特徴量作成を楽にするライブラリいくつかまとめて試す②xfeat
この記事はなにか
機械学習の特徴量を作るときに色々とめんどくさい部分を楽にできるライブラリの紹介。
具体的には以下を紹介する、
- featuretools
- xfeat
①のfeaturetoolsの記事は以下。脳死で既存特徴量の四則演算や集約などを一括で楽に作れる。
今回は脳死ではなくある程度考えつつ特徴量を作りたいときに利用するxfeatを紹介する。
何ができるか
主な機能は以下
- 特徴量の変換
- 特徴量の加工
- GBDTの変数重要度を用いた特徴量選択(+optunaにより最適化)
となる。
featuretoolsも似た感じだったが、あっちは指定した加工ができそうな特徴量に対しては脳死で全特徴量の加工を一気に作成できた。xfeatは任意で指定した特徴量に対して楽に加工ができる、という使い分けかな?あとxfeatではカテゴリカル変数に対しての変換が楽にできる。
ちなみに、pandasではなくcuDF((pandasより高速のデータフレームを提供するライブラリっぽい。))という形式にも対応していて、そっちを使った方が爆速になるとのことだが今回は使わない。
なお、今回データとしてみんな大好きtitanicデータを使った以下の記事のコードをお借りする(一部変更してます)。
特徴量の変換
sklearn.piplineのように、Pipelineを使ってencode処理をつなげたencoder群を作り、それをfit_transformで適用していく。
その際のencoder objectとして以下を提供している。
Categorical encoder:
- xfeat.SelectCategorical
- xfeat.LabelEncoder
- xfeat.ConcatCombination
- xfeat.TargetEncoder
- xfeat.CountEncoder
- xfeat.UserDefinedLabelEncoder.
Numerical encoder:
- xfeat.SelectNumerical
- xfeat.ArithmeticCombination.
User-defined encoder:
- xfeat.LambdaEncoder
例えば、以下のようにすると、SelectCategorical→ConcatCombination→TargetEncoderという順で処理するencoderをdfに対して適用、という意味になる。
from xfeat import Pipeline, SelectCategorical, ConcatCombination, TargetEncoder encoder = Pipeline( [ SelectCategorical(), ConcatCombination(), TargetEncoder(), ] ) df_encoded = encoder.fit_transform(df)
特定型の特徴量のDFを作る
普通にやると以下のように①dtypesをみて手打ちでがんばる②指定した型の列listを作る、のいずれかで地味にめんどい。
train_df.dtypes # => 型一覧 categorical_features = [col for col in train_df.columns if train_df[col].dtype == 'object'] train_df[categorical_features].head()
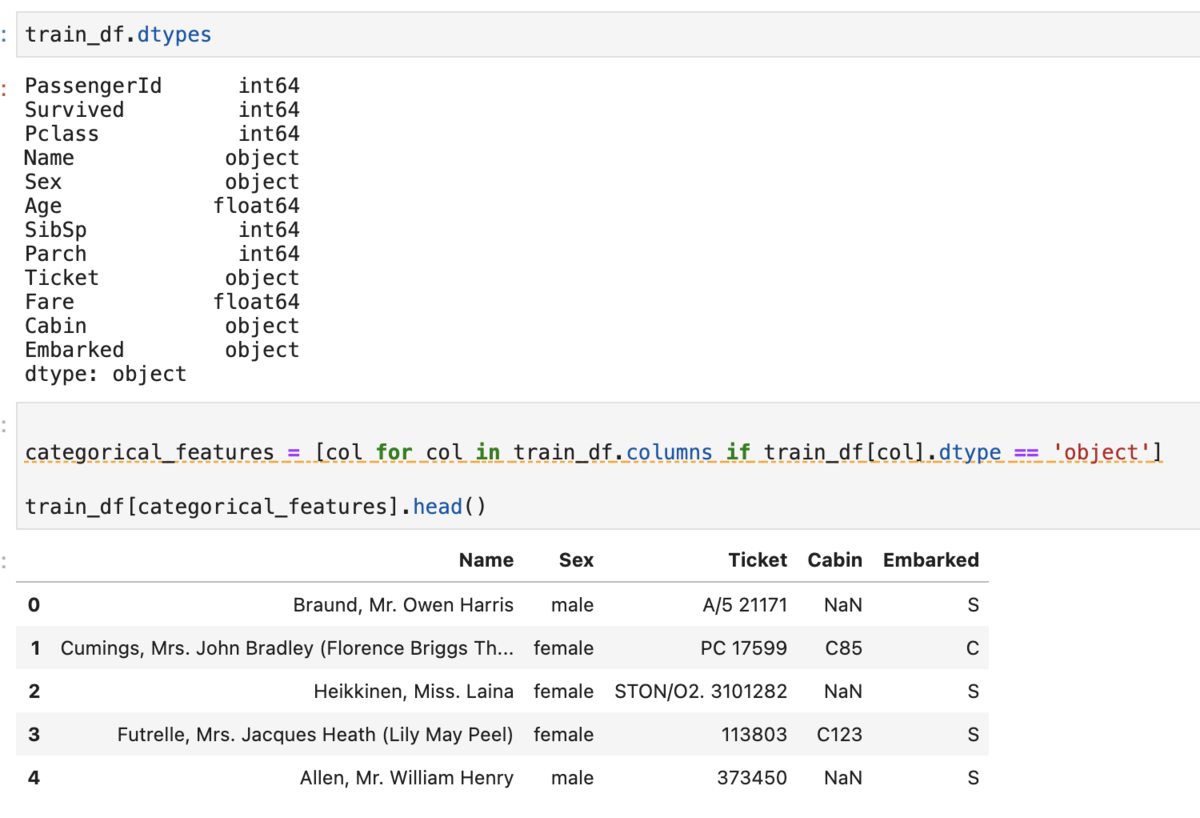
xfeatでは以下のようにかける。
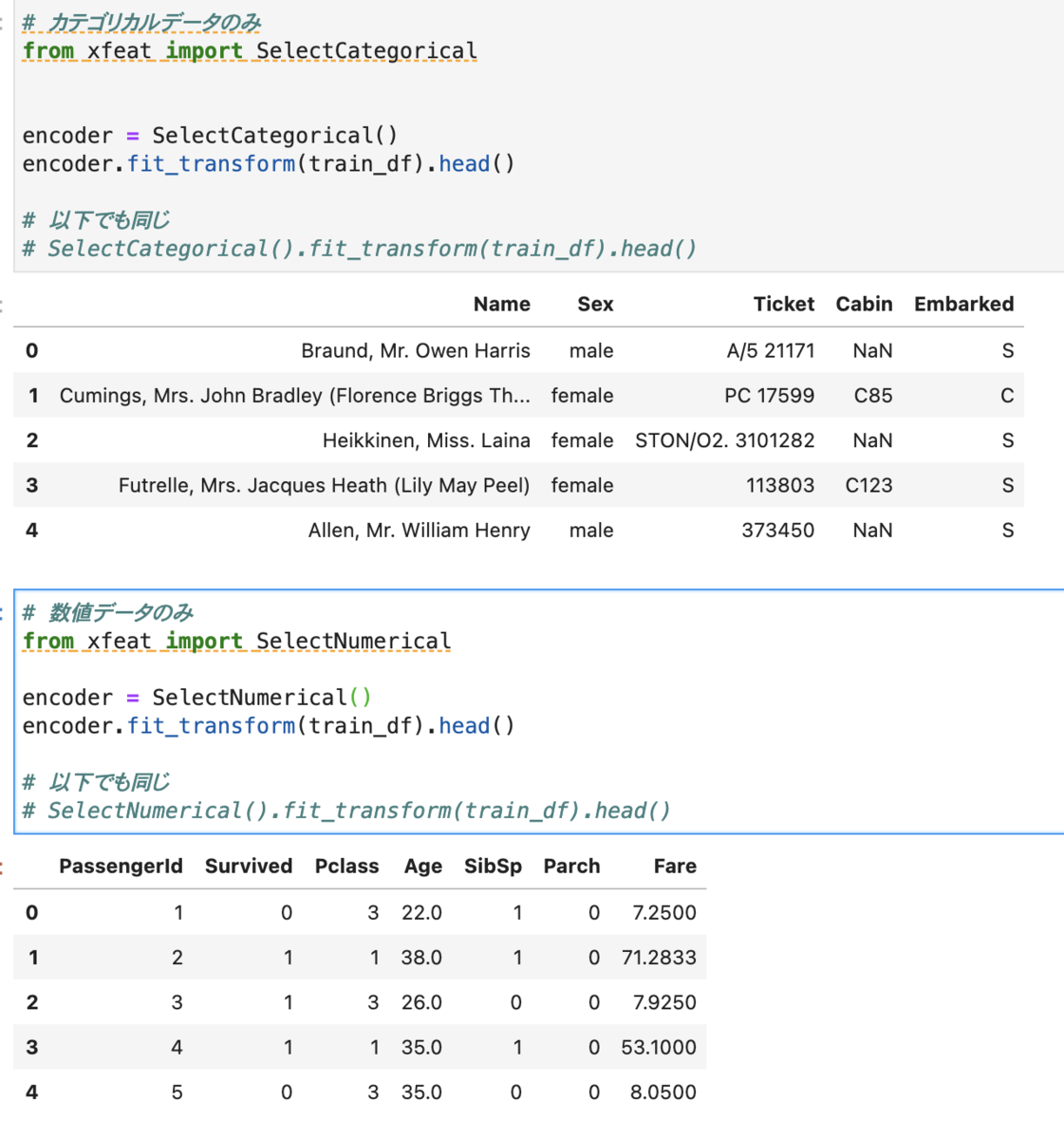
カテゴリカルデータ列のみのDFを作成
# カテゴリカルデータのみ from xfeat import SelectCategorical encoder = SelectCategorical() encoder.fit_transform(train_df).head() # 以下でも同じ # SelectCategorical().fit_transform(train_df).head()
数値データ列のみのDFを作成
# 数値データのみ from xfeat import SelectNumerical encoder = SelectNumerical() encoder.fit_transform(train_df).head() # 以下でも同じ # SelectNumerical().fit_transform(train_df).head()
特徴量の加工
カテゴリカル変数
機械学習ではカテゴリカル変数はそのままの文字列値で渡すことはできないので、なにかしらの変換が必要となる。
sklearn.preprocessingで変換処理はできるが、np.arrayで返ってくるのでDataFrameで色々やっていると対応がちぐはぐでめんどかったりするがxfeatではよしなにやってくれる。
ちなみに、Category Encodersというライブラリのも便利らしい。xfeatではOne-hot-Encodingみたいに多次元展開するものはなく、1次元変換のエンコーディングのみっぽいので他のも使いたい場合はCategory Encodersかな?
Label Encoding
from xfeat import Pipeline, SelectCategorical, LabelEncoder encoder = Pipeline([ SelectCategorical(exclude_cols=["Name", "Ticket"]), # Name,Ticketを除くカテゴリカル列のDFを作成 LabelEncoder(output_suffix=""), # 渡されたDFをlabel encodeする ]) encoded_df = encoder.fit_transform(train_df) encoded_df.head()
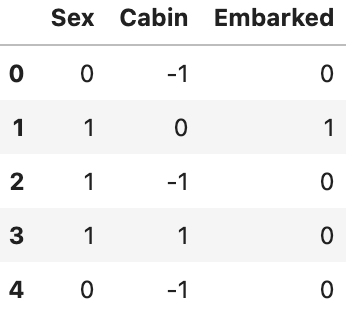
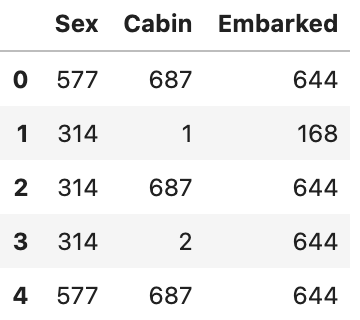
Count Encoding
from xfeat import CountEncoder # count encode from xfeat import Pipeline, SelectCategorical, LabelEncoder encoder = Pipeline([ SelectCategorical(exclude_cols=["Name", "Ticket"]), # Name,Ticketを除くカテゴリカル列のDFを作成 CountEncoder(output_suffix=""), # 渡されたDFをcount encodeする ]) encoded_df = encoder.fit_transform(train_df) encoded_df.head()
Target Encoding
# target encoding # 以下のHoldout TS # https://blog.amedama.jp/entry/target-mean-encoding-types from sklearn.model_selection import KFold from xfeat import TargetEncoder fold = KFold(n_splits=5, shuffle=False) encoder = TargetEncoder( input_cols=["Cabin"], # 変換対象 target_col="Survived", # target fold=fold, # foldの取り方 output_suffix="_re" # 変換後のsuffix ) encoded_df = encoder.fit_transform(train_df) encoded_df[["Survived", "Cabin", "Cabin_re"]].head()
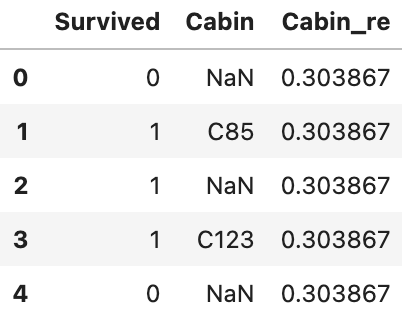
列組み合わせ(文字列)
また、カテゴリカル変数同士を組み合わせて新たな特徴量を作成することもできる。
# 2変数の組み合わせ from xfeat import SelectCategorical, ConcatCombination, Pipeline encoder = Pipeline([ SelectCategorical(exclude_cols=["Ticket", "Name"]), ConcatCombination( # drop_origin=True, output_suffix="_combine", r=2), # 組み合わせは3つ ]) encoder.fit_transform(train_df).head()

