Shapashで機械学習モデルの挙動を可視化する
記事の目的
前回の記事ではShapashと同様に機械学習モデルの挙動を楽に可視化するEvidentlyを紹介した。
記事中でShapashについても軽く触れたが使用用途としては以下のような違いがある。
Evidentlyはモデルの振る舞いを、推定元データ観点でどうなっているかを中心として可視化し、それに付随してモデル/推定元データの比較をします。
ShapashはSHAPおよびLIMEを用いて、モデルにおける特徴量の寄与がどうなっているか、つまりモデルが何故そういう振る舞いをしているかを中心として可視化している。つまり、前者はモデルの挙動をデータから確認する用途で、後者はモデルの推定結果の原因を確認する用途なので用途が異なっている(データを中心に見ていくか、結果を中心に見ていくか、とも言える)。
また、Evidentlyはデータを中心に確認するので『モデルアルゴリズムによるデータ内(特徴量毎など)での精度差異』『推定元データの違い(異なる地域や時期など)による精度差異』を見たい場合に役に立つため予測データを2つ渡し比較する機能を持っている。
このように、モデルが何故そういう振る舞いをしているか把握できるShapashについて記載する。
なお、概要は以下の記事が端的にまとまっているので、追加で調べたことを中心に記載していく。
何が表示できるか
ShapashはEvidently同様に、ダッシュボードをhtml出力する形式と、見たい項目(グラフ)を個別に指定して出力する2つの出力形式に分かれる。
前者はいくつかのグラフ項目が一画面で表示されているので、各項目の一部を選択するとその選択に連動して他の項目の表示が変わる。後者には個別でグラフ項目を出力するので、あるインスタンスに対しての挙動を見たい場合は出力時に指定が必要になる一方で、前者に含まれていない項目も出力することができる。
また、モデルやデータの要約量なども併せてレポートとして出力をすることもできる。
データ準備
Evidentlyのときに作成したモデルをそのまま使う。具体的には、IBMの従業員退職予測予想データを使った以下のNotebookのIn [34](データの前処理およびRandomForestモデルの学習)まで。
