.format(test)): for block in feature_blocks: with Timer(prefix='\t- {}'.format(str(block))): if not test: out_i = block.fit(input_df, y=y) else: out_i = block.transform(input_df) assert len(input_df) == len(out_i), block name = block.__class__.__name__ out_df = pd.concat([out_df, out_i.add_suffix(f'@{name}')], axis=1) return out_df
ここは
- 各オブジェクト処理を処理時間付きで出力
- testデータかどうかによって処理を変える
- おかしなことになってないかassertされる
の3点がおこなわれています。
特徴量処理って結構しくっていることが多いので1,3点目がすごく大事だと思ってます。
2点目のtestはここではtrainデータに対して処理したい場合は各ブロックにある共通関数fitだけをおこない、testデータに対して処理したい場合はtransformのみをおこないます。正確には、fit関数の返り値がtransformで処理した内容なので、trainデータではfitとtransformを、testデータではtransformだけおこなっています。
つまり、trainデータでは各クラスオブジェクトの状態を更新(作成)をする必要があるのでfitを走らせ、testデータは状態の更新をする必要がないのでtransformだけを走らせればよいという仕様になります。
逆に、これがないと冒頭に書いたようにtrainでもtestでも2回同じ計算をすることになって計算の無駄が生じます。
なお、当たり前ですがtestデータの前には状態の更新(作成)の必要があるのでtrainを先に走らせないとエラーになります。
run_blocks(train_df, blocks=feature_blocks) run_blocks(test_df, blocks=feature_blocks, test=True) # => ★★★★★★★★★★★★★★★★★★★★ start run blocks... ★★★★★★★★★★★★★★★★★★★★ - <__main__.CountEncodingBlock object at 0x7fb981308e80> 0.032[s] - <__main__.CountEncodingBlock object at 0x7fb981308978> 0.037[s] - <__main__.CountEncodingBlock object at 0x7fb981308f98> 0.035[s] - <__main__.CountEncodingBlock object at 0x7fb98132ef28> 0.030[s] - <__main__.CountEncodingBlock object at 0x7fb98132e1d0> 0.018[s] - <__main__.CountEncodingBlock object at 0x7fb98132e748> 0.020[s] - <__main__.CountEncodingBlock object at 0x7fb98132eb70> 0.030[s] - <__main__.CountEncodingBlock object at 0x7fb98132e278> 0.019[s] - <__main__.CountEncodingBlock object at 0x7fb98132efd0> 0.027[s] - <__main__.CountEncodingBlock object at 0x7fb98132e908> 0.015[s] - <__main__.CountEncodingBlock object at 0x7fb98132e6a0> 0.019[s] - <__main__.CountEncodingBlock object at 0x7fb98132e9b0> 0.017[s] - <__main__.CountEncodingBlock object at 0x7fb98132edd8> 0.021[s] - <__main__.CountEncodingBlock object at 0x7fb98132e4e0> 0.014[s] - <__main__.CountEncodingBlock object at 0x7fb9514c29b0> 0.016[s] - <__main__.CountEncodingBlock object at 0x7fb9514c2dd8> 0.014[s] - <__main__.CountEncodingBlock object at 0x7fb99184c6a0> 0.013[s] - <__main__.StringLengthBlock object at 0x7fb99184c5f8> 0.007[s] - <__main__.StringLengthBlock object at 0x7fb9915f4780> 0.007[s] - <__main__.StringLengthBlock object at 0x7fb9915f46d8> 0.008[s] - <__main__.StringLengthBlock object at 0x7fb9915f44e0> 0.008[s] - <__main__.StringLengthBlock object at 0x7fb99180a400> 0.007[s] - <__main__.StringLengthBlock object at 0x7fb9812de8d0> 0.006[s] run test=False 0.502[s] ★★★★★★★★★★★★★★★★★★★★ start run blocks... ★★★★★★★★★★★★★★★★★★★★ - <__main__.CountEncodingBlock object at 0x7fb981308e80> 0.005[s] - <__main__.CountEncodingBlock object at 0x7fb981308978> 0.006[s] - <__main__.CountEncodingBlock object at 0x7fb981308f98> 0.005[s] - <__main__.CountEncodingBlock object at 0x7fb98132ef28> 