# 3変数の組み合わせ from xfeat import SelectCategorical, ConcatCombination, Pipeline encoder = Pipeline([ SelectCategorical(exclude_cols=["Ticket", "Name"]), ConcatCombination( # drop_origin=True, output_suffix="_combine", r=3), # 組み合わせは3つ ]) encoder.fit_transform(train_df).head()
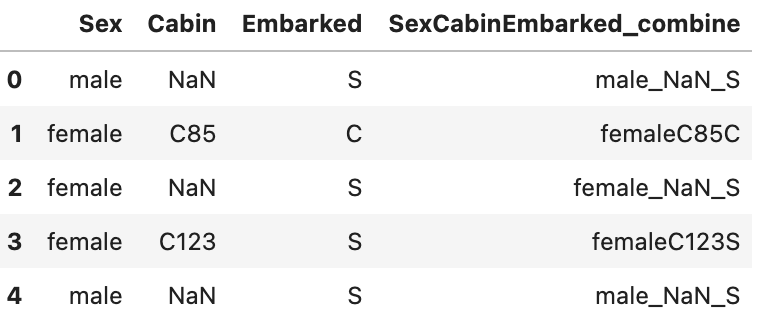
数値変数
集約関数
featuretoolsと同様に集約関数の適用ができる。ただし、こちらでは指定した列に対して適用する。以下ではAgeとPclass列それぞれをSex単位で集約している。
from xfeat import aggregation aggregated_df, aggregated_cols = aggregation(train_df, group_key="Sex", # group key group_values=["Age", "Pclass"], # 集約対象 agg_methods=["mean", "max"], # 集約関数 ) display(aggregated_cols, aggregated_df.head())
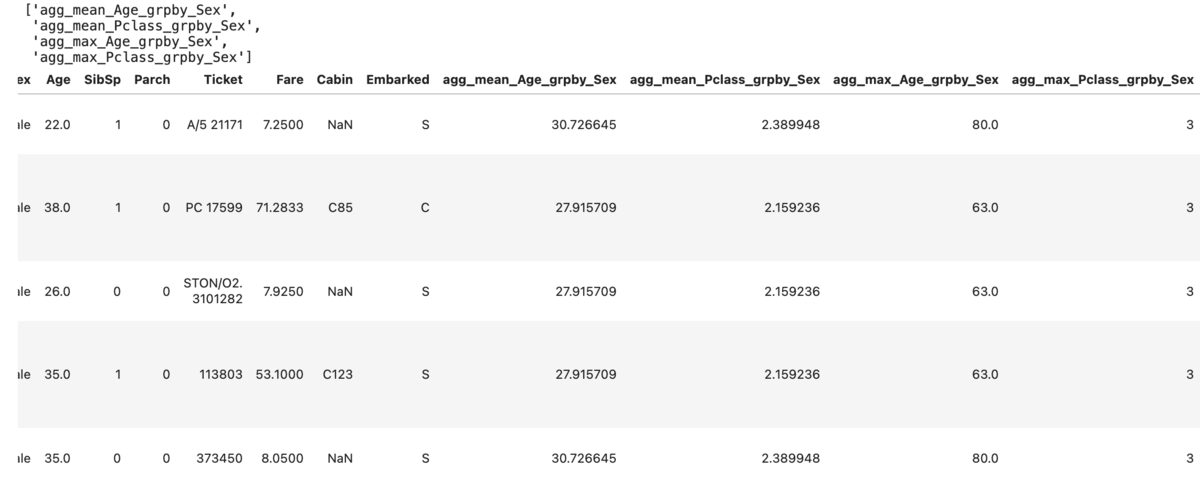
ちなみに、これはライブラリを使わない場合は以下で面倒
aggregated_df = train_df.copy() # 性別ごとの年齢の平均値を特徴量に追加 sex_mean_df = train_df.groupby('Sex')['Age'].mean() aggregated_df.loc[aggregated_df['Sex'] == 'female', 'agg_mean_Age_grpby_Sex'] = sex_mean_df['female'] aggregated_df.loc[aggregated_df['Sex'] == 'male', 'agg_mean_Age_grpby_Sex'] = sex_mean_df['male'] # 他の結合はagg特徴量は略 aggregated_df.head()
また、agg_methodsで自作関数を使うことはできるが処理後の列名がおかしくなるので少し工夫が必要とのこと。
列組み合わせ(数値)
これもfeaturetoolsにもあるが、こちらでは指定した列に対して適用する。
# 2変数の組み合わせ from xfeat import Pipeline, ArithmeticCombinations, SelectNumerical encoder = Pipeline([ SelectNumerical(), ArithmeticCombinations( # 兄弟/配偶者(SibSp)、両親/子供の数(Parch)を加算した特徴量を作成する input_cols=["SibSp", "Parch"], #drop_origin=True, output_suffix="_combine", operator="+", # 加算 r=2), ]) encoder.fit_transform(train_df).head()
Lambda処理
処理に対してLambda関数を書くことで自作の処理ができる。なお、この際のxは処理対象となるDFの全列(Pipelineの場合は直前までの処理結果)となるが、input_colsを使うと特定列のみが対象となる。
例えば、先程の列組み合わせ(数値)に対して更に四捨五入する処理を追加する。
# 2変数の組み合わせ + lambda処理 from xfeat import Pipeline, ArithmeticCombinations, SelectNumerical, LambdaEncoder encoder = Pipeline([ SelectNumerical(), ArithmeticCombinations( # 兄弟/配偶者、両親/子供の数を加算した特徴量を作成する input_cols=["Age", "Parch"], #drop_origin=True, output_suffix="_combine", operator="+", # 加算 r=2), LambdaEncoder( lambda x: round(float(x), -1), # 1の位で四捨五入 input_cols=["Age", "Fare"], output_suffix="_round", drop_origin=False,) ]) encoder.fit_transform(train_df).head()
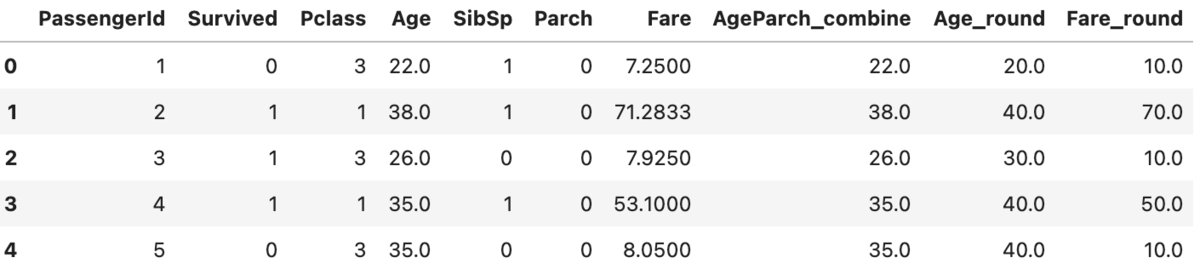
もちろん、lambda処理なので文字列に対しても可能。
特徴量作成を楽にするライブラリいくつかまとめて試す① featuretools
この記事はなにか
機械学習の特徴量を作るときに色々とめんどくさい部分を楽にできるライブラリの紹介。
具体的には以下を紹介する、
- featuretools
- xfeat
①では既存特徴量を四則演算したり集約したり、date型の年部分のみ取り出すなど、既存特徴量をもとに色々加工するのに便利なライブラリfeaturetoolsについて。
機械学習において「とりあえず既存特徴量を四則演算/集約でいじくりまわす」だけでもそれなりに精度が上がる*1ことから、それらを脳死で作成しまくることはそれなりに有効だが、コードを書くのが面倒なことも多い。これを楽にできるのが featuretools
何を書かないか
基本的な使い方などをメモ代わりに試すだけなので、取り扱いの詳細は公式ドキュメントか適宜貼るリンクを読んでくれというスタイルで書く。
featuretools
内部的に、複数データフレームの関係性込みでER図っぽい感じでデータを持つオブジェクトを作成しその情報をもとに指定した基礎集計をデータ型に応じていい感じにしてくれる。なお、型に応じた処理をしてくれる性質上pandasよりも型の種類は多いし、基礎集計もSQLの関数レベルであればデータ処理に使うものはだいたいある。
複数テーブルのあるデモデータで試す
いったん通常のやり方として、featuretoolsにあるデモデータで例示する。
なお、コードは以下の記事を参照した
import featuretools as ft
data = ft.demo.load_mock_customer()
display(data['customers'].head(),
data['sessions'].head(),
data['transactions'].head())
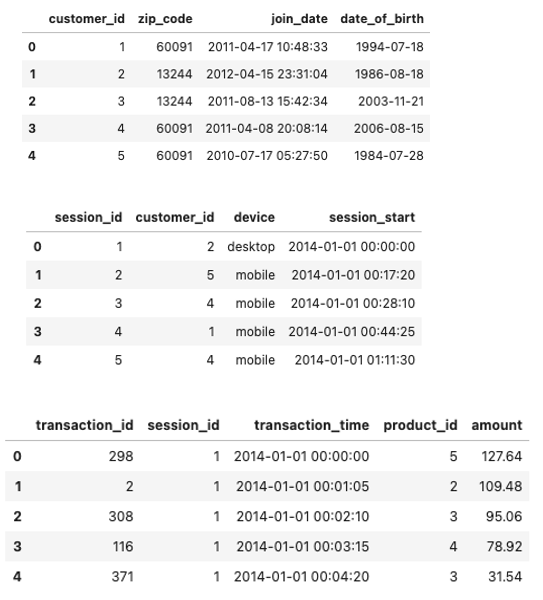
流れとしては、
1. EntitysetというER的なデータとデータ関係が入ったオブジェクトを作成
# EntitySetインスタンスの作成 es = ft.EntitySet(id='demo') # idはEntitySet名 # Entityとしてデータフレームを登録 es.entity_from_dataframe(entity_id='cust', # entity名 dataframe=data['customers'], # 登録するDF index='customer_id') # ユニークとなるためのindex es.entity_from_dataframe(entity_id='session', dataframe=data['sessions'], index='session_id', time_index='session_start') # 時系列で認識させたい場合 es.entity_from_dataframe(entity_id='trans', dataframe=data['transactions'], index='transaction_id', time_index='transaction_time')
その結果esは以下のような出力となる。
Entityset: demo
Entities:
cust [Rows: 5, Columns: 4]
session [Rows: 35, Columns: 4]
trans [Rows: 500, Columns: 5]
Relationships:
No relationships
見たままですが、demoという名前のEntitySetで、Entityとしてはcust, session, transの3つをもち、それぞれのshapeも書いてます。また、No relationshipsとあるように現段階ではEntityのひも付きはないので紐付けます
# relationの定義 # Relationship(親, 子)とする r_cust_session = ft.Relationship(es['cust']['customer_id'], es['session']['customer_id']) r_session_trans = ft.Relationship(es['session']['session_id'], es['trans']['session_id']) # 紐付け es.add_relationships(relationships=[r_cust_session,r_session_trans])
esをみると紐付けが完了してる
Entityset: demo
Entities:
cust [Rows: 5, Columns: 4]
session [Rows: 35, Columns: 4]
trans [Rows: 500, Columns: 5]
Relationships:
session.customer_id -> cust.customer_id
trans.session_id -> session.session_id
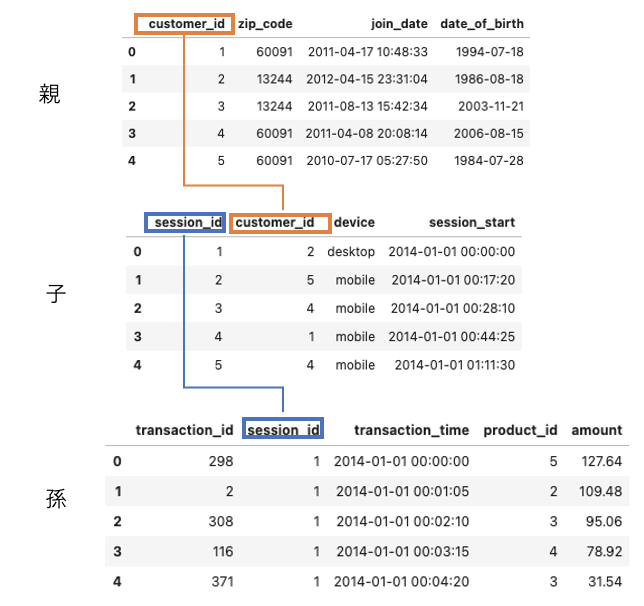
ちなみに、Entityの情報(列や型、shape)をみたり、DFで呼び戻したりは以下のようにしてできる
# Entityの情報を表示 es['cust'] # => # Entity: cust # Variables: # customer_id (dtype: index) # zip_code (dtype: categorical) # join_date (dtype: datetime) # date_of_birth (dtype: datetime) # Shape: # (Rows: 5, Columns: 4) # dfで戻す df_cust = es['cust'].df
集計/変換処理をする
本題。型や関係性に応じて集計や変換をする。Entityを横断的に集計処理をすることをDeep Feature Synthesis(DFS)というそうな。
DFS処理をするメソッドdfsを使う。返り値は集計結果のDFとそのDFの特徴量定義情報
# 適用したい集約関数 list_agg = ['sum','max','count'] # 適用したい変換関数 list_trans = ['year','day'] # run dfs df_feature, features_defs = ft.dfs(entityset=es, # 適用先entityset名 target_entity='cust', # 適用先entity agg_primitives=list_agg, # 適用集約関数 trans_primitives =list_trans, #適用変換関数 max_depth=1 #適用の深さ ) # head df_feature.head()
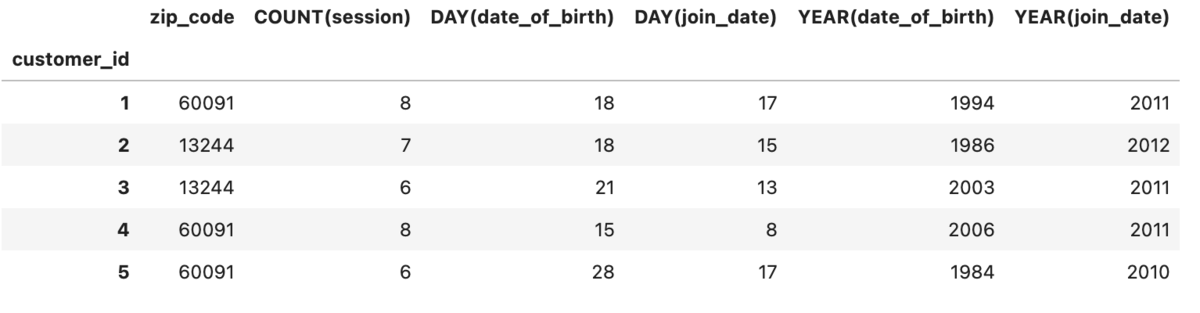
このとき、target_entityを起点にagg_primitivesはmax_depthの深さまで、trans_primitivesは自身に適用される。
今回target_entityは最上部のcustとなので、agg_primitivesのsum,max,countは子であるsessionテーブルのうちこれらが適用可能な列に適用され(数値がないためsum,maxは不使用で、sessionテーブルの行数countのみ適用される)、trans_primitivesのyear,dayは自身の適用可能な列に適用される。