そのため以下でおこなう可視化は分類モデルについての可視化になるが、連続値への予測でもほぼ同様の解釈ができるので確率値/ラベルは連続値として置き換えて読んでください。
出力準備
ダッシュボードやレポート、解釈用の個別グラフなりを出力する前にSmartExplainerを用いて、出力の型となるインスタンス(xplオブジェクト)を作成する。この際、目的変数のラベルをオプションで指定する。
from shapash.explainer.smart_explainer import SmartExplainer response_dict = {0: 'no', 1:'yes'} xpl = SmartExplainer( label_dict=response_dict # 結果ラベルを指定 )
作成したインスタンスに対して、解釈をしたいモデルと推定結果、推定に用いた特徴量を渡してコンパイルする。
test_probas = pd.DataFrame(rf.predict(test_data[features]),
columns=['pred'],
index=test_data.index)#.astype(int)
xpl.compile(
x=test_data[features],
model=rf,
y_pred=test_probas
)
以上で、挙動を出力するためのオブジェクトができたのであとはこのインスタンスにメソッドを使っていじっていく。
なお、このときのモデルはscikitlearn系であればTree系以外のモデルでも使えるっぽいです。内部的にはアルゴリズムに依存しない手法のShapだからまぁそうなんでしょうが、おそらくscikitlearn準拠モデルであれば、といった感じでしょうか(試してないので推測)。
ダッシュボードと個別出力
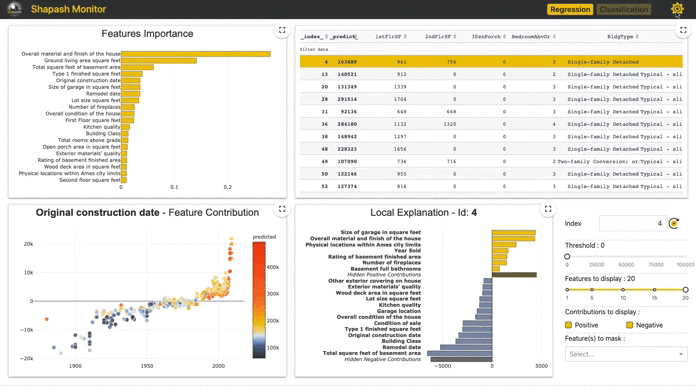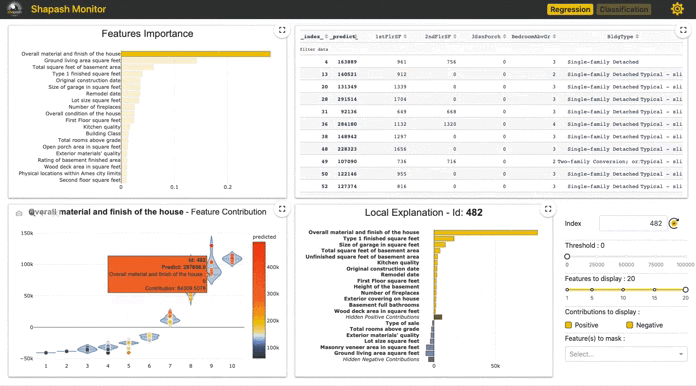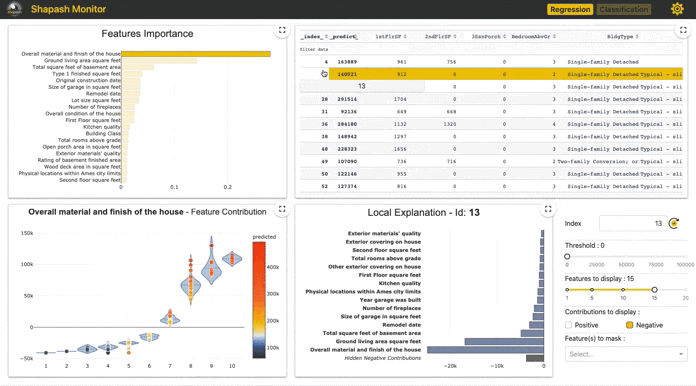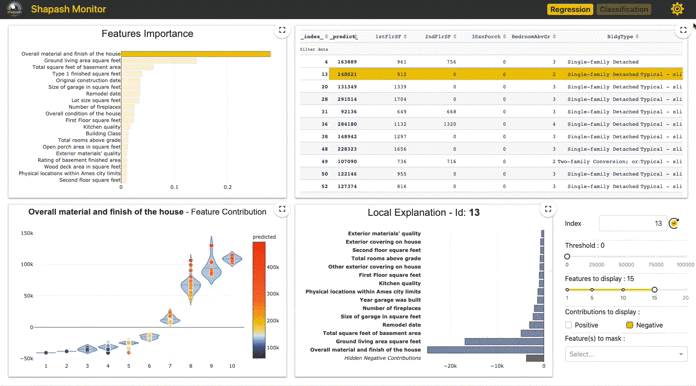