0.005[s] - <__main__.CountEncodingBlock object at 0x7fb98132e1d0> 0.004[s] - <__main__.CountEncodingBlock object at 0x7fb98132e748> 0.004[s] - <__main__.CountEncodingBlock object at 0x7fb98132eb70> 0.005[s] - <__main__.CountEncodingBlock object at 0x7fb98132e278> 0.005[s] - <__main__.CountEncodingBlock object at 0x7fb98132efd0> 0.005[s] - <__main__.CountEncodingBlock object at 0x7fb98132e908> 0.004[s] - <__main__.CountEncodingBlock object at 0x7fb98132e6a0> 0.004[s] - <__main__.CountEncodingBlock object at 0x7fb98132e9b0> 0.004[s] - <__main__.CountEncodingBlock object at 0x7fb98132edd8> 0.004[s] - <__main__.CountEncodingBlock object at 0x7fb98132e4e0> 0.003[s] - <__main__.CountEncodingBlock object at 0x7fb9514c29b0> 0.003[s] - <__main__.CountEncodingBlock object at 0x7fb9514c2dd8> 0.003[s] - <__main__.CountEncodingBlock object at 0x7fb99184c6a0> 0.003[s] - <__main__.StringLengthBlock object at 0x7fb99184c5f8> 0.006[s] - <__main__.StringLengthBlock object at 0x7fb9915f4780> 0.007[s] - <__main__.StringLengthBlock object at 0x7fb9915f46d8> 0.007[s] - <__main__.StringLengthBlock object at 0x7fb9915f44e0> 0.006[s] - <__main__.StringLengthBlock object at 0x7fb99180a400> 0.007[s] - <__main__.StringLengthBlock object at 0x7fb9812de8d0> 0.007[s] run test=True 0.183[s]
3点目のassertはここではinputとoutputの行数が一致しない(つまり、処理した結果データ数が増減した)場合assertされるようになります。
で、1点目で処理しているclassオブジェクトが書かれるのでどこでしくっているかとか、処理のボトルネックがどこかがわかる出力となっています。
なお、run_blocksの結果特徴量処理をして作成された新規の列がDFとして返ってきます。
内部状態更新が行われる例2:tf-idf
記事より参照。
tf-idfでテキスト特徴量をベクトル化しSVDで次元圧縮をする。
具体的には、fitでinputされたDFの指定テキスト特徴量に対して前処理(text_normalization関数)およびベクトル化(tf-idf→SVD)をおこなってその状態を記憶する。そして、transformでその記憶された状態を用いて特徴量を作成する。
import texthero as hero from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.decomposition import TruncatedSVD from sklearn.pipeline import Pipeline def text_normalization(text): # 英語とオランダ語を stopword として指定 custom_stopwords = nltk.corpus.stopwords.words('dutch') + nltk.corpus.stopwords.words('english') # 表記ゆれなどを前処理 x = hero.clean(text, pipeline=[ hero.preprocessing.fillna, hero.preprocessing.lowercase, hero.preprocessing.remove_digits, hero.preprocessing.remove_punctuation, hero.preprocessing.remove_diacritics, lambda x: hero.preprocessing.remove_stopwords(x, stopwords=custom_stopwords) ]) return x class TfidfBlock(AbstractBaseBlock): """tfidf x SVD による圧縮を行なう block""" def __init__(self, column: str): """ args: column: str 変換対象のカラム名 """ self.column = column def preprocess(self, input_df): x = text_normalization(input_df[self.column]) return x def get_master(self, input_df): """tdidfを計算するための全体集合を返す. デフォルトでは fit でわたされた dataframe を使うが, もっと別のデータを使うのも考えられる.""" return input_df def fit(self, input_df, y=None): master_df = self.get_master(input_df) text = self.preprocess(input_df) self.pileline_ = Pipeline([ ('tfidf', TfidfVectorizer(max_features=10000)), ('svd', TruncatedSVD(n_components=50)), ]) self.pileline_.fit(text) # sklearn.pipelineのfit return self.transform(input_df) def transform(self, input_df): text = self.preprocess(input_df) z = self.pileline_.transform(text) out_df = pd.DataFrame(z) return out_df.add_prefix(f'{self.column}_tfidf_')