次にmax_depth=2を考える。
# 適用したい集約関数 list_agg = ['sum','max','count'] # 適用したい変換関数 list_trans = ['year','day'] # run dfs df_feature, features_defs = ft.dfs(entityset=es, # 適用先entityset名 target_entity='cust', # 適用先entity agg_primitives=list_agg, # 適用集約関数 trans_primitives =list_trans, #適用変換関数 max_depth=2 #適用の深さ )
features_defsは以下。
features_defs => [<Feature: zip_code>, <Feature: COUNT(session)>, <Feature: COUNT(trans)>, <Feature: MAX(trans.amount)>, <Feature: SUM(trans.amount)>, <Feature: DAY(date_of_birth)>, <Feature: DAY(join_date)>, <Feature: YEAR(date_of_birth)>, <Feature: YEAR(join_date)>, <Feature: MAX(session.COUNT(trans))>, <Feature: MAX(session.SUM(trans.amount))>, <Feature: SUM(session.MAX(trans.amount))>]
trans_primitivesは自身のみのままだが、agg_primitivesの適用の深さが変わっている。
1. 深さ1(子)に対して自身の粒度で集計
2. 深さ2(孫)に対して自身の粒度で集計
3. 深さ1(子)粒度で深さ2(孫)を集計し、その値に対して自身の集計を更にかける(例: MAX(session.SUM(trans.amount))は孫のtrans.amountを子のsession(session_id)粒度でSUMをしてその後自身のcust(custmar_id)の粒度で集計している。

