Rではじめるデータサイエンス 演習1章② 5~8節
続き。

- 作者:Hadley Wickham,Garrett Grolemund
- 発売日: 2017/10/25
- メディア: 単行本(ソフトカバー)
1.5演習問題
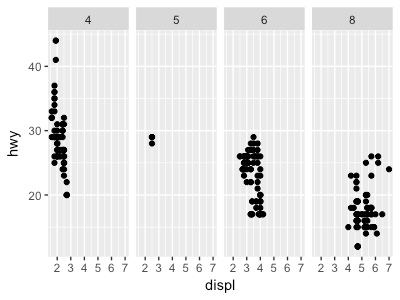
1. 連続変数でファセットを作るとどうなるか。
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy)) + facet_wrap(~ displ, nrow = 2)
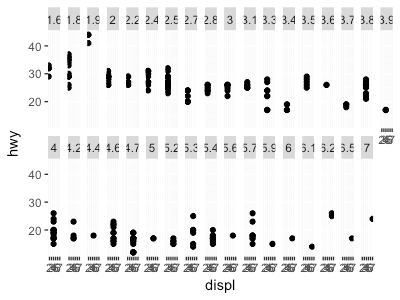 連続変数の各値毎に分けられる。おそらく、離散変数として処理?
連続変数の各値毎に分けられる。おそらく、離散変数として処理?
解答みると、やはり離散に変換されているようです。
2. facet_grid(drv ~ cyl)のプロットの空白のセルは何を意味するか。次のプロットとどのよう に関係するか。
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy)) + facet_grid(drv ~ cyl)
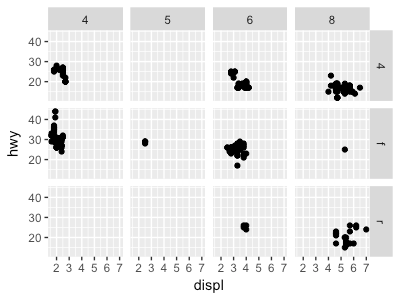 これの空白セルはその組み合わせ(例えばdrv = 4, cyl = r)のデータがないことを指す。
これの空白セルはその組み合わせ(例えばdrv = 4, cyl = r)のデータがないことを指す。
ggplot(data = mpg) + geom_point(mapping = aes(x = drv, y = cyl))
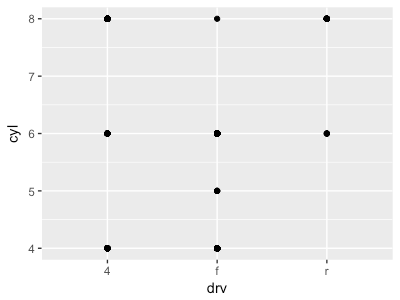 これは、組み合わせがあるものに点をつけるプロットで、同様の結果となる。
ちなみに、geom_pointではmappingとして作成しているので縦横ともに連続値が指定されることからデータにない5の軸がある。
これは、組み合わせがあるものに点をつけるプロットで、同様の結果となる。
ちなみに、geom_pointではmappingとして作成しているので縦横ともに連続値が指定されることからデータにない5の軸がある。
facet_gridの方は、5のデータはないため出力されていないが、1.でfacetは離散として処理?と書いた仮設と合致。
3. 次のコードはどんなプロットになるか。「.」は何をしているのか。
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy)) + facet_grid(drv ~.)
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy)) + facet_grid(. ~ cyl)
「.」は指定なしを指す。 「~」は、~の前の変数で行分割し、後ろの変数で列分割。
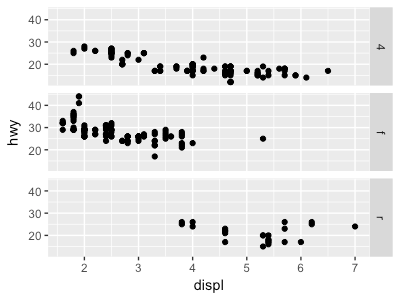
4. 本節の最初のファセットプロットを考えよう。 ファセットを使うのは、色のエステティック属性を使うのと比べてどんな利点があるか。逆にど んな欠点があるか。データセットがもっと大きいと、それらはどう変わるだろうか。
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy)) + facet_wrap(~ class, nrow = 2)
利点として、明確に分割されるので変数間の違いがわかりやすい。
欠点として、内容が多いと見づらくなる?(ただ、これは色でも同じ気がする
解答見ると、正しいが、他にも人間が区別して認識数は9個なのでそれより多いとわかりづらいため(ナインナンバーとかいうやつ)という理由もあるようです。
欠点としては、軸の数値比較がしづらくなることがあるため。
5. ?facet_wrapを読みなさい。nrowは何を表しているか。ncolは何を表しているか。他のオプショ ンは個々のパネルの配置にどう影響するのか。なぜfacet_grid()には変数nrowやncolがない のだろうか。
nrowは行数、ncolは列数。例えばどちらも2にすると22の分割になる。ただし、例えば4のようにclassをした場合、レベル数は7で22より大きいためエラーになる。
facet_gridは指定した変数で行列分割数が決まるため変数nrowやncolがない。
6. facet_grid()を使うとき、レベルの多い方を行の変数として使うのが普通である。なぜだろう か。
わからない。
解答みると、縦(行)にスペース増やすのは問題ないが、横だとスペースが足りなくなるから、とのこと。
1-6演習問題
1. 折れ線グラフを描くにはどのgeomを使うか。箱ひげ図では? ヒストグラムでは? 面グラフでは?
