BUSINESS DATA SCIENCE 3章 Regularization② ペナルティを用いた変数選択
BUSINESS DATA SCIENCEの続き。
データなどは作者のgitにある。

最近「ビジネスデータサイエンスの教科書」という邦題で日本語版も出たみたいです

- 作者:マット・タディ
- 発売日: 2020/07/22
- メディア: 単行本
この章はなにか
高次元のモデルを作成するときに、オーバーフィットを避けた良い予測をできるモデル選択(変数選択)において注意すべき点が色々とある。
この節はなにか
前回はいったん優位全変数用いたcut-offモデルを用いた予測性能評価をおこなった。これは有意な変数を使用するのは妥当そうだが、予測性能に関して、全て使う方がいいのか、この中のいくつかの変数を使う方がいいのか、はたまたそもそもどういう組み合わせの変数を使えばいいのかわからない。
そのため、この節ではどの変数を使えばいいのかという話。
Regularization Paths
有意な変数の中でどの変数を使えばいいのか。
例えば、全組み合わせを試す場合、変数がp個ある場合2pパターンのモデルを作成することとなる。例えば、変数が20個の場合でも220 = 1,048,576パターンのモデルを作成することになり、非常に時間がかかる。
そのため、この章ではregularizationというアイデアを紹介する。
一般的によくされているがあまり良くないアプローチとして、 「全変数を用いてGLMをおこない、その中でカットオフ基準を満たす有意な変数を使用する」という、 前記事のアプローチがある。このようなアプローチはBackward Stepwise regressionと呼ぶがこれは、以下の2点において問題がある。
- 変数間に相関があると多重共線性が発生し分散が大きくなる。そのため、p値が大きく出がちになるため本当は有意でも有意と出ない。
- full-modelのように、オーバーフィットしているモデルのp値を用いている変数選択をおこなっている。これは、つまり予測には貢献していなくともたまたまISデータへのフィッティングに良い効果を発揮する場合だとしても有意な変数として扱われるということを指す。
このような問題があるので、別のアプローチを考える必要がある。まず1つ目に、Forward Stepwise Regressionという先ほどと逆のことをおこなうアプローチがある。
Forward Stepwise Regression
Forward Stepwise Regressionは1変数モデルを全変数で作成しそれぞれでIS-R2を求める。この中で一番IS-R2が高い変数を採択する。
次に、先程の変数+1変数を追加した中で同様にIS-R2が最大となる変数を追加する。このステップを繰り返しおこない、IS-R2があるルール下で変数を追加していく(例えばAICがある一定の値になるまで、など)。
これは、greedy(貪欲法)のアプローチとなっているので、全組み合わせを見たときにBestとはならないが、速度と安定性の観点でBetterなものが選択される。
Backwardでは、オーバーフィットしているモデルなので誤差などのデータのわずかなゆらぎをキャプチャーしてIS-R2を評価するが、Stepwiseはシンプルなモデルから複雑なモデルになっているのでそのようなことは起きず安定性がある。
実データ
前回と同様のデータを用いる。
Stepwiseはstep関数で使用できる。
library(tidyverse) SC <- read.csv("semiconductor.csv") full <- glm(FAIL ~ ., data=SC, family=binomial) ## A forward stepwise procedure # null model null <- glm(FAIL~1, data=SC) # forward stepwise: it takes a long time! system.time(fwd <- step(null, scope=formula(full), dir="forward")) # nullの係数からfullの係数に順次近づけていく # ユーザ システム 経過 # 3.424 0.028 3.458 length(coef(fwd)) # chooses around 70 coef # 69
このときIS-R2が最も高くなる変数を1つずつ追加した70モデルが作成され、AICが70モデル目になったとき69モデル目よりも下がったためそこで変数追加が停止される。
The key to modern statics is regularization
stepwiseはIS-R2は安定しているが、データセットの変化に対しては不安定となる。つまり、予測における評価のOOS-R2では不安定となる。そのため、stepwiseも予測においては使えない。
新しいアイデアとして、devianceを求める際に変数の係数の大きさに応じたペナルティを付与する項を足すことを考える。
argminの1項目がdevianceで2項目がペナルティ項となっており、求めたいβ以外も含めた全βの係数に対して関数c()を噛ませた総和となっている(のか?kがよくわからん)。
また、λはペナルティへのかかり方の強弱を指定する定数。
全βの係数の総和が小さいほどペナルティは小さくなるので、各係数はできる限り小さい方がよくなる。このとき、多くの係数が0になることから結果的に次元の削除をおこなうことができます。逆にいえば、0ではない係数の変数が「選択された変数」ともいえる。
また、見方を変えて1項目はEstimation Cost・2項目をTesting Costと考える。
つまり、Estimation Costは通常通り予実の差であるIS devianceの大きさがコストとなる(通常のβを求めるのと同様)。
Testing Costはβ≠0とした場合のコスト、通常の仮説検定でいうβ=0の確率pが大きいほどコストがかかるという見方ができる。つまり、ここから有意な変数ほどコストが小さくなるため、係数が0ではない変数は、暗に有意な変数が選択されていることに等しい。
なお、このときのペナルティ項の関数c(β)はいくつか考えられ、それぞれ名前がついておりペナルティのかかり方が異なる。
- ridge : β2 : 小さいβにはより小さく、大きいβはより大きなペナルティをかける = 大きいβほど選択されづらさが急激に上がる
- lasso : |β| : βが大きくなるほど単純比例したペナルティ
- elastic net : α β2 + (1-α) |β|(αはパラメータ) : ridge + lassoなので、ridgeの効果をやや減らしたもの
- log : log(1+|β|) : ペナルティがある一定で増えなくなる = バイアスを除去する(らしいが...)