なお、primitives適用をした列以外の列は自身が持つ列以外は残らない模様(正確には、自身より上のレイヤーがある場合はmax_depthによっては紐づく)。
次に、target_entityを子にして同様のことをする。
まずは次にmax_depth=1
# run dfs df_feature, features_defs = ft.dfs(entityset=es, # 適用先entityset名 target_entity='session', # 適用先entity agg_primitives=list_agg, # 適用集約関数 trans_primitives =list_trans, #適用変換関数 max_depth=1 #適用の深さ ) # head df_feature.head()
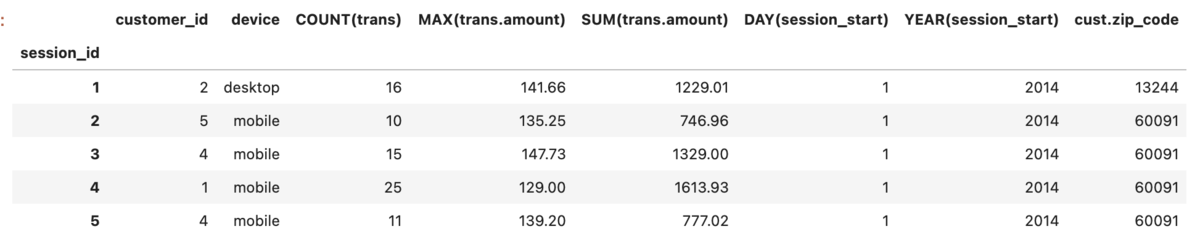
このとき、前回同様にtarget_entityであるsessionを起点にagg_primitivesはmax_depthの深さまで、trans_primitivesは自身に適用される。
注意する点としては
- max_depthは前後に効くので親と子ともに紐づく
- 自分より(max_depth内の)上位のテーブルの特徴量を取ってくる。
2.はcust.zip_codeが紐付いていることからそう判断しましたが、join_date date_of_birthを取ってこないのはなんでや。。。型によって取ってくるものと取ってこないものがあるのかも?
次にmax_depth=2
df_feature, features_defs = ft.dfs(entityset=es, # 適用先entityset名 target_entity='session', # 適用先entity agg_primitives=list_agg, # 適用集約関数 trans_primitives =list_trans, #適用変換関数 max_depth=2 #適用の深さ )
features_defs <Feature: customer_id>, <Feature: device>, <Feature: COUNT(trans)>, <Feature: MAX(trans.amount)>, <Feature: MIN(trans.amount)>, <Feature: SUM(trans.amount)>, <Feature: DAY(session_start)>, <Feature: MONTH(session_start)>, <Feature: YEAR(session_start)>, <Feature: cust.zip_code>, <Feature: cust.COUNT(session)>, <Feature: cust.COUNT(trans)>, <Feature: cust.MAX(trans.amount)>, <Feature: cust.MIN(trans.amount)>, <Feature: cust.SUM(trans.amount)>, <Feature: cust.DAY(date_of_birth)>, <Feature: cust.DAY(join_date)>, <Feature: cust.MONTH(date_of_birth)>, <Feature: cust.MONTH(join_date)>, <Feature: cust.YEAR(date_of_birth)>, <Feature: cust.YEAR(join_date)>]
<Feature: cust.COUNT(session)>以下が差分。
正直わっかんねーなーってとこはあるんですが、自分より上に対してもtrans_primitives agg_primitivesが適用されている(厳密には、上に対してtrans_primitivesが適用&上の粒度でそれより下に対してagg_primitivesで集約される?)。そこから考えるに、
trans_primitivesは自身か自身より上に適用。ただし自身以上の場合は1遅延がある(深さ2なら、2-1=1上まで)?agg_primitivesは自身より下か自身より上に適用。ただし自身以上の場合は1遅延がある(深さ2なら、2-1=1上まで)?
といったところでしょうか?まぁ正直挙動がわかりづらいんですが、基本的に最上位層をtarget_entityにして分析することがほとんどだと思うのでそこまで気にしなくていいのかも。
1テーブルのデータで試す
ボストンの住宅価格情報データセットBoston Housingを使う。
詳細は以下
import pandas as pd import numpy as np from sklearn.datasets import load_boston boston = load_boston() df_X = pd.DataFrame(boston.data, columns=boston.feature_names) df_y = pd.DataFrame(boston.target, columns=['target']) # 年齢を四捨五入したものを追加 df_X['AGE2'] = df_X['AGE'].round(-1)
こちらは特に複数テーブルがあるわけではないので、自らマスタデータのようなものを作る必要がある。
# EntitySetインスタンスの作成 es = ft.EntitySet(id='Boston') # idはEntitySet名 # Entityとしてデータフレームを登録 es.entity_from_dataframe(entity_id='features', # entity名 dataframe=df_X, # 登録するDF index='index') # ユニークとなるためのindex
DFSをするにはrelationが必要だがこのままではrelationがないので、集約したい列のマスタテーブルのようなものをつくり紐付ける。これはnormalize_entityでできる。
es = es.normalize_entity(base_entity_id='features', new_entity_id='age2', index='AGE2', ) # Entityset: Boston # Entities: # features [Rows: 506, Columns: 15] # age2 [Rows: 11, Columns: 1] # Relationships: # features.AGE2 -> age2.AGE2
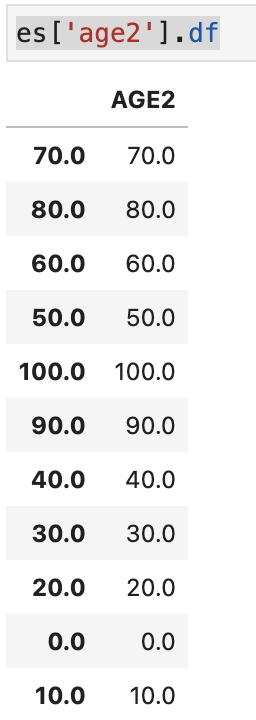
list_agg = ['sum','max','count'] list_trans = ['subtract_numeric', 'multiply_numeric'] # 減算/乗算の組み合わせ # run dfs df_feature, features_defs = ft.dfs(entityset=es, # 適用先entityset名 target_entity='features', # 適用先entity agg_primitives=list_agg, # 適用集約関数 trans_primitives =list_trans, #適用変換関数 max_depth=2 #適用の深さ ) # 特徴量 features_defs
デモデータでは集計値に対して更に集計していたが、こちらでは変換したものに対しての集計がおこなわれている。
そのため、総じて言えばmax_depthを深くするとその手前の深さの処理(集約や変換)に対しても更に集約が走ると捉えれる。
[<Feature: CRIM>, <Feature: ZN>, <Feature: INDUS>, <Feature: CHAS>, <Feature: NOX>, <Feature: RM>, <Feature: AGE>, <Feature: DIS>, <Feature: RAD>, <Feature: TAX>, <Feature: PTRATIO>, <Feature: B>, <Feature: LSTAT>, <Feature: AGE2>, <Feature: AGE * B>, <Feature: AGE * CHAS>, <Feature: AGE * CRIM>, <Feature: AGE * DIS>, <Feature: AGE * INDUS>, <Feature: AGE * LSTAT>, <Feature: AGE * NOX>, <Feature: AGE * PTRATIO>, <Feature: AGE * RAD>, <Feature: AGE * RM>, <Feature: AGE * TAX>, <Feature: AGE * ZN>, <Feature: B * CHAS>, <Feature: B * CRIM>, <Feature: B * DIS>, <Feature: B * INDUS>, <Feature: B * LSTAT>, <Feature: B * NOX>, <Feature: B * PTRATIO>, <Feature: B * RAD>, <Feature: B * RM>, <Feature: B * TAX>, <Feature: B * ZN>, <Feature: CHAS * CRIM>, <Feature: CHAS * DIS>, <Feature: CHAS * INDUS>, <Feature: CHAS * LSTAT>, <Feature: CHAS * NOX>, <Feature: CHAS * PTRATIO>, <Feature: CHAS * RAD>, <Feature: CHAS * RM>, <Feature: CHAS * TAX>, <Feature: CHAS * ZN>, <Feature: CRIM * DIS>, <Feature: CRIM * INDUS>, <Feature: CRIM * LSTAT>, <Feature: CRIM * NOX>, <Feature: CRIM * PTRATIO>, <Feature: CRIM * RAD>, <Feature: CRIM * RM>, <Feature: CRIM * TAX>, <Feature: CRIM * ZN>, <Feature: DIS * INDUS>, <Feature: DIS * LSTAT>, <Feature: DIS * NOX>, <Feature: DIS * PTRATIO>, <Feature: DIS * RAD>, <Feature: DIS * RM>, <Feature: DIS * TAX>, <Feature: DIS * ZN>, <Feature: INDUS * LSTAT>, <Feature: INDUS * NOX>, <Feature: INDUS * PTRATIO>, <Feature: INDUS * RAD>, <Feature: INDUS * RM>, <Feature: INDUS * TAX>, <Feature: INDUS * ZN>, <Feature: LSTAT * NOX>, <Feature: LSTAT * PTRATIO>, <Feature: LSTAT * RAD>, <Feature: LSTAT * RM>, <Feature: LSTAT * TAX>, <Feature: LSTAT * ZN>, <Feature: NOX * PTRATIO>, <Feature: NOX * RAD>, <Feature: NOX * RM>, <Feature: NOX * TAX>, <Feature: NOX * ZN>, <Feature: PTRATIO * RAD>, <Feature: PTRATIO * RM>, <Feature: PTRATIO * TAX>, <Feature: PTRATIO * ZN>, <Feature: RAD * RM>, <Feature: RAD * TAX>, <Feature: RAD * ZN>, <Feature: RM * TAX>, <Feature: RM * ZN>, <Feature: TAX * ZN>, <Feature: AGE - B>, <Feature: AGE - CHAS>, <Feature: AGE - CRIM>, <Feature: AGE - DIS>, <Feature: AGE - INDUS>, <Feature: AGE - LSTAT>, <Feature: AGE - NOX>, <Feature: AGE - PTRATIO>, <Feature: AGE - RAD>, <Feature: AGE - RM>, <Feature: AGE - TAX>, <Feature: AGE - ZN>, <Feature: B - CHAS>, <Feature: B - CRIM>, <Feature: B - DIS>, <Feature: B - INDUS>, <Feature: B - LSTAT>, <Feature: B - NOX>, <Feature: B - PTRATIO>, <Feature: B - RAD>, <Feature: B - RM>, <Feature: B - TAX>, <Feature: B - ZN>, <Feature: CHAS - CRIM>, <Feature: CHAS - DIS>, <Feature: CHAS - INDUS>, <Feature: CHAS - LSTAT>, <Feature: CHAS - NOX>, <Feature: CHAS - PTRATIO>, <Feature: CHAS - RAD>, <Feature: CHAS - RM>, <Feature: CHAS - TAX>, <Feature: CHAS - ZN>, <Feature: CRIM - DIS>, <Feature: CRIM - INDUS>, <Feature: CRIM - LSTAT>, <Feature: CRIM - NOX>, <Feature: CRIM - PTRATIO>, <Feature: CRIM - RAD>, <Feature: CRIM - RM>, <Feature: CRIM - TAX>, <Feature: CRIM - ZN>, <Feature: DIS - INDUS>, <Feature: DIS - LSTAT>, <Feature: DIS - NOX>, <Feature: DIS - PTRATIO>, <Feature: DIS - RAD>, <Feature: DIS - RM>, <Feature: DIS - TAX>, <Feature: DIS - ZN>, <Feature: INDUS - LSTAT>, <Feature: INDUS - NOX>, <Feature: INDUS - PTRATIO>, <Feature: INDUS - RAD>, <Feature: INDUS - RM>, <Feature: INDUS - TAX>, <Feature: INDUS - ZN>, <Feature: LSTAT - NOX>, <Feature: LSTAT - PTRATIO>, <Feature: LSTAT - RAD>, <Feature: LSTAT - RM>, <Feature: LSTAT - TAX>, <Feature: LSTAT - ZN>, <Feature: NOX - PTRATIO>, <Feature: NOX - RAD>, <Feature: NOX - RM>, <Feature: NOX - TAX>, <Feature: NOX - ZN>, <Feature: PTRATIO - RAD>, <Feature: PTRATIO - RM>, <Feature: PTRATIO - TAX>, <Feature: PTRATIO - ZN>, <Feature: RAD - RM>, <Feature: RAD - TAX>, <Feature: RAD - ZN>, <Feature: RM - TAX>, <Feature: RM - ZN>, <Feature: TAX - ZN>, <Feature: age2.COUNT(features)>, <Feature: age2.MAX(features.AGE)>, <Feature: age2.MAX(features.B)>, <Feature: age2.MAX(features.CHAS)>, <Feature: age2.MAX(features.CRIM)>, <Feature: age2.MAX(features.DIS)>, <Feature: age2.MAX(features.INDUS)>, <Feature: age2.MAX(features.LSTAT)>, <Feature: age2.MAX(features.NOX)>, <Feature: age2.MAX(features.PTRATIO)>, <Feature: age2.MAX(features.RAD)>, <Feature: age2.MAX(features.RM)>, <Feature: age2.MAX(features.TAX)>, <Feature: age2.MAX(features.ZN)>, <Feature: age2.SUM(features.AGE)>, <Feature: age2.SUM(features.B)>, <Feature: age2.SUM(features.CHAS)>, <Feature: age2.SUM(features.CRIM)>, <Feature: age2.SUM(features.DIS)>, <Feature: age2.SUM(features.INDUS)>, <Feature: age2.SUM(features.LSTAT)>, <Feature: age2.SUM(features.NOX)>, <Feature: age2.SUM(features.PTRATIO)>, <Feature: age2.SUM(features.RAD)>, <Feature: age2.SUM(features.RM)>, <Feature: age2.SUM(features.TAX)>, <Feature: age2.SUM(features.ZN)>]
参考
*1:精度が悪くなったりオーバーフィッティングに繋がることもあったり、シチュエーションによっては多重共線性が問題になったりすることもあるがいったん置いとく
楽にEDA初手ができそうなSweetvizメモ
EDA初手としてpandas_profilingが有名だがデータ数が多いとめちゃくちゃ時間がかかるのであまり好きではない。
Sweetvizが高速かつ、データ比較もできるようなので雑に試す。
1データの場合
import sweetviz as sv my_report = sv.analyze(df) my_report.show_html() # Default arguments will generate to "SWEETVIZ_REPORT.html"
2データの場合
import sweetviz as sv my_report = sv.compare([train_data, 'Train'], [test_data, 'Test']) my_report.show_html() # Default arguments will generate to "SWEETVIZ_REPORT.html"
1データの場合はanalyze 2データの場合はcompare。出力される項目は(2グラフになる以外は)上記だと同じ。
compare_intraメソッドを使うと 1つのデータを特定列の値でサブセットに分けて比較できる。
なお、以下の記事がpandas_profilingとの比較を書いてくれてる。
Shapashで機械学習モデルの挙動を可視化する
記事の目的
前回の記事ではShapashと同様に機械学習モデルの挙動を楽に可視化するEvidentlyを紹介した。
記事中でShapashについても軽く触れたが使用用途としては以下のような違いがある。
Evidentlyはモデルの振る舞いを、推定元データ観点でどうなっているかを中心として可視化し、それに付随してモデル/推定元データの比較をします。
ShapashはSHAPおよびLIMEを用いて、モデルにおける特徴量の寄与がどうなっているか、つまりモデルが何故そういう振る舞いをしているかを中心として可視化している。つまり、前者はモデルの挙動をデータから確認する用途で、後者はモデルの推定結果の原因を確認する用途なので用途が異なっている(データを中心に見ていくか、結果を中心に見ていくか、とも言える)。
また、Evidentlyはデータを中心に確認するので『モデルアルゴリズムによるデータ内(特徴量毎など)での精度差異』『推定元データの違い(異なる地域や時期など)による精度差異』を見たい場合に役に立つため予測データを2つ渡し比較する機能を持っている。
このように、モデルが何故そういう振る舞いをしているか把握できるShapashについて記載する。
なお、概要は以下の記事が端的にまとまっているので、追加で調べたことを中心に記載していく。
何が表示できるか
ShapashはEvidently同様に、ダッシュボードをhtml出力する形式と、見たい項目(グラフ)を個別に指定して出力する2つの出力形式に分かれる。
前者はいくつかのグラフ項目が一画面で表示されているので、各項目の一部を選択するとその選択に連動して他の項目の表示が変わる。後者には個別でグラフ項目を出力するので、あるインスタンスに対しての挙動を見たい場合は出力時に指定が必要になる一方で、前者に含まれていない項目も出力することができる。
また、モデルやデータの要約量なども併せてレポートとして出力をすることもできる。
データ準備
Evidentlyのときに作成したモデルをそのまま使う。具体的には、IBMの従業員退職予測予想データを使った以下のNotebookのIn [34](データの前処理およびRandomForestモデルの学習)まで。
そのため以下でおこなう可視化は分類モデルについての可視化になるが、連続値への予測でもほぼ同様の解釈ができるので確率値/ラベルは連続値として置き換えて読んでください。
出力準備
ダッシュボードやレポート、解釈用の個別グラフなりを出力する前にSmartExplainerを用いて、出力の型となるインスタンス(xplオブジェクト)を作成する。この際、目的変数のラベルをオプションで指定する。
from shapash.explainer.smart_explainer import SmartExplainer response_dict = {0: 'no', 1:'yes'} xpl = SmartExplainer( label_dict=response_dict # 結果ラベルを指定 )
作成したインスタンスに対して、解釈をしたいモデルと推定結果、推定に用いた特徴量を渡してコンパイルする。
test_probas = pd.DataFrame(rf.predict(test_data[features]),
columns=['pred'],
index=test_data.index)#.astype(int)
xpl.compile(
x=test_data[features],
model=rf,
y_pred=test_probas
)
以上で、挙動を出力するためのオブジェクトができたのであとはこのインスタンスにメソッドを使っていじっていく。
なお、このときのモデルはscikitlearn系であればTree系以外のモデルでも使えるっぽいです。内部的にはアルゴリズムに依存しない手法のShapだからまぁそうなんでしょうが、おそらくscikitlearn準拠モデルであれば、といった感じでしょうか(試してないので推測)。
ダッシュボードと個別出力
app = xpl.run_app() を走らせると Dash is running on http://0.0.0.0:8050/のような出力がされ、(port番号8050は人に依る)ローカルホストが立ち上がりダッシュボードが描写される。この http://0.0.0.0:8050/ に飛ぶと以下のように表示される(番号は説明用にこちらでつけた)。
なお雰囲気を知りたい場合は、公式のデモで実際に触れる。
また、以下のように各ダッシュボード要素+αを個別画像として出力することもできる。
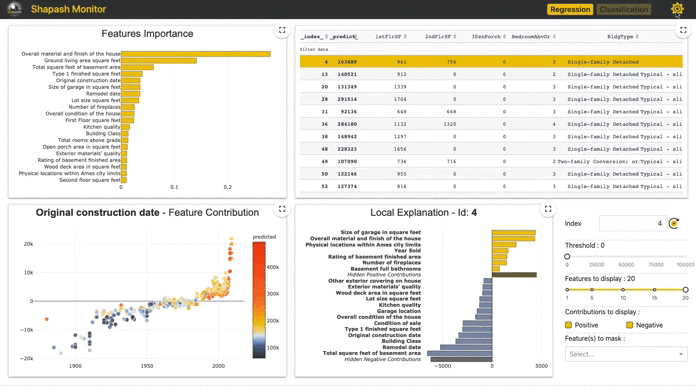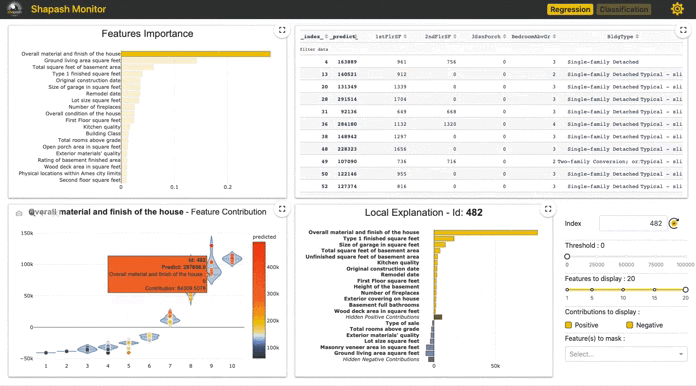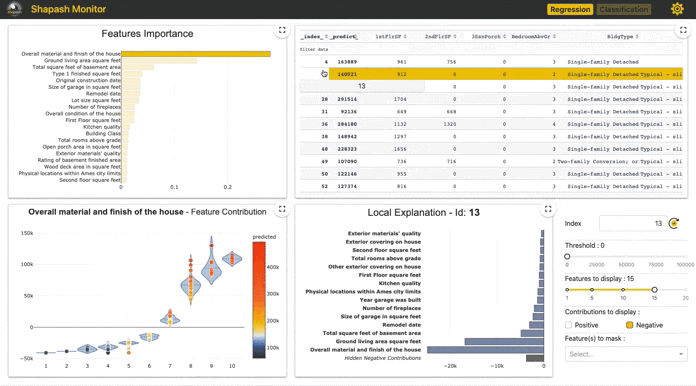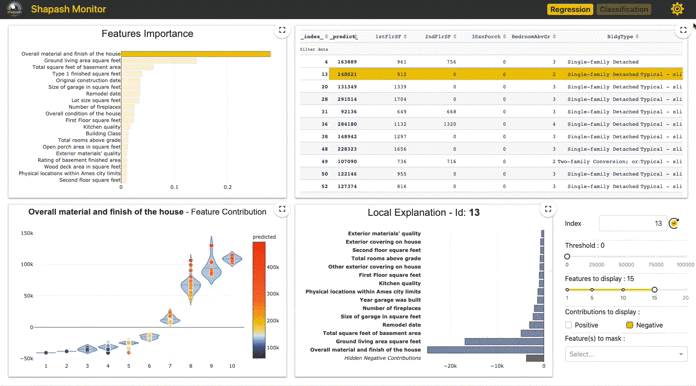
①Feature Importance
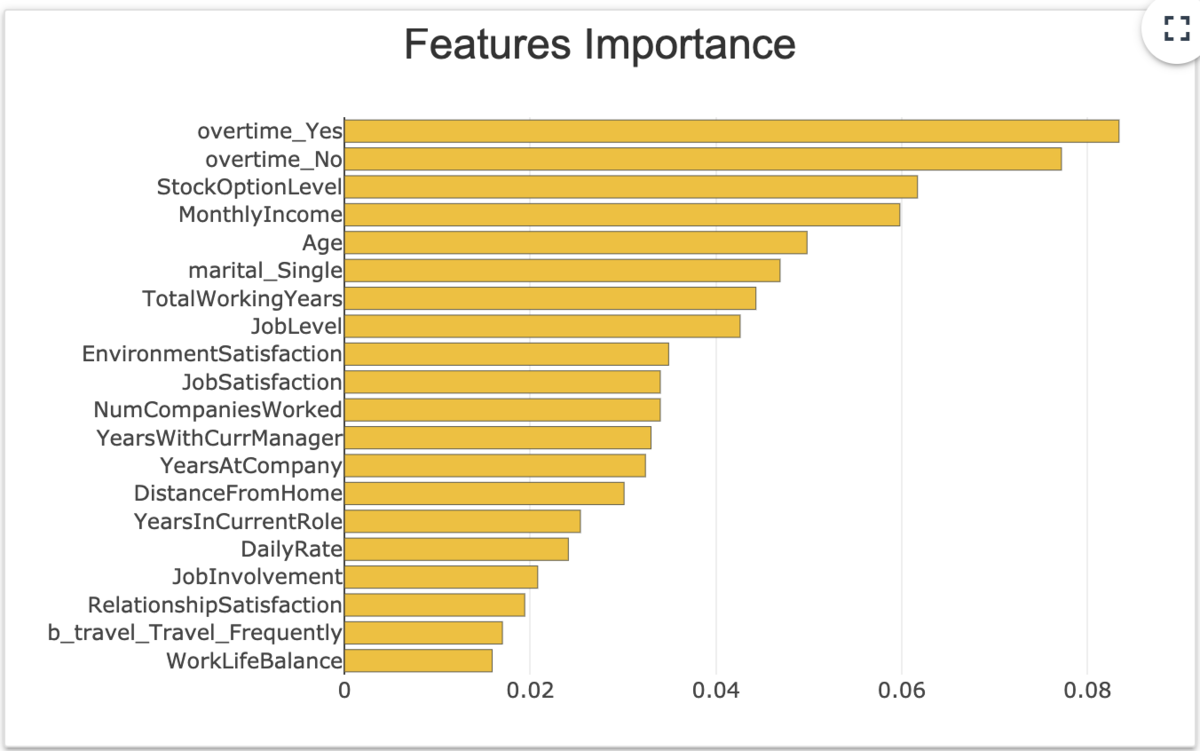
モデルにおける変数重要度を表示している。
以下で個別出力ができる。
xpl.plot.features_importance()
このとき、max_featuresで表示数の指定ができる。また、selectionで指定したidのインスタンスだけでの変数重要度を見ることができる。
ひとえに変数重要度といっても、例えばtree系であればGainベースやsplitベースなど色々な計算方法がある。
例えばLightGBMのlightgbm.plot_importanceだとimportance_typeオプションで指定ができる。
ここで表示されているのは後に紹介するShap valueの絶対値平均*1なのかなーって気がします。ドキュメント読んでも明言されてない((あえていうならFeatures importances sum and display the absolute contribution for one target modalityか?))ので断定できないですが、shapashはSHAPを中心に色々出してたり、モデル依存の重要度じゃなさそうだったり、ローカル指定ができたりということからも可能性としては高そう。
②Feature Contribution
①で選択された特徴量はマクロで見た各特徴量の重要値となります。一方ここでは、各インスタンス個別での特徴量の貢献がどうなっているかを全インスタンスに対して可視化がされます。なお、ここでの貢献度(Contribution)は実際の予測確率を分解した値となり、あるインスタンスに対して他の特徴量も含めて分解値を一覧表示したものが後に紹介する④となります。ここの図中の点は各インスタンスを表しており点をクリックするとそのインスタンスに対する④が表示されます。
このときカテゴリカル変数の場合はバイオリンプロットで可視化がされます。
なお、 xpl.compileの際にy_pred(予測確率)を渡しているか、addメソッドでy_predを追加で渡している場合にバイオリンは、青色はy_predが0.5未満、オレンジ色はy_predが0.5以上のインスタンスに分けてバイオリン表示が行われます。
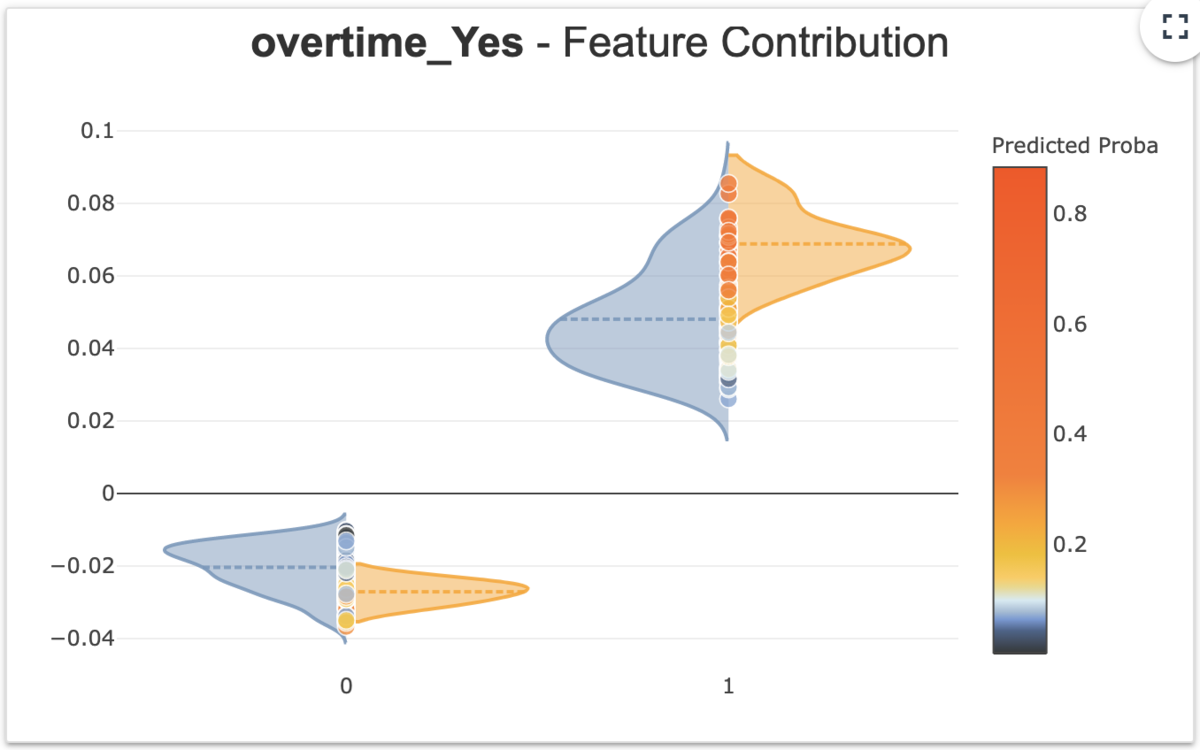
y_predを渡さない場合は全インスタンスの密度をまとめてバイオリンとして表示します。

