scikit-learnの機能を拡張/変更したscikit-learn準拠モデルを作る
これはなにか
scikit-learn APIにはない新たな予測モデルを作成したい。
そのときscikit-learnをベースに作成することで、GridSearchやCrossValidationなどscikit-learnで使える関数をそのまま流用したscikit-learn準拠のモデルを作成できる。
言い方を変えると、完全に0からモデルを作る場合、scikit-learnにあるGridSearchなどに類するものは自分で1から作らないといけない。
scikit-learn準拠の自作予測モデルを作成する
以下の流れでscikit-learn準拠の自作予測モデルを作成する。
sklearn.base.BaseEstimatorを継承- 回帰の場合
sklearn.base.RegressorMixin、分類ならsklearn.base.ClassifierMixinを継承 - モデルのアルゴリズムを
fit関数として定義 - モデルの評価をおこなう
predict関数を定義
3, 4のfit, predictはsklearnモデルの基礎となるため必須かつ、この関数名じゃないといけない。例えば、GridSearchは内部的には渡されたパラメータをもとにfit,predictを用いているので関数名を変えると利用することができなくなる。
また、fitではモデルアルゴリズムを実装しその結果を返すコードを記述し、predictではfitの返り値を使った計算をおこなって予測結果を出すコードを記述する。
実例
試しに、リッジ回帰を実装する。
classを定義するとき、コンストラクタとして__init__は必須となる。また、ここではclassの引数となる値の代入をするが、ここで計算をおこなう*1と一部APIがエラーになるらしい。
なお、コードは以下の記事をおおいに参考にした。
classを定義するときに、ちゃんと挙動するかを確認する関数は以下の記事が詳しい。例えば、ちゃんとscikit-learn準拠になっているか確認するcheck_estimatorや、 predictをする前にfitがちゃんと機能しているか確認するcheck_is_fittedなど。
この関数を用いると、エラーメッセージとして何が間違っているか明示してくれるのでできる限り使用した方が良い*2。
また、以下の記事のように引数の型定義や長さなどをチェックするassertなども仕込んでいるとなおよい。
import numpy as np from sklearn.base import BaseEstimator, RegressorMixin class RidgeRegression(BaseEstimator, RegressorMixin): # コンストラクタの設定 # 初期値は必須 # 今回の場合、罰則項λを渡してモデルオブジェクトを作る。初期値は1.0 def __init__(self,lamb=1.0): self.lamb = lamb # リッジ回帰のアルゴリズムを実装 # データはここで渡したり、加工をおこなうこと # 具体的には係数を計算 def fit(self, X, y): A = np.dot(X.T, X) + self.lamb * np.identity(X.shape[1]) b = np.dot(X.T, y) # fit内で定義された変数にはサフィックスで '_' を用いる(慣習なので必須ではない) self.coef_ = np.linalg.solve(A,b) # fitではselfを返す return self # ここで推定をおこなう。 # 実装上の問題で、yを渡す必要があるが必要ない場合はNoneとしておく def predict(self ,X, y=None):): # fitで計算した係数を用いて推定した値を返す return np.dot(X, self.coef_)
このモデルを実際に使うと以下のようになる*3。
#ボストン住宅価格データセットの読み込み from sklearn.datasets import load_boston boston = load_boston() #説明変数 X_array = boston.data #目的変数 y_array = boston.target # 罰則項を0.5にする model = RidgeRegression(0.5) # fitでモデルの学習 model.fit(X_array, y_array) # predictでyの予測 y_pred = model.predict(X_array)