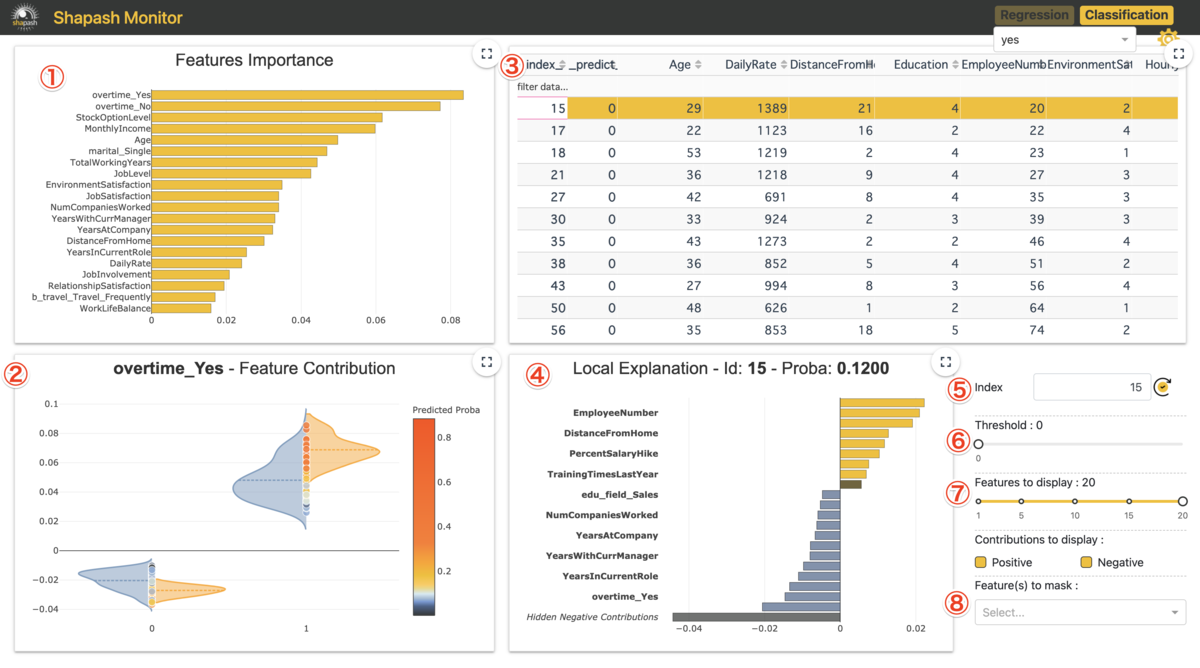
app = xpl.run_app() を走らせると Dash is running on http://0.0.0.0:8050/のような出力がされ、(port番号8050は人に依る)ローカルホストが立ち上がりダッシュボードが描写される。この http://0.0.0.0:8050/ に飛ぶと以下のように表示される(番号は説明用にこちらでつけた)。
なお雰囲気を知りたい場合は、公式のデモで実際に触れる。
また、以下のように各ダッシュボード要素+αを個別画像として出力することもできる。
①Feature Importance
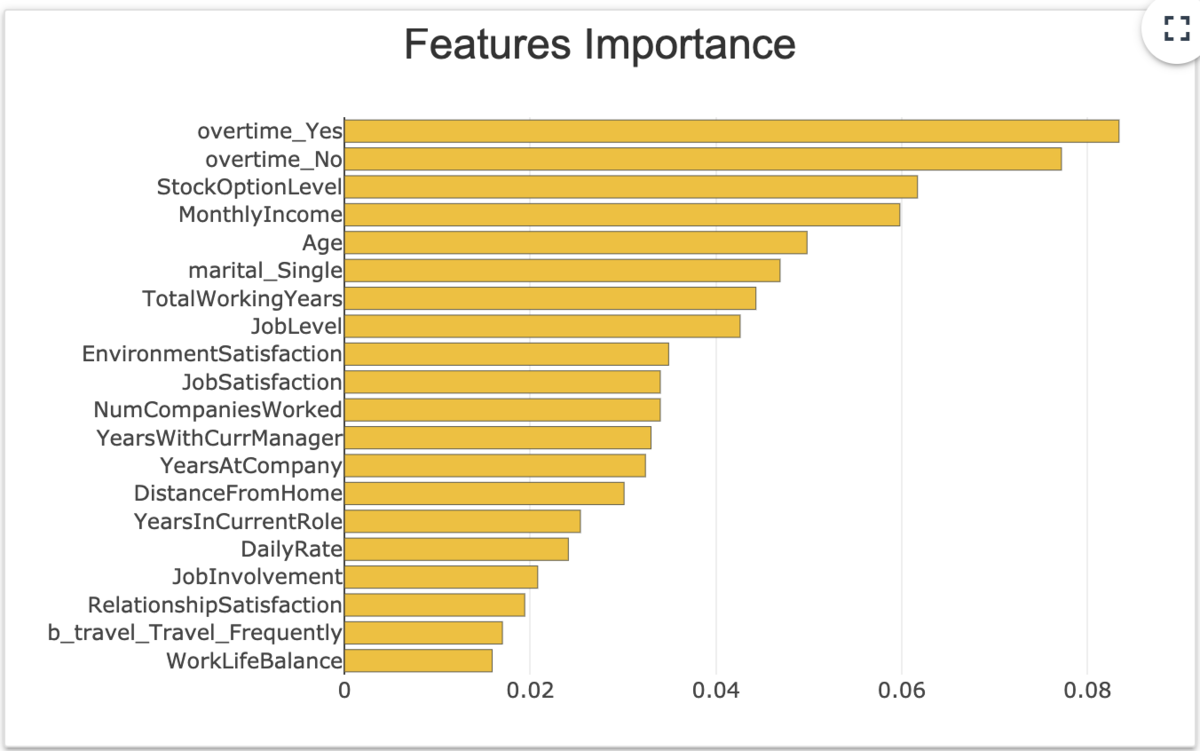
モデルにおける変数重要度を表示している。
以下で個別出力ができる。
xpl.plot.features_importance()
このとき、max_featuresで表示数の指定ができる。また、selectionで指定したidのインスタンスだけでの変数重要度を見ることができる。
ひとえに変数重要度といっても、例えばtree系であればGainベースやsplitベースなど色々な計算方法がある。
例えばLightGBMのlightgbm.plot_importanceだとimportance_typeオプションで指定ができる。
ここで表示されているのは後に紹介するShap valueの絶対値平均*1なのかなーって気がします。ドキュメント読んでも明言されてない((あえていうならFeatures importances sum and display the absolute contribution for one target modalityか?))ので断定できないですが、shapashはSHAPを中心に色々出してたり、モデル依存の重要度じゃなさそうだったり、ローカル指定ができたりということからも可能性としては高そう。
②Feature Contribution