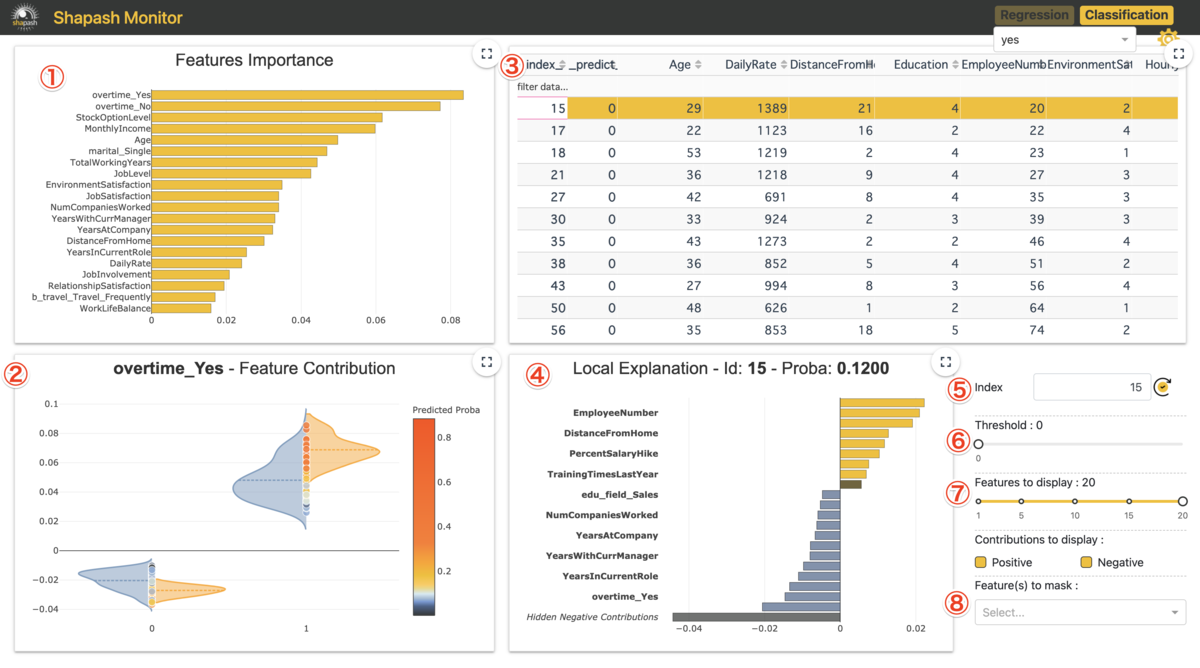
まとめた方のバイオリンをみるとovertime(残業をしているか)が0と1で貢献に対して明確に差が出ています。
予測結果が1/0(オレンジ/青)毎に分けてみると、overtimeが1ではオレンジなほど貢献が高いが、青では幅広い分布となっています。
解釈としては、残業をしている人ほど在籍に対して正の貢献がありその中でも在籍している人ほどその傾向があります。つまり、(因果の向きは置いておくとして)残業をしている人は在籍している可能性が高くなり、残業していない人ほど離職をしていることになります。これはちょっとドメイン知識に照らし合わせると違和感があるのですが、例えば役職者だと在籍しやすくなるけど残業がある、みたいなことが反映されているのだろうか。。。
次に、連続値の場合は以下のように散布図で表示されます。

Ageは①をみると全体としては5番目に重要と出ていますが、この図をみると20代のインスタンスでは若年ほどAgeは予測への貢献が高く徐々に貢献が減っていき30歳になるにつれ貢献が0になっていく傾向がみれます。その後は40歳にかけてやや負の貢献が増加していき60歳に近づくほど再度貢献が0になっていく傾向がみれます。
実際予測対象の「会社に在籍しているか」をドメイン知識から考えると20代前半は多くの人は転職をせずその会社にいますが、30歳に近づくにつれ転職をする人が増える傾向にあると思われます。そのときに、新卒1,2年目では「まだ新卒1,2年目だから(23,24歳だから)転職をしない」といったことが機能しますが、30歳に近づくにつれ「様々な要因によって転職をするかどうか」を判断することになるように思えます。つまり、在籍しているかどうかは20歳前半では年齢を理由に在籍をするが、30歳に近づくにつれ年齢以外の様々な要因によって変わっていく(=年齢の在籍への貢献度が相対的に落ちる)ということになります。
これはあくまで私の「年齢に対する在籍へのドメイン知識」ですが、これと似たようなことが結果として図に表れています。
それぞれ個別で出す場合は以下
# カテゴリカル変数 # y_predあり xpl = SmartExplainer( label_dict=response_dict # 結果ラベルを指定 ) xpl.compile( x=test_data[features], model=rf, #y_pred=test_probas ) xpl.add(y_pred=test_probas) #addで渡してもいいし、compile時に指定してもよい xpl.plot.contribution_plot("overtime_Yes")

# カテゴリカル変数 # y_predなし xpl = SmartExplainer( label_dict=response_dict # 結果ラベルを指定 ) xpl.compile( x=test_data[features], model=rf, #y_pred=test_probas ) xpl.plot.contribution_plot("overtime_Yes")