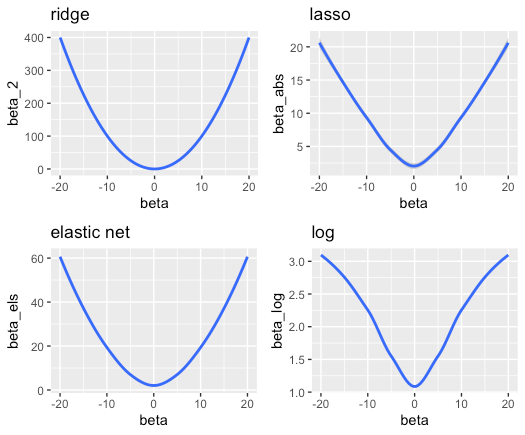
どのペナルティ関数でも、係数βが大きくなるほどペナルティが大きくかかるため選択されづらくなる働きをする。
logに関しては、安定性に乏しく計算に時間がかかるのであまり使わないほうがよい。
また、lassoは多くの係数を0にすることから変数選択に使用しやすい(理由は以下の記事がわかりやすい)ので、基本的にlassoを使いつつ他のものも試してみるというスタイルが良い。
the lasso alone cannot do model selection
ペナルティのかかり方の強弱を指定するλの選び方について考える。やり方としては、全係数を0にするλから徐々に小さくしていき最適なポイントを見つける。つまり、最もシンプルなモデルから徐々に複雑にしていくことで、データのゆらぎに対して安定に決めることができる。
実データ
webのブラウザ閲覧履歴を用いて、履歴から閲覧時間を推定する。
このとき、高速で安定したlassoを使えるgaml関数を用いる(同様のパッケージで gmlnet 関数がある)。これは、λを指定しないで作成するとλの探索がおこなわれ、各λ事でのモデル結果を格納する。また、この結果を plot に渡すとλとβの関係を示す(各線が各β)。
なお、引数に渡す値は行列じゃないといけないので、データによっては as.matrix や Matrix::sparseMatrix 関数などで行列化する(後者はスパースデータ用なので大量のスパースデータの場合はメモリ消費量などの観点で扱いやすくなる)。また、Xは数値しか使えないため因子型を取り扱い場合は、横持ちでダミー変数を作る必要がある。
library(gamlr) ## Browsing History. ## The table has three colums: [machine] id, site [id], [# of] visits web <- read.csv("browser-domains.csv") ## Read in the actual website names and relabel site factor sitenames <- scan("browser-sites.txt", what="character") web$site <- factor(web$site, levels=1:length(sitenames), labels=sitenames) ## also factor machine id web$id <- factor(web$id, levels=1:length(unique(web$id))) ## get total visits per-machine and % of time on each site ## tapply(a,b,c) does c(a) for every level of factor b. machinetotals <- as.vector(tapply(web$visits,web$id,sum)) visitpercent <- 100*web$visits/machinetotals[web$id] ## use this info in a sparse matrix ## this is something you'll be doing a lot; familiarize yourself. xweb <- sparseMatrix( i=as.numeric(web$id), j=as.numeric(web$site), x=visitpercent, dims=c(nlevels(web$id),nlevels(web$site)), dimnames=list(id=levels(web$id), site=levels(web$site))) # what sites did household 1 visit? head(xweb[1, xweb[1,]!