①で選択された特徴量はマクロで見た各特徴量の重要値となります。一方ここでは、各インスタンス個別での特徴量の貢献がどうなっているかを全インスタンスに対して可視化がされます。なお、ここでの貢献度(Contribution)は実際の予測確率を分解した値となり、あるインスタンスに対して他の特徴量も含めて分解値を一覧表示したものが後に紹介する④となります。ここの図中の点は各インスタンスを表しており点をクリックするとそのインスタンスに対する④が表示されます。
このときカテゴリカル変数の場合はバイオリンプロットで可視化がされます。
なお、 xpl.compileの際にy_pred(予測確率)を渡しているか、addメソッドでy_predを追加で渡している場合にバイオリンは、青色はy_predが0.5未満、オレンジ色はy_predが0.5以上のインスタンスに分けてバイオリン表示が行われます。
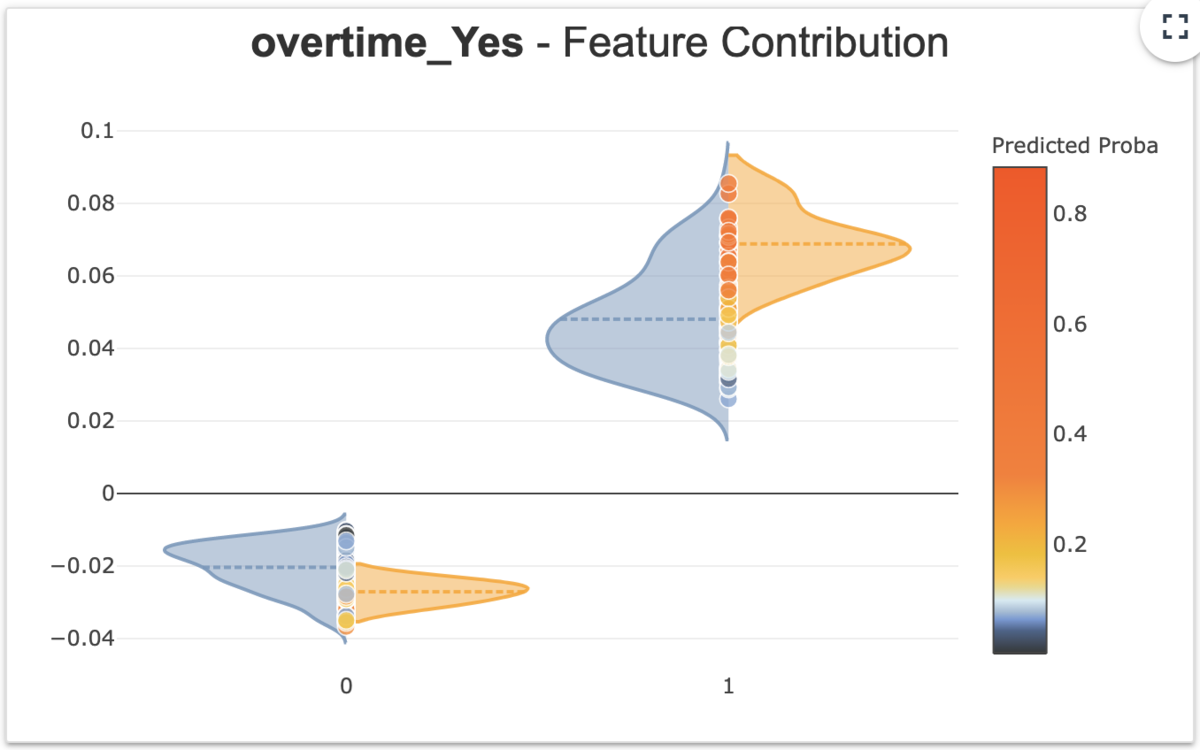
y_predを渡さない場合は全インスタンスの密度をまとめてバイオリンとして表示します。

まとめた方のバイオリンをみるとovertime(残業をしているか)が0と1で貢献に対して明確に差が出ています。
予測結果が1/0(オレンジ/青)毎に分けてみると、overtimeが1ではオレンジなほど貢献が高いが、青では幅広い分布となっています。
解釈としては、残業をしている人ほど在籍に対して正の貢献がありその中でも在籍している人ほどその傾向があります。つまり、(因果の向きは置いておくとして)残業をしている人は在籍している可能性が高くなり、残業していない人ほど離職をしていることになります。これはちょっとドメイン知識に照らし合わせると違和感があるのですが、例えば役職者だと在籍しやすくなるけど残業がある、みたいなことが反映されているのだろうか。。。
次に、連続値の場合は以下のように散布図で表示されます。

Ageは①をみると全体としては5番目に重要と出ていますが、この図をみると20代のインスタンスでは若年ほどAgeは予測への貢献が高く徐々に貢献が減っていき30歳になるにつれ貢献が0になっていく傾向がみれます。その後は40歳にかけてやや負の貢献が増加していき60歳に近づくほど再度貢献が0になっていく傾向がみれます。