内部状態更新が行われる例3:NAを全体の平均値で穴埋め
例用に自作。
NAをを全体の平均値で埋める。
fitで全体の平均値を状態に保存し、tranformではそれを使ってfillnaをおこなう。
class FiillAvgBlock(AbstractBaseBlock): """tfidf x SVD による圧縮を行なう block""" def __init__(self, column: int): """ args: column: str 変換対象のカラム名 """ self.column = column def fit(self, input_df, y=None): master_df = read_whole_df() self._avg = master_df[self.column].mean() return self.transform(input_df) def transform(self, input_df): out_df = pd.DataFrame() out_df[self.column] = input_df[self.column].fillna(self._avg, inplace=False) # 平均値 return out_df.add_prefix('FillAvg_')
内部状態更新が行われない例1:特徴量の組み合わせ演算
例用に自作。
数値特徴量2つを足し合わせるブロックを作る。
class FeatureAddingBlock(AbstractBaseBlock): """数値特徴量2つを足し合わせる block""" def __init__(self, column1: int, column2: int): self.column1 = column1 self.column2 = column2 def transform(self, input_df): out_df = pd.DataFrame() adding = input_df[self.column1] + input_df[self.column2] out_df[self.column1 + '+' + self.column2] = adding return out_df.add_prefix('Adding_')
データで例示するのに良い列がないので、特に意味がない特にとなるが、dating_periodとdating_year_lateの和、dating_periodとdating_year_earlyの和の2特徴量を作る。
2列を渡す必要があるのでfeature_blocksではzipを用いて以下のように渡す(ミスが増えそうな渡し方なので他になにかいい渡し方ありそう。いっそ1listの全順列組み合わせをitertools.permutationsで作ったがいいかも?)。
feature_blocks = [
*[FeatureAddingBlock(i, t) for i, t in zip(['dating_period', 'dating_period'],['dating_year_late', 'dating_year_early'])]
]
run_blocks(train_df, blocks=feature_blocks)
内部状態更新が行われない例2:(log系データに対して)前のレコードとの時系列差分
例用に自作。
(log系データに対して)前のレコードとの時系列差分を取る。
class DiffLagBlock(AbstractBaseBlock): """principal_maker視点での前のレコードとの時系列(dating_sorting_date)差分 block""" def __init__(self, column: int): self.column = column def transform(self, input_df): out_df = pd.DataFrame() copied_input_df = train_df.copy() sorted_grouped_input_data = train_df.sort_values(['principal_maker','dating_sorting_date']).groupby('principal_maker') lag = sorted_grouped_input_data.shift(1) lag = lag.rename(columns=lambda x: 'lag_' + x) joined_df = copied_input_df.join(lag['lag_' + self.column])# lagは時系列ソートされてるのでindex結合 out_df[self.column] = joined_df[self.column] - joined_df['lag_' + self.column] return out_df.add_prefix('DiffLag_') feature_blocks = [ *[DiffLagBlock(c) for c in ['dating_year_late']] ] run_blocks(train_df, blocks=feature_blocks)
その他所感
はじめに書いたように、特徴量処理を各ブロックに分けるので可読性も高いし、色々と特徴量用ブロックの引数をいじるなどの試行錯誤がしやすい。また、assertも仕込みやすそう。そのため、この形式で書けそうなら極力書くようにしたい。
一方で、前述の特徴量の和を作るような引数を2つ渡して何かするみたいな処理だと引数の渡し方を工夫しないと可読性が落ちたりとか、ブロックで作った特徴量に更になにかするブロックを作りたかったら、前ブロックで特徴量名が自動生成される関係で次ブロックの引数の指定がちゃんと把握しておかないとやりづらそう(一括でいいならdf.columns.str.contains('XX_')とか使ってするとか?)だったり、処理によってはやりづらそうな場合もありそう。
その場合は無理にこのフレームでやるのではなく、それぞれ別立てで作ればいいのかなーと思う。