BUSINESS DATA SCIENCE 1章 Uncertainty① ブートストラップ法
BUSINESS DATA SCIENCEという本を最近読んでいるので内容を自分なりにまとめる。

最近「ビジネスデータサイエンスの教科書」という邦題で日本語版も出たみたいです

- 作者:マット・タディ
- 発売日: 2020/07/22
- メディア: 単行本
この章はなにか
ビジネスをはじめとした実世界はノイズを多く含んでいるのでノイズを考慮したモデルを作成する必要がある。
この章では、ノイズに対して統計的手法で不確実性を扱うことによって対処する方法を提供している。
データなどは作者のgitにある。
この節はなにか
データの不確実性を考える際に、古典的な手法で母集団の確率分布を求めることができない場合に役に立つブートストラップについて説明する。
頻度主義的な不確実性へのアプローチ
以下のような、web閲覧履歴データを考える。
library(tidyverse) data = read_csv('examples/web-browsers.csv') data # A tibble: 10,000 x 7 # id anychildren broadband hispanic race region spend # <dbl> <dbl> <dbl> <dbl> <chr> <chr> <dbl> # 1 1 0 1 0 white MW 424 # 2 2 1 1 0 white MW 2335 # 3 3 1 1 0 white MW 279 # 4 4 0 1 0 white MW 829 # 5 5 0 1 0 white S 221 # 6 6 0 1 0 white MW 2305 # 7 7 1 1 0 white S 18 # 8 8 1 1 0 asian MW 5609 # 9 9 0 1 0 white W 2313 # 10 10 1 1 0 white NE 185
近似確率分布
閲覧時間は以下のような分布になる。
data %>% ggplot() + geom_histogram(aes(x=log(spend)))

データ数は10,000あるので上記閲覧時間のグラフは中心極限定理より、以下のような正規分布で近似することができる。
mean(data$spend) # 1946.439 sqrt(var(data$spend)/10000) # 80.3861 curve(dnorm(x, 1946.439, sqrt(6461.925)), 1500, 2300)