# 連続値 xpl.plot.contribution_plot("Age")

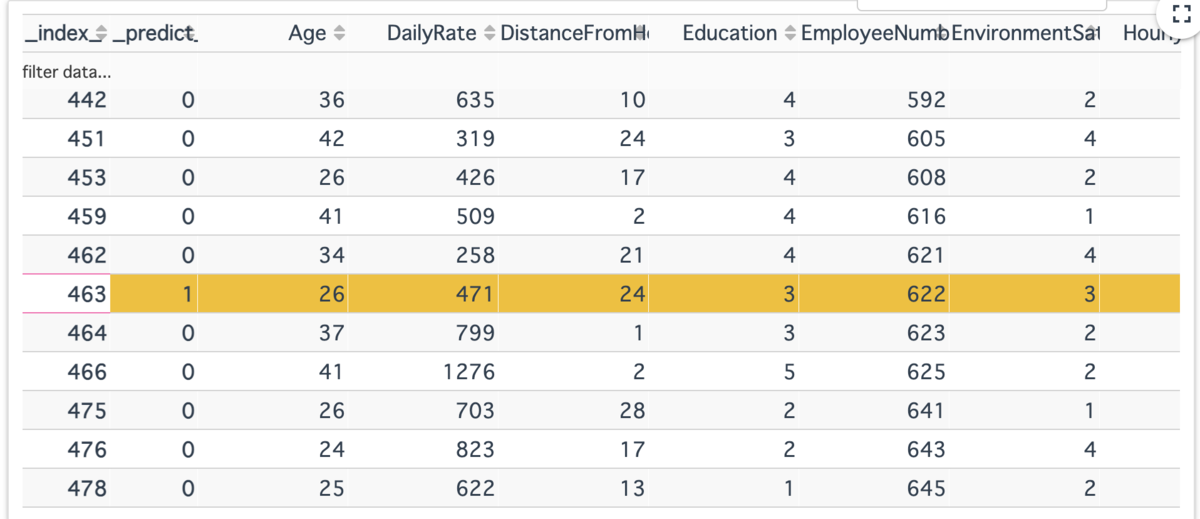
③実データテーブル
推定対象についての予測と特徴量がテーブルで表示されます(predictは閾値0.5で変換?)
ここであるインスタンスの行をクリックすると④でそのインスタンスについての予測値が分解された各特徴量の貢献度が表示されます。
④Local Plot
あるインスタンスに対しての予測確率を各特徴量で分解した値を貢献度として表示しています。 インスタンスの選択はm,②で点をクリック、③で行をクリック、⑤でid指定のいずれかで指定できます。
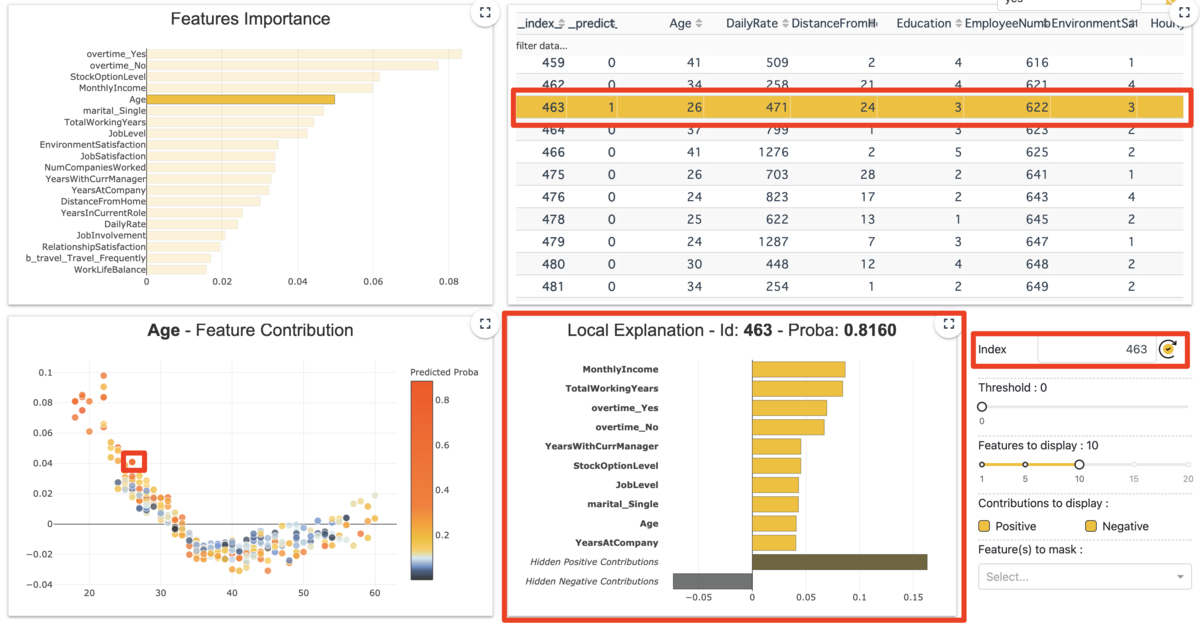
なお、ここでの貢献値は正の場合は「確率を高める」要素として、負の場合は「確率を低める」要素として解釈できます。
図中にあるID463インスタンスは予測確率は0.8160となり、その内訳がこの図となっています。つまり、この棒グラフの値を全て合算すると予測確率の0.8160となります。
この図の右にある⑤~⑧はこの図の制御に使います。
⑤は前述のようにidの指定、⑥は表示される寄与絶対値の最低値(分類タスクだと固定?)、⑧で指定した特徴量を表示から消せます。
なお、⑦で表示する特徴量数を制御でき、一定数にするために絶対値が低い特徴量は正負別にまとめて表示(値は総和)されます(Hidden Positive/Negative 。Contributions)。
このID463インスタンスではMontlyIncomeが最も正に貢献している特徴量となっているようです。
個別画像の場合以下。
xpl.plot.local_plot(index=463)
また、filterメソッドを使用して、⑤~⑧に相当する挙動をおこなうこともできる。max_contribで特徴量数、thresholdで表示値の閾値。一度filterを使うとlocal_plotは常にfilter後の状態になるようなので注意。
なお、表示数が少なくなるとそのインスタンスの実際の値が特徴量名の下に表示される模様。
xpl.filter(threshold=0.06, positive=True) xpl.plot.local_plot(index=463, show_masked=False)
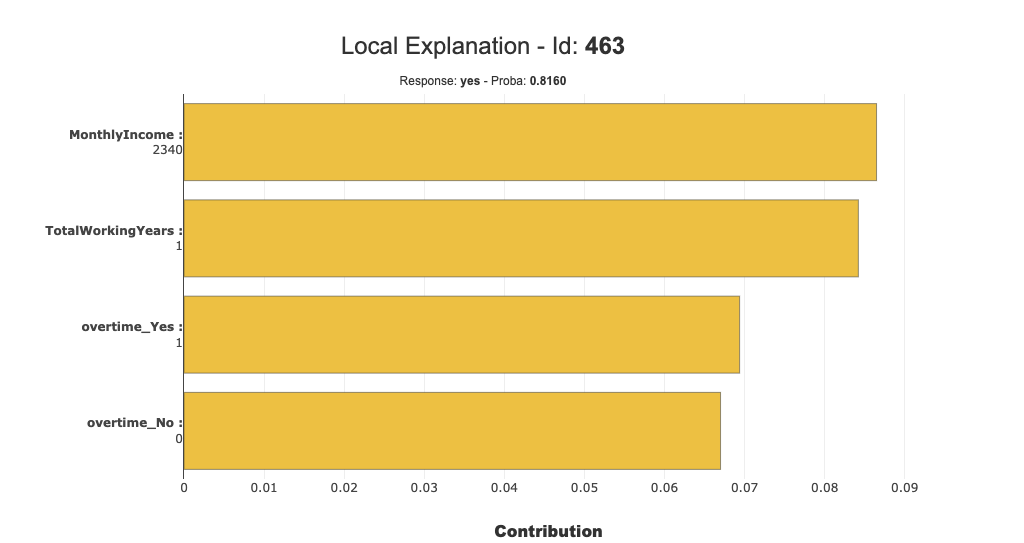
Local Plotの今のxpl状態(filterをしている場合はfilter後の状態)で全インスタンスの情報をテーブルで欲しい場合はto_poandas
df = xpl.to_pandas(proba=True)
df.head()

ダッシュボードの停止
app.kill()でローカルホストを停止できる。
ダッシュボードで表示されてない個別のみ表示できるグラフ
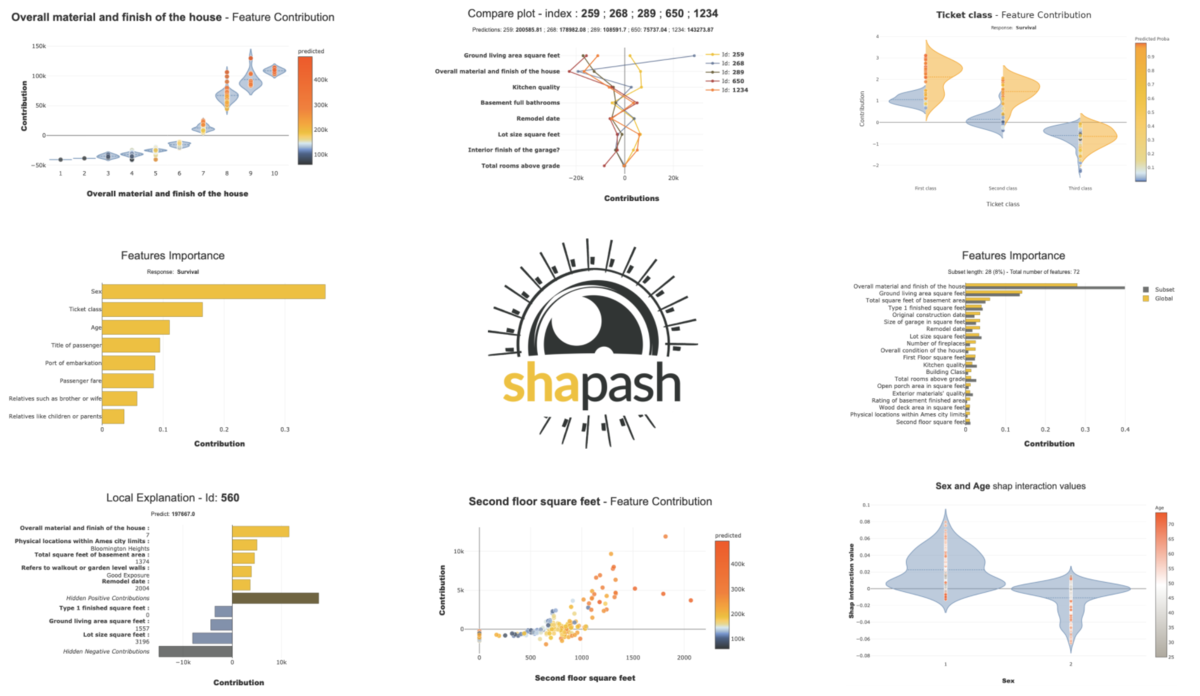
Compare_plot
④Local Plotを複数インスタンスで比較したい場合compare_plotメソッドを使う。
xpl.plot.compare_plot(index=[688,422,630])

この例ではAgeがほぼ同じだがProbasが大きく異なるidを選んでいる。

id688(prob:0.88)とid630(prob:0.22)のみで比較してみると、例えばMonthlyIncomeはid688では大きく正に寄与だがid630では負に寄与となっていて(実際の値は前者は2121、後者は4775)、これが予測確率の差の一員となっている。
ここで使っている理論
Shapashでは主にSHAPと呼ばれる手法を用いて算出した結果を可視化しているようです。
SHAPの詳細は以下の記事がわかりやすいです。
なお、私も昔記事に書きました。
レポート
以下の情報をhtmlとして出力する。
- プロジェクトに関する一般情報
- 使用したデータセットの説明
- データの準備とフィーチャリングに関する文書
- 使用したモデルの詳細(ライブラリやパラメータなど)
- 訓練セットとテストセットの違いに焦点を当てたデータの探索
- モデルの全体的な説明可能性(ダッシュボードのうちグローバルな内容(①Feature Importance②Feature Contribution)
- モデルのパフォーマンス
なお雰囲気を知りたい場合は、公式のサンプルレポートを見れる。
はじめの3つは以下のサンプルのように記載したymlファイルを作成して色々と書いてから渡す必要があるが、それ以外は自動で生成してくれる。
作成はgenerate_reportメソッドを使う。
xpl.generate_report(
output_file='output/report.html',
project_info_file='utils/project_info.yml',
x_train=test_data,
y_train=train_y,
y_test=test_y,
title_story="IBM HR analytics",
title_description="""IBM HR analyticsのShapashテスト""",
metrics=[
{
'path': 'sklearn.metrics.f1_score',
'name': 'F1 Score',
},
{
'path': 'sklearn.metrics.precision_score',
'name': 'precision',
}
]
)
*1:あるいは、そこから更にそれらの合計を1.0にするように変換
Evidentlyで機械学習モデルの挙動を可視化する
背景
機械学習モデルは作成後にそのモデルがどのような振る舞いをするのか調べる必要がある。
理由としては
実運用上での注意点
例えば、「このモデルは全体としてはそこそこの精度だが、20代では精度があまり良くない」といったことを把握しておくと実運用ではその点を注意して運用することができる。パフォーマンス向上のヒント
例えば、前述のように「20代で精度があまり良くない」のであればそれをカバーできそうな特徴量がないか?という観点で特徴量を考えることができたり、分布を見ることでうまいvalidationの取り方になってるか確認することができる。精度のモニタリングと原因探索
例えば、ある店舗の売上予測モデルを作成して毎月そのモデルを使って予測をおこなっているとする。そのときにある時期を堺に精度がガクッと落ちた場合、振る舞いをもとになにが原因で精度が落ちたかを探索する必要があり、その原因をもとに改修をしたり再学習をする必要がある。
このように、モデルを作成した後に振る舞いをみるのは重要だが自分で可視化していくのは地味に面倒。
その手間をEvidentlyでは解決してくれる。