実際予測対象の「会社に在籍しているか」をドメイン知識から考えると20代前半は多くの人は転職をせずその会社にいますが、30歳に近づくにつれ転職をする人が増える傾向にあると思われます。そのときに、新卒1,2年目では「まだ新卒1,2年目だから(23,24歳だから)転職をしない」といったことが機能しますが、30歳に近づくにつれ「様々な要因によって転職をするかどうか」を判断することになるように思えます。つまり、在籍しているかどうかは20歳前半では年齢を理由に在籍をするが、30歳に近づくにつれ年齢以外の様々な要因によって変わっていく(=年齢の在籍への貢献度が相対的に落ちる)ということになります。
これはあくまで私の「年齢に対する在籍へのドメイン知識」ですが、これと似たようなことが結果として図に表れています。
それぞれ個別で出す場合は以下
# カテゴリカル変数 # y_predあり xpl = SmartExplainer( label_dict=response_dict # 結果ラベルを指定 ) xpl.compile( x=test_data[features], model=rf, #y_pred=test_probas ) xpl.add(y_pred=test_probas) #addで渡してもいいし、compile時に指定してもよい xpl.plot.contribution_plot("overtime_Yes")

# カテゴリカル変数 # y_predなし xpl = SmartExplainer( label_dict=response_dict # 結果ラベルを指定 ) xpl.compile( x=test_data[features], model=rf, #y_pred=test_probas ) xpl.plot.contribution_plot("overtime_Yes")

# 連続値 xpl.plot.contribution_plot("Age")

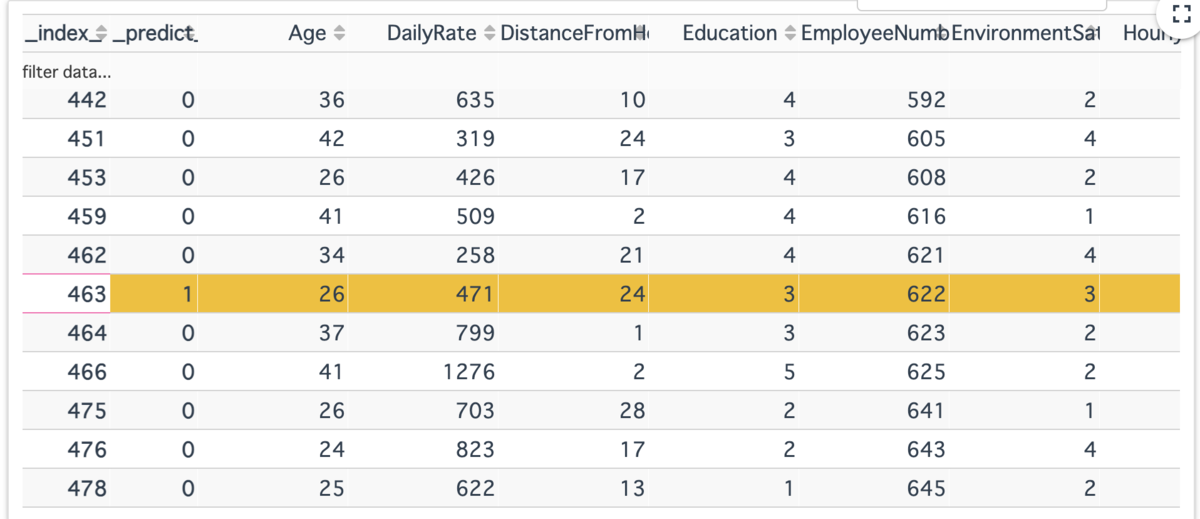
③実データテーブル
推定対象についての予測と特徴量がテーブルで表示されます(predictは閾値0.5で変換?)