折れ線 geom_line 箱ひげ geom_boxplot ヒストグラム geom_hist 面 geom_area()
2. 次のコードを頭の中で実行して出力がどうなるか予測しなさい。それから、Rで実行して予測が 正しかったかチェックしなさい。 ```r
ggplot( data = mpg, mapping = aes(x = displ, y = hwy, color = drv) ) + geom_point() + geom_smooth(se = FALSE)
[f:id:chito_ng:20190116192247p:plain] x = displ, y = hwyでcolorとしてdrv毎に分けたデータに対して散布図と平均線を引く。 留意点として、ggplot部でcolorを指定しているのでその設定は以降のgeomにも引き継がれる。 出力結果みると >using method = 'loess' とあるのっで平均線ではなくloess回帰線 なお、seは信頼区間の表示有無。 [f:id:chito_ng:20190116192935p:plain] ### 3. show.legend = FALSEは何をしているのか。 凡例の表示有無 ### 4. geom_smooth()のse引数は何をしているのか。 信頼区間 ### 5. 次の2つのグラフは同じかどうか。その理由は何か。
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + geom_point() + geom_smooth()
ggplot() + geom_point( data = mpg, mapping = aes(x = displ, y = hwy) ) + geom_smooth( data = mpg, mapping = aes(x = displ, y = hwy) )
はじめにggplotで使うデータ指定してからレイヤー重ねるか、個々のレイヤーで指定してるかの違いで同じ。 ### 6.次のグラフを生成するコードを作成しなさい。 [f:id:chito_ng:20190116193415p:plain]
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + geom_point() + geom_smooth( se = F)
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + + geom_point() + geom_smooth(se = F,mapping = aes(group = drv))
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = drv)) + geom_point() + geom_smooth(se = F)
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(colour = drv)) + geom_smooth(se = F)
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(colour = drv)) + geom_smooth(aes(linetype = drv), se = FALSE)
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(size = 5, color = "white") + geom_point(aes(colour = drv))
whiteを下のレイヤーにするため、先に書く。 # 1-7.演習 ### 1.stat_summary()のデフォルトgeomは何か。stat関数ではなくgeom関数を用いて先ほどのコー ドを書き直すにはどうするか。 ?stat_summaryで見ると、pointrangeとある。 書き直しはわからなかったので、解答見つつ。
ggplot(data = diamonds, mapping = aes(x = cut, y = depth)) + geom_pointrange(stat = "summary")
> No summary function supplied, defaulting to `mean_se()
[f:id:chito_ng:20190116200059p:plain] デフォルトでは点は平均値、棒は信頼区間を出すのでstat_summaryと異なる。 ちなみに?stat_summaryに以下のように書いている。 >You can either supply summary functions individually (fun.y, fun.ymax, fun.ymin), or as a single function (fun.data): >If no aggregation functions are suppled, will default to mean_se. 周囲を読むと、点の位置はfun.y、棒の上点はfun.max、下点はfun.minに対して集計関数を指定するようだ。 そのため、点の位置と、棒の上点・下点の指定をおこなうと以下。
ggplot(data = diamonds, mapping = aes(x = cut, y = depth)) + geom_pointrange(stat = "summary", fun.ymin = min, fun.ymax = max, fun.y = median)
### 2.geom_col()は何をするか。geom_bar()とどのように異なるか。 >There are two types of bar charts: geom_bar makes the height of the bar proportional to the number of cases in each group (or if the weight aethetic is supplied, the sum of the weights) とある。 カウントではなく、割合を表示。カウントはgeom_bar。 ###3.ほとんどのgeomとstatとは対になっており、一緒に使われる。ドキュメントを読んでこれらの 対のすべてのリストを作る。何が共通しているか。 パス。 ###4.stat_smooth()はどの変数を計算するか。振る舞いはどの引数が制御するか。 >Computed variables y predicted value ymin lower pointwise confidence interval around the mean ymax upper pointwise confidence interval around the mean se standard error とある。 ###5.比率棒グラフでは、group = 1に設定する必要がある。なぜか。言い換えると、次の2つのグラ フの問題は何か。
ggplot(data = diamonds) + geom_bar(mapping = aes(x = cut, y = ..prop..))
ggplot(data = diamonds) + geom_bar( mapping = aes(x = cut, fill = color, y = ..prop..))
グループ毎で計算されるので、前者は明示されない = 暗黙変換のcut毎のため分母 = 分子ですべて1になる。 そのため、group = 1で指定する必要がある。 ただ、groupは固定値1に対して集計して、単一変数であれば"hoge"とかでもよい? # 1-8.演習 ### 1.このプロットの問題は何か。どうすれば改善できるか。
ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) + geom_point()
[f:id:chito_ng:20190116203358p:plain] 点が重なっているので、重なりを散らす。
ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) + geom_point(position = "jitter)
[f:id:chito_ng:20190116203412p:plain] 1-8.の2以降と1-9.演習は省略。