このあたりの、なんで振る舞いを見る必要があるのん?ということに関してはEvidentlyの公式ブログにMachine Learning Monitoringシリーズとして載っているので一読すると良さげ
何ができるか
挙動確認用のサンプルコードは公式ブログから取得できる。
出力できるレポートの種類は以下があり、主にDrift系とPerformance系に分かれる。
それぞれにおいて具体的にどのようなレポートが出力されるかは公式ドキュメントのREPORTS項目を見ると良い(以下リンクはData Drift)。
Drift
Drift系では使用しているデータに関して見ることができ、レポートの種類としては以下がある。
- Data Drift
- Numerical Target Drift
- Categorical Target Drift
Data Driftでは、データセットの各特徴量の分布の可視化および、統計的に分布に差があるかの確認ができる。
Numerical/Categorical Target Driftは予測対象となる目的変数データを見ることができる。
各レポートの種類は連続値がカテゴリカルか(つまり連続値予測か分類予測か)によって使い分ける。
なお、 データの分布比較に関してはSweetvizも使えるがこっちの方が色々リッチ。
使用シチュエーション
- データのモニタリング 予測対象のデータの質が変わっていないかモニタリング
- モデルの再学習前
新しいデータで学習する前に、意味がありそうか検証 - 予測対象データを変えたときのパフォーマンスの減衰をデバッグするとき
何が変わったのか/原因かを確認 - モデルの挙動を知りたい
モデル出力の変化や、特徴と予測の関係を確認
Performance
Performance系は以下があり、モデルの予測結果を見ることができる。 各レポートの種類は予測対象となるデータの種類によって使い分ける。
- Regression Performance
- Classification Performance
- Probabilistic Classification Performance
なお、Classification PerformanceとProbabilistic Classification Performanceは前者は確率値を持たない場合に使う。確率値をもつ場合は前者の内容+確率に基づくレポートが入る後者を使う。
ただし、コードを読む感じだと後者は二値分類だと閾値を0.5としてクラス予測をしているようなので、後者を使う際のModel Quality Summary Metrics やConfusion Matrixといった前者と共通の部分(予測クラスも含めて計算してる箇所)は注意が必要。
任意の閾値を使いたい場合はそこだけ任意の閾値でクラス変換後に前者で見るとか、ProbClassRefConfMatrixWidgetクラスのcalculateをオーバーライドする必要がある。
使用シチュエーション
- testデータを使ったモデルの振る舞いをみる
testデータとtrainデータの推定結果と対比させることでモデルの振る舞いをみる。当たり前だが、trainデータの推定は学習時と同じデータなのでリークしており精度は良いはずだが、めっちゃ予測がうまくいくデータでどれくらいの精度なのか。testとの差はどれくらいなのか。trainでもうまく予測できない(学習しきれてない)ようなインスタンスや特徴量範囲はどのような部分なのかといったことを知ることができる(このあたり、他に見れる観点があれば教えてください)。 - モデルのパフォーマンスに関するレポートを作成
このレポートを定期的なジョブとして実行し、パフォーマンスをトラッキングして他の関係者と共有する。 - 異なるデータのモデルのパフォーマンスを分析
trainに使っているデータと異なるデータソースの場合どれくらいパフォーマンスが変わるかを調べる(例:trainを東京のユーザーでおこない、testとして東京のユーザーと大阪のユーザーでパフォーマンスがどれくらい変わるか比較)。 - モデルの再トレーニングを決める
2のようにパフォーマンスをトラッキングすることである一定以上の精度以下になったときに再学習をかける、という判断をする - エラーの多い領域を特定し、モデルのパフォーマンスを改善
エラーバイアステーブルを使用して、エラー全体に大きく寄与しているグループや、モデルがターゲット関数を過小評価または過大評価しているグループを特定する。
Shapashとの比較
なお、2020/12にv1が出たEvidentlyとほぼ同時期の2021/01にv1が出たShapashというダッシュボードライブラリも「機械学習モデルがどうなっているか」を楽に可視化してくれる(Shapashは日本でも結構取り上げられてるがEvidentlyはあまり取り上げられてない?)
Evidentlyはモデルの振る舞いを、推定元データ観点でどうなっているかを中心として可視化し、それに付随してモデル/推定元データの比較をします。
ShapashはSHAPおよびLIMEを用いて、モデルにおける特徴量の寄与がどうなっているか、つまりモデルが何故そういう振る舞いをしているかを中心として可視化している。
つまり、前者はモデルの挙動をデータから確認する用途で、後者はモデルの推定結果の原因を確認する用途なので用途が異なっている(データを中心に見ていくか、結果を中心に見ていくか、とも言える)。
また、Evidentlyはデータを中心に確認するので『モデルアルゴリズムによるデータ内(特徴量毎など)での精度差異』『推定元データの違い(異なる地域や時期など)による精度差異』を見たい場合に役に立つため予測データを2つ渡し比較する機能を持っている。
挙動確認
今回は試しに、分類モデルの予測確率に関してのProbabilistic Classification Performanceを見てみる。
このデータを使った公式でのチュートリアルは以下(英語に抵抗がないならこれ読めば概ねなにができるかわかる)。本記事ではこのnotebookのRandomForestモデルをreferenceモデル、CatBoostモデルをcurrentモデルとして比較した結果を見ていく。
データはKaggleのIBM HR Analytics Employee Attrition & Performanceという、従業員が退職するかどうかを予測するコンペデータを使用している模様。
データの日本語説明
レポート用のデータ準備
レポート出力には以下のオブジェクトが必要になる
- referenceとなるモデルを用いた予測結果(今回の場合、予測結果yesの確率とnoの確率それぞれ) + 実際の目的変数 + 特徴量
- currentとなるモデルを用いた予測結果(今回の場合、予測結果yesの確率とnoの確率それぞれ) + 実際の目的変数 + 特徴量
# train/testそれぞれでモデルを適応して確率を予測 train_probas = pd.DataFrame(rf.predict_proba(train_data[features])) train_probas.columns = ['no', 'yes'] test_probas = pd.DataFrame(rf.predict_proba(test_data[features])) test_probas.columns = ['no', 'yes'] # 特徴量データに目的変数Attrition列を追加(復元)して予測確率とマージ train_data.reset_index(inplace=True, drop=True) train_data['Attrition'] = ['no' if x == 0 else 'yes' for x in train_y] rf_merged_train = pd.concat([train_data, train_probas], axis = 1) test_data.reset_index(inplace=True, drop=True) test_data['Attrition'] = ['no' if x == 0 else 'yes' for x in test_y] rf_merged_test = pd.concat([test_data, test_probas], axis = 1)

- 上記2オブジェクトの各列が何を表すかを、「target」「prediction」「numerical_features」「categorical_features」で指定したdictオブジェクト
column_mapping = {}
# 目的変数の列名を指定
column_mapping['target'] = 'Attrition'
# 推定確率の列名を指定
column_mapping['prediction'] = ['yes', 'no']
# 連続値変数の特徴量を指定
column_mapping['numerical_features'] = ['Age','DailyRate', 'DistanceFromHome', 'Education',
'EmployeeNumber', 'EnvironmentSatisfaction', 'HourlyRate',
'JobInvolvement', 'JobLevel', 'JobSatisfaction', 'MonthlyIncome',
'MonthlyRate', 'NumCompaniesWorked', 'PercentSalaryHike',
'PerformanceRating', 'RelationshipSatisfaction', 'StockOptionLevel',
'TotalWorkingYears', 'TrainingTimesLastYear', 'WorkLifeBalance',
'YearsAtCompany', 'YearsInCurrentRole', 'YearsSinceLastPromotion',
'YearsWithCurrManager']
# カテゴリカル変数の特徴量を指定
column_mapping['categorical_features'] = ['b_travel_Non-Travel',
'b_travel_Travel_Frequently', 'b_travel_Travel_Rarely',
'department_Human Resources', 'department_Research & Development',
'department_Sales', 'edu_field_Human Resources',
'edu_field_Research & Development', 'edu_field_Sales', 'gender_bin',
'job_role_Healthcare Representative', 'job_role_Human Resources',
'job_role_Laboratory Technician', 'job_role_Manager',
'job_role_Manufacturing Director', 'job_role_Research Director',
'job_role_Research Scientist', 'job_role_Sales Executive',
'job_role_Sales Representative', 'marital_Divorced', 'marital_Married',
'marital_Single', 'overtime_No', 'overtime_Yes']

これらオブジェクトをもとにDashboard関数を用いて、第一引数に上記referenceオブジェクト、第二引数にcurrentオブジェクト、 column_mappingに上記dictでの列情報、tabsにレポートの種類(モデルの種類)を指定する。今回の場合以下のように出力。
report = Dashboard(rf_merged_train, rf_merged_test, column_mapping = column_mapping,
tabs=[ProbClassificationPerformanceTab])
# htmlとしてダッシュボードを保存
report.save('reports/ibm_hr_attrition_baseline_performance.html')
なお、
report = Dashboard(rf_merged_train, rf_merged_test, column_mapping = column_mapping,
tabs=[DriftTab, ProbClassificationPerformanceTab])
report.save('reports/ibm_hr_attrition_baseline_performance.html')
のようにすると、Data Driftも一緒に出力されるが今回はモデル適用元データは同じ(モデルアルゴリズムが違う)なので見る必要がないので割愛する。
また、まとめてhtml出力するのではなく任意のグラフだけnotebook上に埋め込むことも可能。
結果の解釈
レポートの結果を上から見ていく。なお、データは共通してtestデータを使い、使用アルゴリズムがReferenceはRandomForest、CurrentはCatBoostを使って推定した結果となる。つまり、各モデルでどっちを使ったほうが良いか考える。
Macroでの評価指標(Model Quality With Macro-average Metrics)
分類モデルの基本的な評価が一覧化されている。総じてCurrentの方が良い

目的変数(実測)のバランス(Class Representation)
推定するデータの目的変数の各クラスの実際の値がどうなっているか。
今回Reference/CurrentでRF vs CatBoostとなりモデルアルゴリズムは異なっているが元データは同じなのでどちらも同じ内容が表示されている。実際には同アルゴリズムを用いて例えば先月のデータをReference、今月のデータをCurrentにして比較レポートを作成する場合に役に立つ。

Confusion Matrix
よくあるConfusion Matrix(混合行列)。
冒頭での「Macroでの評価指標(Model Quality With Macro-average Metrics)」ではCurrentの方が全評価指標において勝っていたが、それはMacro-average で見た場合で個別でみるとReferenceの方がNoに対しての正解がCurrentより勝っていることがわかる(ほぼ一緒だけど)

Microでの評価指標(Quality Metrics by Class)
Microでの評価指標に変換。先程Confusion Matrixで見たように、Referenceはnoに対するRecallがCurrentより勝っている。

分類の質(Class Separation Quality)
キャプチャでは、各インスタンスに対してyesと推定される確率を可視化している。実際にyesのものを赤色、実際がno(other)が灰色(noではなくother表示なのは多クラス分類のときと統一的なインターフェイスにするためか?)。
ちなみに、グラフはマウスポインタで直接拡大や強調などが可能。
実際がyes(赤色)はReferenceとCurrentであまり違いがなさそうだけど、no(灰色)に関してはCurrentの方が分散が小さいかつはっきりと分類(noでyesの確率が全体的に低い)できていることがわかる。
ただし、左右どちらでもnoなのに0.7前後となるインスタンスが存在しているのでこのインスタンスに注目して色々なデータを見ていくなどして、こいつをうまいこと分類できそうな特徴量を探すと精度向上に効くかもしれない。
また、yes/noの閾値をどこで変えると良さげなのかなどを考えることもできる。

確率分布(Probability Distribution)
「分類の質(Class Separation Quality)」とみている値は同じだが先程は密度(正確には頻度)がわかりづらかったのでその観点で可視化されている。
改めてちゃんと密度観点でみるとCurrenrtの方が評価指標はいいのだけど、実際yesなのにyesの確率が極端に低いものが出やすい。noとも併せて考えると、Referenceより極端な値が出やすいモデルなのかもしれない。

ROCとPrecision-Recall Curve

閾値をどこで切るか(Precision-Recall Table)
Precision-Recall Curveでプロットされた各点についての詳細が表示されている。閾値を決める際は一般的にPrecisionとRecall のトレードオフなのでこの表をソートしたりしてどの閾値にするのが良いのか考える。
キャプチャの囲い部分の見方としては、Precisionを高い順に並べるとyesの閾値(Prob)を0.42がPrecision最大となる。0.42以上となるインスタンスは18件(Count)となりこれはProbが上位4.9%が対象となることを指す。この18件のうちTPは12FPは6件。

実際にClass Separation Qualityに閾値0.42を引くと下記のようになる。

各特徴量での予測値(Classification Quality By Feature)
Allタブでは単純に特徴量の値に応じたヒストグラムができあがる(Categorial Target Driftと同じ内容)。予測値自体は出ないので今回のレポートでは左右で同じになる。

次に、yesとなる予測確率を年齢毎にみる。
挙動をみていく。20歳以下は実際のyes/noに関わらずyesになる確率が高くなる傾向にありそう。つまり、20歳以下だととりあえずyesにしがち(yesの確率を高く吐きがち)なモデルなような気がするので20歳以下に関しての予測性能は低いモデルと解釈できるので実運用上では注意した方が良さそう(特にReference)。なお、原因としてはおそらく20歳以下のサンプルサイズが小さいことが考えられる。

(今回は良い例が見当たらなかったが)もし実運用で「ある特徴量がある値(例えば給料がミドルレンジ)の退職予測を中心におこないたい」場合、その特徴量値に関してのみ着目して予測精度が良さそうな方のアルゴリズムを選択するとよい。言い換えると、評価指標のみでモデルを選択するのではなく、実運用上での目的によっては特定の特徴量のインスタンスに対してうまく予測するようなモデルを選択するという考え方もできる。
データサイエンティストのデータサイエンス以外のスキル面について考えた
本記事は、所属しているグループのAdvent Calenderです。
で、お前誰
TVの視聴データを扱う会社でデータサイエンティスト(以下DS)をしてます。
31歳院卒。1社目は2年半ほどいてダッシュボードを作ったり、社内データ利活用のための簡易分析や分析設計をおこなったりしてました。
2社目(現職)でははじめの1,2年はひたすらデータ抽出でSQL書きまくったり、ほぼrawデータなDBを使いやすくするためのデータマートの草案作った(実装自体はインフラの人がやった)りデータ周りのことを色々としてました。
ここ1,2年はデータ分析案件で分析をやったり、PM/PLをやったりしてます。
どういう会社観点か
一般的にDSの所属する会社は、分析受託会社か社内データの分析かの2つに分かれるかと思います。
1社目はSES会社だったのではじめの半年は受託での分析(というかダッシュボード作成)、それ以降はずっと同じ会社に常駐で、常駐先社内データの分析をしていました。
現職ではずっと社内データの分析(とその周辺)です。
厳密には、現職はデータカンパニーなので自社データをクライアントに販売するにあたっての研究や、クライアントからKPIデータなどを頂戴してそのデータと自社データをかけあわせた分析をおこなっています。
記事を書く目的と背景
前述のように、ここ1年は分析自体もやりつつ、PM/PLをやったりしてます。
そのため、チームマネジメントや教育をし始めたり、クライアントとのやりとりや分析結果報告をする機会が増えました。また、チームのメンバーが増えたり、チーム(≒部署)のマネージャー(管理職)的なキャリアも意識するようになりました。
さらに、最近ちょくちょく聞く話ではありますが 分析結果を皆が使える/使おうとする状態にする ためにどうしたらいいかも意識するようになりました。
要するに、分析だけ考えるわけにはいかないという状態。
エンジニア界隈でもよく議論がありますが、DSも一般的にデータサイエンス以外のスキルが必要不可欠だと思いました。
そのため、主に以下のスキルについて今年は意識をしたのでそれぞれについてなんとなく考えたことや、そのために学習した書籍を紹介しつつ書きます。
- PM/PL
- 分析結果報告
- チームマネジメントについて
- 分析結果をどうするか
ただし、DSに限ったスキルではない「スキルそのもの」の説明詳細は割愛しつつ、気になる方は書籍や記事を読んでねスタイルで書きます。
PM/PL
プロジェクトの進め方
分析案件は結局結果を出す→その結果を踏まえて別のやり方を試したり深堀りをする、といったようにはじめからカッチリと要件を決めていくことは難しいです。
そのため、昔からCRISP-DMとよばれるフレームワークがよく使われているようです。
DS案件は工数の不確実性が高いためか、不確実性を考慮したエンジニアの開発手法であるアジャイル開発的な手法と相性がよいのでは?(CRISP-DMもアジャイルに近い)という話が色々なところでされているので、いい感じにプロジェクトを進めていくにあたりアジャイル開発について学ぶ必要を感じました。
書籍としては、以下の本がストーリー形式なので全体の流れや実際のイメージを把握しやすかったです。