ここであるインスタンスの行をクリックすると④でそのインスタンスについての予測値が分解された各特徴量の貢献度が表示されます。
④Local Plot
あるインスタンスに対しての予測確率を各特徴量で分解した値を貢献度として表示しています。 インスタンスの選択はm,②で点をクリック、③で行をクリック、⑤でid指定のいずれかで指定できます。
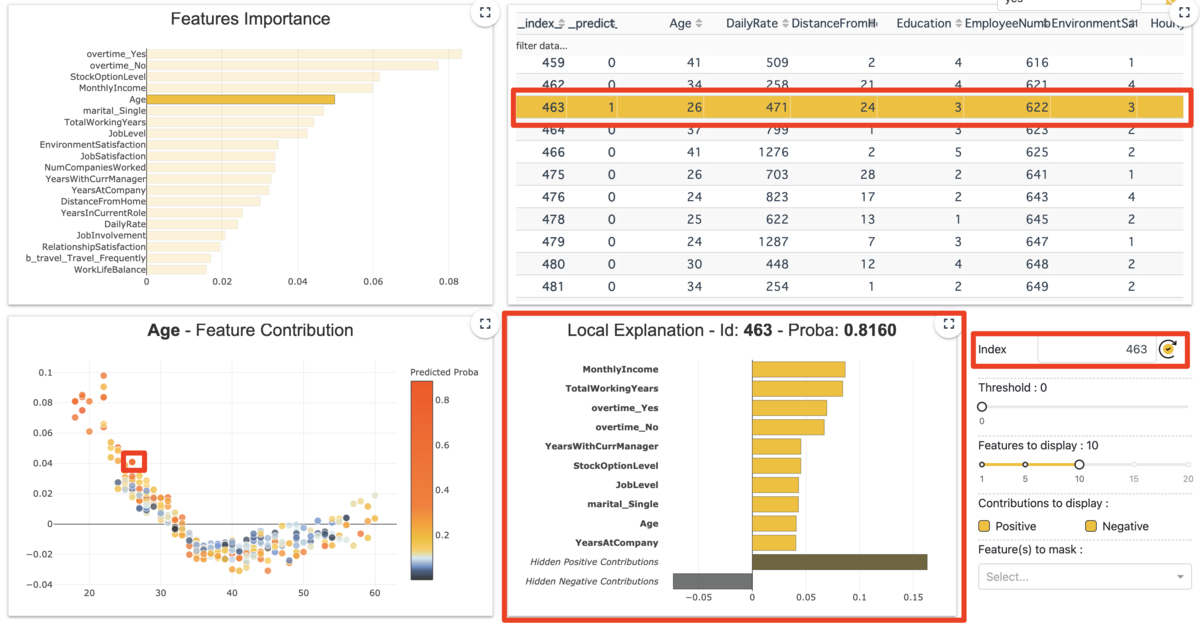
なお、ここでの貢献値は正の場合は「確率を高める」要素として、負の場合は「確率を低める」要素として解釈できます。
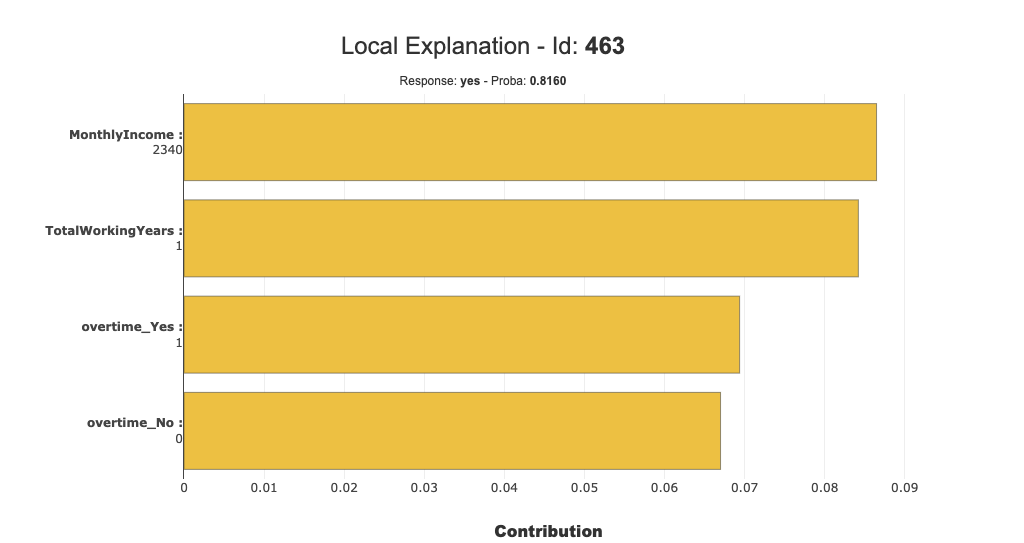
図中にあるID463インスタンスは予測確率は0.8160となり、その内訳がこの図となっています。つまり、この棒グラフの値を全て合算すると予測確率の0.8160となります。
この図の右にある⑤~⑧はこの図の制御に使います。
⑤は前述のようにidの指定、⑥は表示される寄与絶対値の最低値(分類タスクだと固定?)、⑧で指定した特徴量を表示から消せます。
なお、⑦で表示する特徴量数を制御でき、一定数にするために絶対値が低い特徴量は正負別にまとめて表示(値は総和)されます(Hidden Positive/Negative 。Contributions)。
このID463インスタンスではMontlyIncomeが最も正に貢献している特徴量となっているようです。
個別画像の場合以下。
xpl.plot.local_plot(index=463)
また、filterメソッドを使用して、⑤~⑧に相当する挙動をおこなうこともできる。max_contribで特徴量数、thresholdで表示値の閾値。一度filterを使うとlocal_plotは常にfilter後の状態になるようなので注意。