また、scikit-learn準拠モデルなのではじめに説明したように既存のscikit-learn APIを用いることができる。
以下はGridSearchCVでパラメータを求める例。
なお、ここではscikit-learn準拠モデルで継承したMixin内で定義されているscoreを用いている。Mixin内のscoreから評価の定義を変えたい場合は自作scikit-learn準拠モデル内でscoreをオーバーライドして定義し直す必要がある。
from sklearn.model_selection import GridSearchCV # パラメータの探索範囲の指定 parameters = {'lamb':np.exp([i for i in range(-30,1)])} model = GridSearchCV(RidgeRegression(), parameters, cv=5) model.fit(X_array, y_array) best = model.best_estimator_ # => RidgeRegression(lamb=1.0)
なお、RidgeRegressionを定義するときに引数lambの初期値を設定してないとGridSearchCVなどでエラーになる。
実際にリッジ回帰をおこなう場合のsklearn.linear_model.LinearRegression
実際の sklearn.linear_model.LinearRegression コードは以下となる。
当たり前だが実際のコードを読むと他にも関数を定義しており、同様に関数を定義すると自作scikit-learn準拠classに所属する自作関数を作ることもできる。また、これらコードを読むことで実装がどうなるか確認することもできる。
自作のTransformerを使う
機械学習モデルを作成する際に、多くのモデルで前処理として標準化や正規化をはじめとした前処理をする必要がある。
scikit-learnではそのためのclassとして、sklearn .preprocessingのStandardScalerやRobustScaler、MinMaxScalerなどのTransformer(変換器)が提供されており、fitやtransform、fit_transform関数で処理をおこなう。
https://helve-python.hatenablog.jp/entry/scikitlearn-scale-conversionhelve-python.hatenablog.jp
このとき、StandardScalerのような前処理を自作でおこないたい場合、TransformerMixinを継承したclassを作成する。
前節のsklearn.base.RegressorMixinやsklearn.base.ClassifierMixinをベースにしたscikit-learn準拠モデルでは、GridSearchなどが使える機械学習モデルを作成できるというメリットがあった。
本節のTransformerMixinを使うメリットはfit_ transformや、一連の前処理を一括しておこなうsklearn.pipeline (後に記事を書く予定) で自作のTransformerを用いることができる。
以下の流れでscikit-learn準拠の自作のTransformerを作成する。
sklearn.base.BaseEstimatorを継承- データの情報(統計情報など)を取得する
fit関数を定義(情報がいらない場合は特になにもしない) - データを加工する
transformを定義
実例
外れ値の置き換え
以下では、特徴量の外れ値を処理するためにnumpy.clipを用いて、0.1パーセンタイル点から99.9パーセンタイル点の範囲に収まるようにそれぞれを超える値を置き換えるTransformerを作成する。
class FeatureClipper(BaseEstimator, TransformerMixin): def __init__(self, cols_to_clip_lower=None, cols_to_clip_upper=None): self.cols_to_clip_lower = cols_to_clip_lower self.cols_to_clip_upper = cols_to_clip_upper def fit(self, X, y=None): # 各特徴量の0.001, 0.999パーセンタイル点を取得 self.lower_bounds = {c: X[c].quantile(0.001) for c in