=0]) # atdmt.com yahoo.com msn.com google.com # 4.0520260 11.8559280 0.2501251 6.5282641 # aol.com questionmarket.com # 0.1500750 1.3506753 ## now read in the spending data yspend <- read.csv("browser-totalspend.csv", row.names=1) # us 1st column as row names yspend <- as.matrix(yspend) ## good practice to move from dataframe to matrix ## run a lasso path plot spender <- gamlr(xweb, log(yspend), verb=TRUE) # ** n=10000 observations and p=1000 covariates *** # segment 1: lambda = 0.2325, dev = 2.783e+04, npass = 0 # segment 2: lambda = 0.2219, dev = 2.778e+04, npass = 3 # segment 3: lambda = 0.2118, dev = 2.774e+04, npass = 3 # ... plot(spender) ## path plot
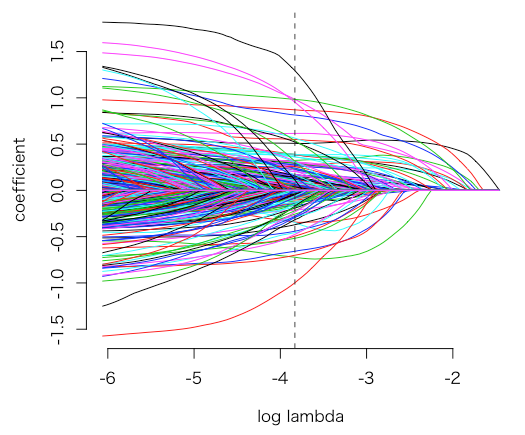
次に、λを動かしたときそれぞれでのモデルに対するMean Squared Error(MSE)と標準誤差を見る。このとき、k-fold cross validationをおこなう。つまり、MSEはtrainと別のデータで計算するし、各Foldで求めたMSEの平均を評価とする。これは gamlrでは cv.gamlr 関数でλとMSE評価を返す。
cv.spender <- cv.gamlr(xweb, log(yspend), verb=TRUE) ## plot them together par(mfrow=c(2,1)) plot(cv.spender) plot(cv.spender$gamlr) ## cv.gamlr includes a gamlr object
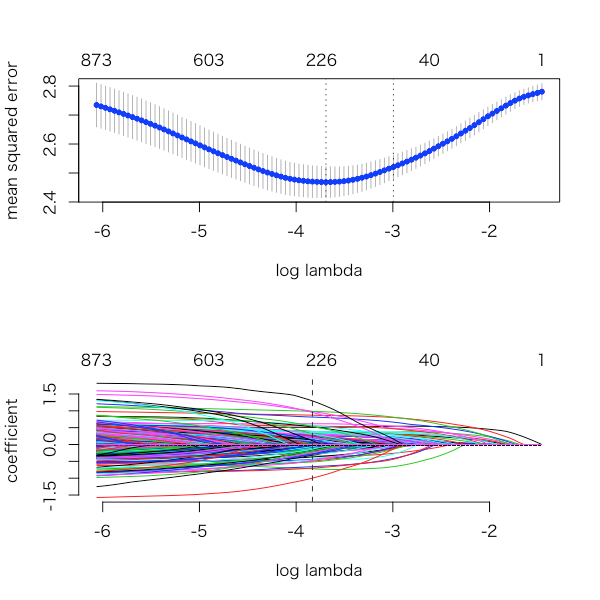
下図は先ほどと同様に各変数の各係数、上図はλを動かしたときのMSEとなる。-3あたりにある線が標準誤差が1の範囲でMSEが最小になるλ(CV-1se)で、-3.6あたりにある線がMSEが最小となるλ(CV-min)になる。
このいずれかのλを用いてlassoをおこなうと良いMSEが取れる。
それぞれの使い分けとして、基本的には予測誤差(MSE)が一番小さいCV-minを用いる。一方でCV-1seは、CV-minよりもλが大きいので強いペナルティがかかるため選択される変数が減る。これは、変数が減るため多重共線性などが起きづらいなどの理由で多少ロバストな結果になる。
また、real.com-o01 americanexpress.com変数におけるCV-1seとCV-minの係数結果を見ると以下のようになり、real.com-o01 はCV-1seでは0に、americanexpress.comはどちらも係数は出ているがCV-1seの方がペナルティが強いのでCV-minより小さい値になっていることがわかる。
beta1se <- coef(cv.spender) ## 1se rule; see ?cv.gamlr betamin <- coef(cv.spender, select="min") ## min cv selection cbind(beta1se,betamin)[c("real.com-o01","americanexpress.com"),] # 2 x 2 sparse Matrix of class "dgCMatrix" # seg34 seg48 # real.com-o01 . -0.13137434 # americanexpress.com 0.03454526 0.04897335
ただし、このときのλはCVしたときの平均的にMSEが最小となるλなので実際にOOS-R2を計測すると最小のOOS-R2とはややずれることがある。これは1SE(標準誤差)の範囲内で動くからだが、CVでのK数を増やすことで範囲を狭めることができる。
参考
gamlr の日本語記事はほぼないのでほぼ同様の使い方をするgmlnetの記事
www.slideshare.net