同様のデータ生成過程であれば中心極限定理を背景として、母集団の分布を正規分布から求めることができる。そのため、この先新しいデータが手に入った場合も同様の母集団の正規分布から生成されると考えることができる。確率分布が求まることで、データがどういう挙動をするか(平均や分散など)という不確実性を把握することができる。
ブートストラップ(ノンパラメトリックブートストラップ)
母集団の確率分布を仮定してデータの分布を求めることができたが、ビジネスにおいては確率分布が複雑なので前述のようなアプローチは難しい。また、前述の方法は中心極限定理を前提としているので多くのサンプル数が必要となるがその点においてもビジネスにおいて難しい場合が多々ある。
つまり、ビジネスにおいて前述のアプローチは難しい。このような点において、母集団に関して確率分布などの仮定を置かなくても使えるブートストラップ法を用いることで確率分布を求めることができる。
統計量
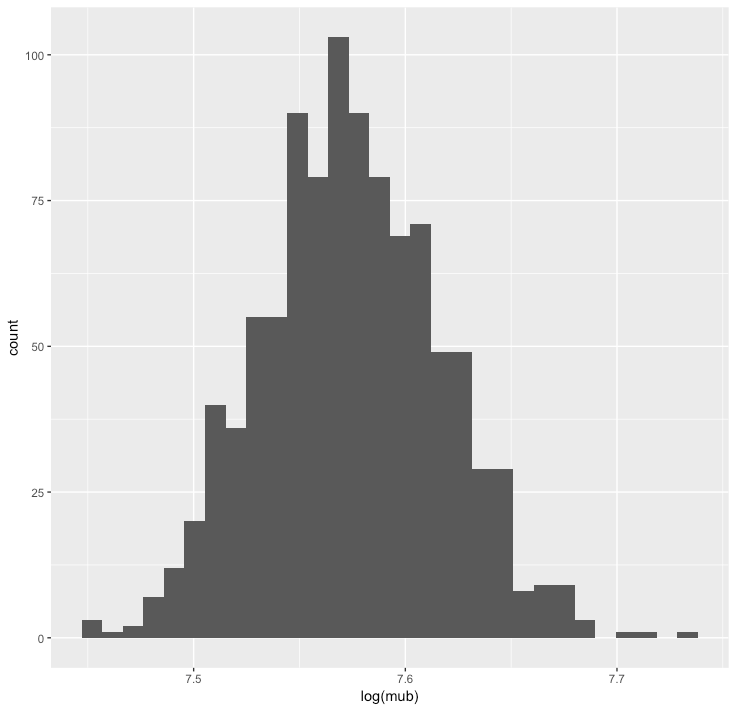
以下でブートストラップによって求めたデータの分布を見てみると、先程近似で求めた正規分布と似た確率分布を求めることができた。また、期待値や分散も近い値となっている。
そのため、確率分布の仮定や多数のサンプル数がなくても、ブートストラップによって確率分布を求めることができるし、ひいては平均や分散も求めることができる。
つまり、ブートストラップを用いると、標本集団からリサンプリングして得られた複数の標本集団それぞれで統計量を求めることで、母集団の統計量を近似することができる。
B = 1000 mub = c() for (b in 1:B){ samp_b = sample.int(nrow(data), replace = TRUE) mub = c(mub, mean(data$spend[samp_b])) } sd(mub) ggplot() + geom_histogram(aes(x=log(mub))) mean((mub)) # 1949.703 sd(mub) # 82.92851
回帰係数
リサンプリングした標本集団それぞれでOLS(最小二乗法)をしてできたパラメータ(係数)を考える。
まずは、 log(spend) ~ broadband + anychildren となる回帰式を考える。これはOLSなので、中心極限定理をもとにした正規分布を仮定している。
linreg = glm(log(spend) ~ broadband + anychildren, data=data) summary(linreg) # Call: # glm(formula = log(spend) ~ broadband + anychildren, data = data) # # Deviance Residuals: # Min 1Q Median 3Q Max # -6.2379 -1.0787 0.0349 1.1292 6.5825 # # Coefficients: # Estimate Std. Error t value Pr(>|t|) # (Intercept) 5.68508 0.04403 129.119 <2e-16 *** # broadband 0.55285 0.04357 12.689 <2e-16 *** # anychildren 0.08216 0.03380 2.431 0.0151 * # --- # Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 # # (Dispersion parameter for gaussian family taken to be 2.737459) # # Null deviance: 27828 on 9999 degrees of freedom # Residual deviance: 27366 on 9997 degrees of freedom # AIC: 38454 # # Number of Fisher Scoring iterations: 2
次に、ブートストラップサンプルを用いて同様のことをおこなう。
B = 1000 betas = c() for (b in 1:B){ samp_b = sample.int(nrow(data), replace = TRUE) reg_b = glm(log(spend) ~ broadband + anychildren, data=data[samp_b,]) betas = rbind(betas, coef(reg_b)) } betas[1:5,] # (Intercept) broadband anychildren # [1,] 5.683390 0.5761392 0.03951637 # [2,] 5.658696 0.6170085 0.07074808 # [3,] 5.633866 0.5948859 0.09141631 # [4,] 5.715080 0.5293904 0.06294676 # [5,] 5.717246 0.5633066 0.04256508
このときの broadband はOLSでの結果に非常に近くなる。
ノンパラメトリックブートストラップが使えない場合
外れ値を含む標本集団の場合も外れ値が複数サンプリングされることで分布が歪むので上手くいかない。
また、中央値や分散のような、1次元についての計算値であれば上手くいくことが多いが、共分散のような2次元以上の計算値において次元が増えるほど上手くいかないことが多くなる。
パラメトリックブートストラップ
ノンパラメトリックブートストラップが使えない場合、パラメトリックブートストラップを使う。
ノンパラメトリックブートストラップでは、観測された標本集団から復元抽出したデータから確率分布を仮定している(経験分布)。
一方で、パラメトリックブートストラップでは、事前に確率分布を仮定し、その確率分布から復元抽出をおこない、統計量などを求める。
xbar = mean(data$spend) sig2 = var(data$spend) B = 10000 mub = c() for (b in 1:B){ xsamp = rnorm(10000, xbar, sqrt(sig2)) mub = c(mub, mean(xsamp)) } sd(mub) # 80.40126 sqrt(sig2/10000) # 80.3861
これは非常に良い値となっているが、前述のように確率分布の仮定が必要となるのでノンパラメトリックブートストラップが使えないシチュエーションのときに限ってのみ使うほうが良い。
バイアスを考慮したブートストラップ
ブートストラップによって求めた値にもバイアスは生じている。そのため、ブートストラップ推定値自体の信頼区間を求める必要がある。
以下で、先程まで使っていた data を母集団として、標準誤差が8%ポイントほどのバイアスがあるデータ smallsamp を考えることで、そのバイアス除去した母集団の信頼区間を求める手法をおこなう。
smallsamp = data$spend[sample.int(nrow(data), 100)] # 母集団dataから100個抽出した標本集団を1つ作成する s = sd(smallsamp) # 標本sd 8726.177 sd(data$spend) # 8038.61 母集団sd s/sd(data$spend) # 1.085533 8%ポイントほどのバイアスがある B = 10000 e_b = c() # ブートストラップ差分 for (b in 1:B){ sample_b = smallsamp[sample.int(100, replace = TRUE)] # 標本集団を復元中出 sd_b = sd(sample_b) # ブートストラップサンプルのsd e_b = c(e_b, sd_b - s) # 標本集団とのブートストラップ差分 } mean(e_b) # -961.302 # 標本集団とのブートストラップ差分平均(≒バイアス平均) mean(s - e_b) # 9687.479 # 標本集団のsdからブートストラップ差分平均を引く(バイアスを除去) sd(data$spend) # 8038.61 母集団のsd tvals = quantile(e_b, c(0.05, 0.95)) # 5% 95% # -6851.111 5393.346 s - tvals[1:2] # 95%CI # 5% 95% # 15577.288 3332.831
参考
統計量のバラツキを知るためのブートストラップ法基礎 with R - Qiita
www.slideshare.net