Stanのmodelブロックの意味
Stanを書くとき、モデル式を書いてそれをコードに落とし込むという流れで書いている。感覚的にコードを書いているのだが、冷静に振り返ると何故ここにこれを書くのか?ということがわからなくなってきたのでメモ。
というか、前の記事みたいにエラーが出た際に「データが複雑すぎるから初期値で条件を縛る必要性が出た」という判断をしましたが、「そもそもこの書き方であっているのか? = 意図しない意味わからんモデルになっているから初期値問題が出るのでは?」という疑問もあってちゃんと理解しないとな、と思いました。
具体的には、「modelパラメータにif文である条件のときは0・・・というのできないからnormal(0,0)で実質的に0にするかー」とかいう処理をしたけど明らか問題あるよなこれ。って思ったからです。
サンプルコードおよび解釈として、Logic of Blueさんの以下の記事を参考に使用させてもらいます。
(どうでもいいのですが、Logic of Blue管理人さんのサイトや書籍はいつも勉強になっているのですが、私の出身高校の1つ下の学年ということを最近知って驚いた)
Stanによるベイズ推定の基礎 | Logics of Blue
data {
int n;
vector[n] Nile;
}
parameters {
real mu; # 確定的レベル(データの平均値)
real<lower=0> sigmaV; # 観測誤差の大きさ
}
model {
for(i in 1:n) {
Nile[i] ~ normal(mu, sqrt(sigmaV));
}
}
このStanコードのうちModelブロックで書いているNile[i] ~ normal(mu, sqrt(sigmaV))が何なのかが今回の疑問点です。
まずベイズの定義を考えます。
それぞれ分解すると、
は、データXが得られたときにパラメータθが従う確率分布。いわゆる 事後分布 。MCMCサンプリングによって得られる確率分布。・・・(1)
は、パラメータθのある値が得られたときにデータXが観測される確率。要するにパラメータθの尤度L(θ)
は、データXが従う確率分布。いわゆる 事前分布
は、Xが得られる確率で定数。
つまり、以下のように書き換えることができる。
また、コード中の表記に合わせると以下のようになる。
このときのf(ナイル川データ | mu, sigmaV)、「あるmu, sigmaV(未知)のときのナイル川のデータ(実データ)」というのがコードのNile[i] ~ normal(mu, sqrt(sigmaV))に相当する。
ナイル川データは実データなので、「mu,sigmaVを動かしたときにどういう値ならば実データのナイル川データが得られるか」という尤度関数を得ることができる。このときの尤度を求める計算としてnormal(正規分布)を用いる、というのがこのModelブロックに記載されているNile[i] ~ normal(mu, sqrt(sigmaV))の意味。
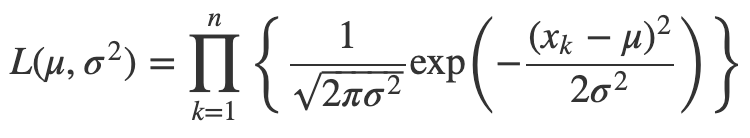
そして、Modelブロックで尤度の指定がされ、Parametersブロックで事前分布の指定がされたことでベイズの定理よりパラメータの事後分布を推定することができる。
言い方を換えると、「Modelブロックで確率モデルを記載するとその確率モデルに従う尤度関数を通すことで、確率モデルに用いたパラメータがMCMCによりベイズ推定される」「Nile[i] ~ normal(mu, sqrt(sigmaV))に従うmu, sigmaVをMCMCで推定する」
階層ベイズなどで例えばNile[i] ~ normal(mu[i], sqrt(sigmaV))、mu[i] ~ normal(mu_avg, sqrt(sigmaV))のようになっている場合、「mu,sigmaVを動かしたときにどういう値ならば 実データ のNileデータが得られるか」となるが、ここのmuはベイズ推定なので一意な値ではないためmu[i] ~ normal(mu_avg, sqrt(sigmaV))の「mu_avg,sigmaVを動かしたときにどういう値ならば ベイズ推定値(一意でない) のmuが得られるか」となる気がするが全組み合わせについてやってるのだろうか。謎だ。
はじめの話
はじめに書いた「modelパラメータにif文である条件のときは0(Sales ~ ... ではなく、Sales = 0)・・・というのできないからnormal(0,0)で実質的に0にするかー」とかいう処理の話。
modelブロックの意味を考えると、そもそもnormal(0,0)ってなんも推定してないやんけということがわかるし、尤度関数もそもそも1点に定まるっていう。それが原因でエラーになっているのかどうかはわからんが、少なくともModelブロックに書くのはおかしい気がする。
ただ、そうなると閉店フラグが0のとき値が一意(0)になるようなモデルはどう作れば。。。欠損値処理のように、そこだけ値を除去してあとで0で埋めるとかか?そもそもある条件のときだけ別のモデルに従うような場合ってどう書けばいいのだろう。
参考
http://rtokei.tech/stan/bayesian-inference-with-stan-005/
")
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者:久保 拓弥
- 発売日: 2012/05/19
- メディア: 単行本
Stanで統計モデリングを学ぶ(2): そもそもMCMCって何だったっけ? - 渋谷駅前で働くデータサイエンティストのブログ
P.48あたりから。
Stan勉強会資料(前編) from daiki hojo
www.slideshare.net