なお、表示数が少なくなるとそのインスタンスの実際の値が特徴量名の下に表示される模様。
xpl.filter(threshold=0.06, positive=True) xpl.plot.local_plot(index=463, show_masked=False)
Local Plotの今のxpl状態(filterをしている場合はfilter後の状態)で全インスタンスの情報をテーブルで欲しい場合はto_poandas
df = xpl.to_pandas(proba=True)
df.head()

ダッシュボードの停止
app.kill()でローカルホストを停止できる。
ダッシュボードで表示されてない個別のみ表示できるグラフ
Compare_plot
④Local Plotを複数インスタンスで比較したい場合compare_plotメソッドを使う。
xpl.plot.compare_plot(index=[688,422,630])

この例ではAgeがほぼ同じだがProbasが大きく異なるidを選んでいる。

id688(prob:0.88)とid630(prob:0.22)のみで比較してみると、例えばMonthlyIncomeはid688では大きく正に寄与だがid630では負に寄与となっていて(実際の値は前者は2121、後者は4775)、これが予測確率の差の一員となっている。
ここで使っている理論
Shapashでは主にSHAPと呼ばれる手法を用いて算出した結果を可視化しているようです。
SHAPの詳細は以下の記事がわかりやすいです。
なお、私も昔記事に書きました。
レポート
以下の情報をhtmlとして出力する。
- プロジェクトに関する一般情報
- 使用したデータセットの説明
- データの準備とフィーチャリングに関する文書
- 使用したモデルの詳細(ライブラリやパラメータなど)