self.cols_to_clip_lower} self.upper_bounds = {c: X[c].quantile(0.999) for c in self.cols_to_clip_upper} return self def transform(self, X): # 直接の書き換えが起きないようにcopy _X = X.copy() # 各特徴量を0.999パーセンタイル点に収める(0.999を超える値は0.999で置き換え) if self.cols_to_clip_lower is not None: for c in self.cols_to_clip_lower: _X[c] = _X[c].clip(lower=self.lower_bounds[c]) # 各特徴量を0.001パーセンタイル点に収める(0.001より小さい値は0.001で置き換え) if self.cols_to_clip_upper is not None: for c in self.cols_to_clip_upper: _X[c] = _X[c].clip(upper=self.upper_bounds[c]) return _X
先程用いたボストン住宅価格に外れ値を作って適用してみる。
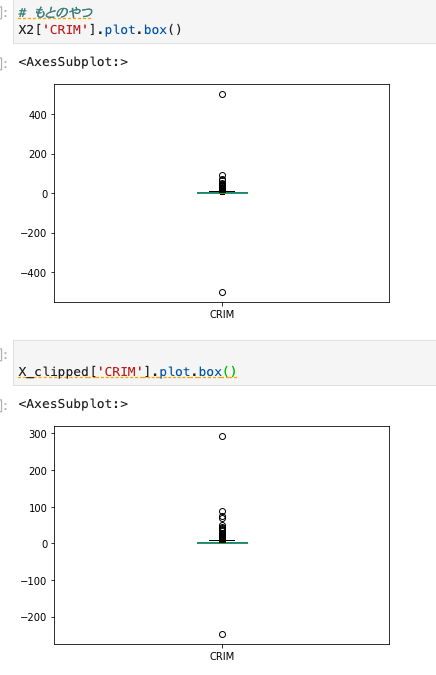
#ボストン住宅価格データセットの読み込み from sklearn.datasets import load_boston boston = load_boston() #説明変数 X = pd.DataFrame(boston.data, columns=boston.feature_names) # CRIM列をテキトーに外れ値に置き換える X2 = X.copy() X2.iloc[0,0] = -500 X2.iloc[1,0] = 500 # 最小と置き換わる値 # X2['CRIM'].quantile(0) # => -500.0 # X2['CRIM'].quantile(0.001) # => -247.4954247 # 最大と置き換わる値 # X2['CRIM'].quantile(0.999) # => 292.4329810000252 # X2['CRIM'].quantile(1) # => 500.0 # Transformerの適用 tranceformer = FeatureClipper(cols_to_clip_lower=['CRIM'], cols_to_clip_upper=['CRIM']) X_clipped = tranceformer.fit_transform(X2)
実際元のX2['CRIM']とX_clipped['CRIM']の箱ひげ図を見ると置き換わっていることがわかる。
特徴量追加
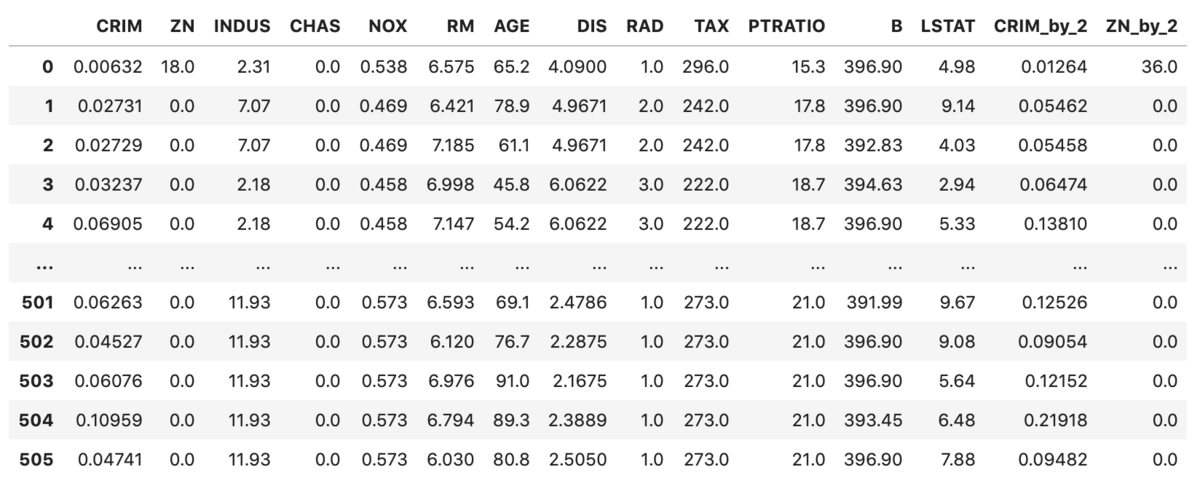
下記コードでは特徴量を追加するTransformerを作成する。簡易化のため、ボストン住宅価格のCRIM, ZNを2倍するというよくわからん特徴量を追加する。
from sklearn.base import BaseEstimator, TransformerMixin class FeatureAdder(BaseEstimator, TransformerMixin): def __init__(self, cols=['CRIM', 'ZN']): self.cols = cols def fit(self, X, y=None): # 統計情報などは使わないのでそのまま return self def transform(self, X): # 直接の書き換えが起きないようにcopy _X = X.copy() # 新たな特徴量の作成 _X['CRIM_by_2'] = _X['CRIM'] * 2 _X['ZN_by_2'] = _X['ZN'] * 2 # 新しく変数が出来るので、後で取り出せるよう変数名を格納しておく self.colnames = _X.columns.tolist() return _X tranceformer = FeatureAdder() tranceformer.transform(X_df) # fitは使わないのでtransform
その他
なお、Mixin系は以下(Mixin( で検索するとわかりやすい
https://github.com/scikit-learn/scikit-learn/blob/14031f6/sklearn/base.py:embed:cite:w600
参考
コードの一部は以下の書籍にあるコードを参考にした