- 訓練セットとテストセットの違いに焦点を当てたデータの探索
- モデルの全体的な説明可能性(ダッシュボードのうちグローバルな内容(①Feature Importance②Feature Contribution)
- モデルのパフォーマンス
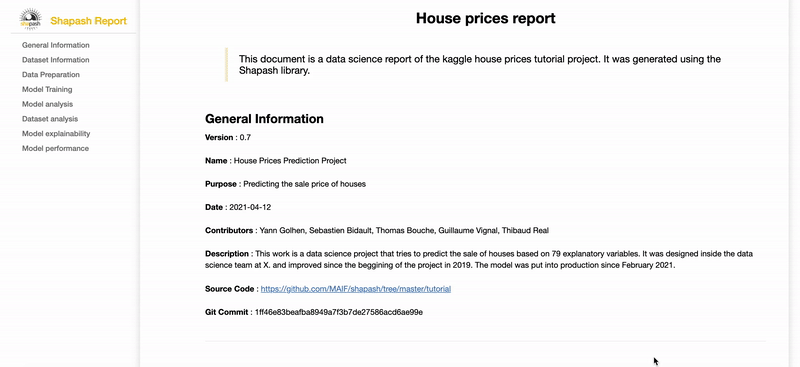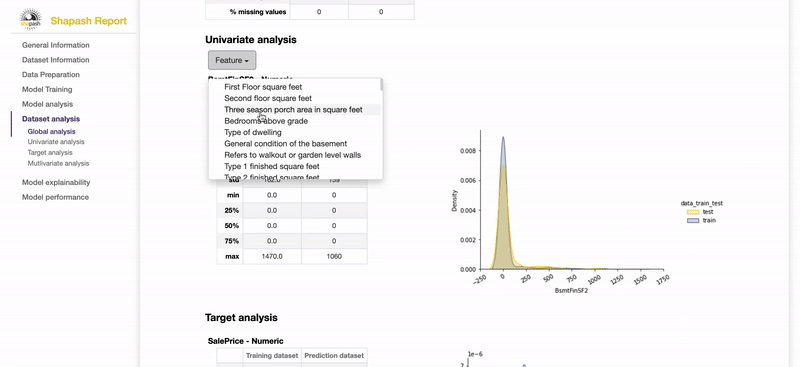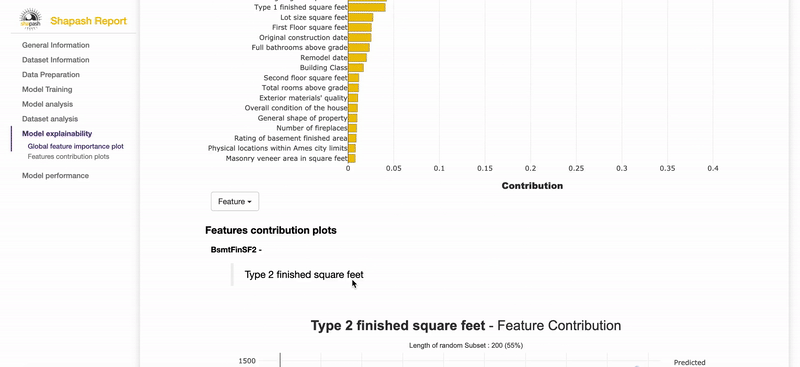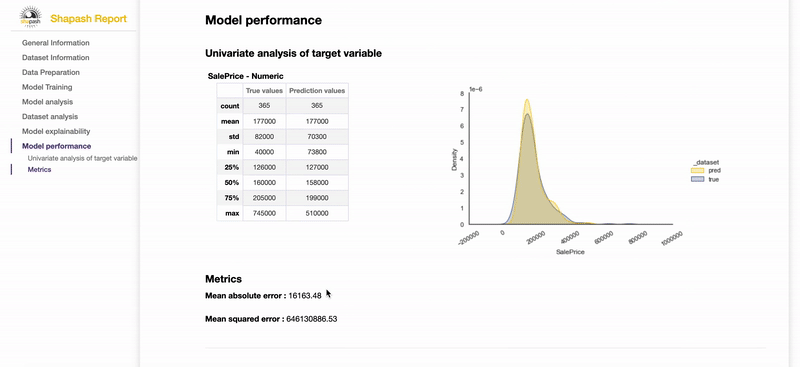
なお雰囲気を知りたい場合は、公式のサンプルレポートを見れる。
はじめの3つは以下のサンプルのように記載したymlファイルを作成して色々と書いてから渡す必要があるが、それ以外は自動で生成してくれる。
作成はgenerate_reportメソッドを使う。
xpl.generate_report(
output_file='output/report.html',
project_info_file='utils/project_info.yml',
x_train=test_data,
y_train=train_y,
y_test=test_y,
title_story="IBM HR analytics",
title_description="""IBM HR analyticsのShapashテスト""",
metrics=[
{
'path': 'sklearn.metrics.f1_score',
'name': 'F1 Score',
},
{
'path': 'sklearn.metrics.precision_score',
'name': 'precision',
}
]
)
*1:あるいは、そこから更にそれらの合計を1.0にするように変換