そして、細かい部分やアジャイルの哲学として次には以下の本で1冊目の肉付けをしていきました。

- 作者:Jonathan Rasmusson
- 発売日: 2011/07/16
- メディア: 単行本(ソフトカバー)
ただし、一般的なアジャイル開発はエンジニアに対する話なので適宜DS向けに修正する必要があり、それについては以下の記事で書きました。
また、そもそもどういった形でアウトプットを出すのか、という点ははじめにちゃんと設計をした方がいいです。
例えば、機械学習モデルだと「どういう精度ならよいか」をはじめに決めたり、分析ならば「どういう形が利用者に使いやすいか」などがそれに当たります。
そのあたりは以下の本が非常に参考になりました。

なお、機械学習系の進め方の個人的なテンプレは過去以下にまとめました。
どういった手法を使うか
分析には色々なアプローチがあります。ではその中でどのアプローチを選ぶか、となると 手元のデータにはどういう特性があるか によって決まります。
何故、特性を調べる必要があるかというと、特性によって使えるモデルが変わるからです。世の中の様々なモデルやアルゴリズムには ある一定の仮定のもとで使える といった制限があります。また、 こういった条件でも使えるためにこのモデルが作成された という背景があります。
つまり、 データの特性を知ることでおのずとどのモデルを使えるか(どのモデルが使えなくなるか)。ということがわかります。
そのため、 xxを知るためのアプローチ = これだ! みたいな考え方ではなく 、 xxを知るにあたり、データがこうなっている。こういうデータでもカバーできる特性を持ったモデルだとこれだ! のような決め方が基本となります。
そうなると、各モデルにはどういう仮定が置かれているか・どういった欠点があるか、ということを把握しておく必要があります。
(ちなみにそのあたりについて作成したスライドが以下です。)
なお、これは統計モデル系ではよくある話ですが、機械学習系のモデル(アルゴリズム?)でも同様のことがいえます。
例えば、そもそも機械学習ではtrain, testが同じような特徴量分布をしているという前提が置かれているので、仮にそうなってなかった場合はAdversalial Varidationしようねとか、Random Forestは決定木の特徴としてtrainしたデータの範囲内の出力しかされないから時系列系でトレンドが乗ると上手く使えないとかそういった点です。
つまり、なんとなく勉強をするのではなく、「似た手法のxxxと何が違うのか」「どういった欠点があるのか」「どういった仮定をおいているのか」を意識して勉強をしていく必要があります。
まぁこのあたりは意識的に自分に問わないと「知っていないことを認識していない」ため結構難しいところです。以下の記事では「採用時にDSがちゃんと各手法を理解しているのか」を把握するためのよくある質問集とのことなので、質問に答えれるようにしていくと「知っていないことを認識」しやすいのではないかと感じます。
また、手法そのものの学習の際は挙動を図示しながら学習すると根底のロジックを理解しやすいです。以下のYoutube channelは図示が多いので理解しやすく、応用を効かせやすいように感じます。
ドメイン知識
どうやって要件定義をするのか、という部分でよく「ドメイン知識がないと現場とズレた分析になる」という話があります。じゃあどうやってドメイン知識を得ていくのか、ということはDSの永遠の課題ではあると思います。
一般的には「現場の声を聞こう!」ということが言われたりしています。弊社の場合は、現場=他社なので他社にいちいち聞くのは難しいのですが、代わりに営業やコンサル部門(正確にはカスタマーサクセス部門)の人(以下営業系部署)に色々と話を聞いています。
具体的には、分析内容について「こういう風にやっていくとこういうことがわかる」という点までいったん考えたあとに、営業系部署に壁打ち相手*1になってもらい、出てきた結果について一緒に解釈したりディスカッションをしてもらっています。
また、slackで営業系部署の人が話している内容を読んだり、定例会議に参加するなどもドメイン知識取得には役にたっています。ただし、こちらはあくまで「営業系部署内での話」がメインなので、例えば「xxさんがキーマン」「今期受注をxx万達成するためには」「営業フローの見直し」といった話が多くあり 時間対効果が悪い です。
そのため、どれがDS的に関係がありそうな話なのかを見極めて集中して聞く話と聞かない話を区別する必要があります*2。
ただし、例えば前述の「xxさんがキーマン」は話の展開によっては「xxさんは特にxxxという部分を意思決定に大事にしているし、業界的には大事な指標になっている。」のようにDSにも関係がある話になることもあるので難しいところです。
そのため、「とりあえずはじめの方は時間対効果は悪いけれどある程度ちゃんと聞いて、ちょっとずつ関係がある部分の勘所を養う」「短期的な効果は見込めないが長期的には役に立つ」くらいの認識でやっていくのかなぁと感じてます。ただし、気づくと惰性でなんとなく参加になりがちなので、slackを決まった時間読んだり定例会に参加したあとに「今日学んだこと・考えといた方がいいこと・アイデア」などを5分間ひたすらメモに書きなぐったりして、学びを最大化するのは必須だと感じています。
きれいなコードを書く/書かせる
jupyter notebookが便利だからかわかりませんが、DSの書くコードは汚いという話をよく聞きます。エンジニアと違い、その案件が終わるとそのコード使わなくなったり、そもそも一人作業が多いので人に見せる必要が薄かったり、そもそもレビューがされないということも原因かと個人的には思います*3。
しかし、これはあくまで コードが汚くてもうまくいっているように見える だけであって、実際は前処理ミスなどがあってうまくいってなくて結果も間違っているけど気がついてないのかもしれません。また、そもそもコードが汚いと自分が読み返すときにミスが生まれやすかったり、再利用することがあるときに過去の自分のコードを読むのに時間が多くかかります。そのため、本来はレビューは必須です。
そうなると、「一人作業で完結」という体制はイコールでレビューがされてないことになりますし、言い方を変えると「レビューは必須なので複数人作業となり、誰かにコードを見せないといけない」です。
そのため、DSもきれいなコードを書く必要性があるのでその点について学習しました。
また、プロジェクトを進める際にコードは別の人が書く場合もレビューを念頭において書かせる必要があります。
ただし、最後にリファクタリングさせるからいいやとしばらく汚い状態で放置しておくとバグの温床になります。他にも、手遅れになってから気付いたり、リファクタリングが非常に時間がかかりいつまでもレビューができないなど、様々な影響が出てくるので、ある程度の頻度でリファクタリングやレビューをするようにマネジメントする必要があります。 エンジニア出身の人はいいのですが、はじめからDSでやってる人はレビュー文化が薄いのか、レビューをする機会を要所要所で作らないと全部終わってからリファクタリング&レビューになりがちな気がします。
では、どうやってきれいなコードを書くかは定番の以下の本がおすすめです*4。
")
リーダブルコード ―より良いコードを書くためのシンプルで実践的なテクニック (Theory in practice)
- 作者:Dustin Boswell,Trevor Foucher
- 発売日: 2012/06/23
- メディア: 単行本(ソフトカバー)
DSに一番わかりやすく必要そうな箇所だけ以下でまとめてます。
上記ではまとめてませんが、他に関数化できそうな部分(というか、2回以上同じ処理をする部分)は関数化するとか、コメントをちゃんと書くとかも大事ですね。
ちゃんと書けてるか?の指標としては、しばらく時間を置いた自分が書いたコードを読んだときに読みやすいか? 。読みづらかったらその部分を反省してどう読みづらかったかを考えて以降に反映するのがやりやすいです。
なお、notebookでレビューをするのはgithubなどでは表示が見づらいのでReviewNBなどを利用するとよいです。
正しいデータを出す
レビューと内容的に被る部分もありますが、モデルに流すデータが本当に正しく処理されている? という検証が必要となります。
その際は「テスト駆動開発」というやり方が参考になりました。
簡単に書くと、「テストとセットでコードを書いていく」みたいな開発手法です。
DSにおいては、前処理でこの開発手法を使うことで「正しい前処理ができているか?」という点をテストすることができます*5
詳細や実際の様子は以下の動画がわかりやすかったです。
また、簡易的にはassertを仕込んだり、Rの場合だとどういうJOINがされたかなどを各工程で出力してくれるtidylogの利用をおこなうとレビュー以前の簡単なミスは防ぎやすいです。
分析結果報告
資料作成
DSは多くの場合、分析結果をスライド化なりレポート化なりの資料化をおこなって報告をする必要があります。その際に、せっかく良い結果が得られても適切な伝え方をしないと良いリアクションが返ってきづらいです。そのため、資料作成技術は必須だと感じています。
基本的なことは世の中に数多ある資料作成本を読めばいいですが、DS特化という意味では以下の本が最高です。

- 作者:コール・ヌッスバウマー・ナフリック
- 発売日: 2017/02/16
- メディア: 単行本
Storytelling with Dataという原著のタイトル通り、 データでストーリーを語る 観点での資料作成の本です。データ分析は、非DSの人には複雑になりがちなのでそれをいかに伝えたいことをシンプルに見せるかの点で非常にすぐれています。
ただし、この本はあくまで全体構成や結果の見せ方の本なので例えばどういう手法を使ったかの説明が必要な場合に関しての記述はありません。
そういう場合は、いかにモデルの説明を非DSでも理解できる言葉に落とし込むかが重要になります。
例えば、Youtube広告の認知率を測るモデルとして、
のように 数式をそのまま書くのではなく、
のように、極力日本語化して書きつつ、それぞれの項を色分けして色毎に追加日本語説明をする、など極力わかりやすい形にする必要があります*6。
また、実際にどういうときにどういう動きをするのかということをクライアントの馴染みが深い言葉を用いて具体例を示すとなおイメージがつきやすくなります。
更にいえば、はじめにモデルの説明から入ると難しい印象を与え、聞き手が 「なんか難しそうでよくわからんから流しとこう」モードとなってしまいがちなので、はじめに「今から話すモデルでどういうことができるようになるのか」を実際をイメージ*7して説明をおこなってから話す、といったようなスライドの順番の工夫なども必要となります。
つまり総じて DSの理解そのままで見せても非DSからしたらよくわからないので、どうやったら非DSの人が興味を持ってわかりやすく、興味を失わずに聞き続けることができるか を意識した工夫を随所におこなう必要があります。
この点に関しては、DSである自分ではチェックしづらい部分でもあるので営業系部署の人に壁打ち相手になってもらうなどの準備も必要となります。
マネジメントについて
どういうキャリアを取るかにも寄りますが、ある程度キャリアが長くなっていくとマネジメントをする機会は随所で出てくると思います。
マネジメントは、チームの人に焦点を絞った「ピープルマネジメント」、プロジェクトに関しての「プロジェクトマネジメント」、技術に関しての「テックマネジメント」に分類できるので、それぞれについて書きます。
ピープルマネジメント
どうやってチームをうまく作っていくかとか、メンバーを成長させていくか、のような話ですが、ここはまぁDSに限った話ではないので、読んだ中でよかった書籍をあげるだけにしておきます。

チームが機能するとはどういうことか ― 「学習力」と「実行力」を高める実践アプローチ
- 作者:エイミー・C・エドモンドソン
- 発売日: 2014/09/05
- メディア: Kindle版

1兆ドルコーチ――シリコンバレーのレジェンド ビル・キャンベルの成功の教え
- 作者:エリック・シュミット,ジョナサン・ローゼンバーグ,アラン・イーグル
- 発売日: 2019/11/14
- メディア: Kindle版



マネジャーの教科書――ハーバード・ビジネス・レビュー マネジャー論文ベスト11
- 発売日: 2017/09/14
- メディア: 単行本(ソフトカバー)

世界最高のチーム グーグル流「最少の人数」で「最大の成果」を生み出す方法
- 作者:ピョートル・フェリクス・グジバチ
- 発売日: 2018/08/20
- メディア: Kindle版
ただ、読んでいて思ったのはやはりエンジニア向けのチームビルド・マネジメント系の本はDSと相性がよいように感じます。


エンジニアのためのマネジメントキャリアパス ―テックリードからCTOまでマネジメントスキル向上ガイド
- 作者:Camille Fournier
- 発売日: 2018/09/26
- メディア: 単行本(ソフトカバー)
テックマネジメント
前述のピープルマネジメントやプロジェクトマネジメント業務をおこなう際に、データサイエンススキル(知識)が欠けているとうまくマネジメントをすることができないように感じました。
例えば、ピープルマネジメントでは今学習している技術の相談であったりキャリアについて上手く話すことができないですし、プロジェクトマネジメントは前述のように要件定義で必要になるし、自分が要件定義をしない場合でも案件で使う技術に関しての相談や壁打ち相手をすることができません。
メンバーが持つスキルよりも全てにおいて詳しいのが理想ではありますが、皆それぞれスペシャリストなのでそれは現実ではないです。ではどうすればいいかというと壁打ち相手になるのに必要な知識があればいいように思います。つまり、基本的に技術自体のことは各メンバーが考えつつも、考えるための手助けになる視点を返していく(いわゆる、ソクラテス問答法)ために必要な知識を得ておけば最低限のテックマネジメントはできるように思います。
そのため、
- 少なくとも話している手法の基本的な部分を知っておく
- 参考にする論文をなんとなく内容を理解できるくらいの知識はつけておき、一読する
これらを指針に知識を得る必要があり、継続的に学んでいく必要があります*8。
分析結果をどうするか
「プロジェクトの進め方」で軽く触れましたが、最終的に分析結果をどうするかによっては「プロトタイプに落とし込み、皆が気軽に触れる状況にする」ことが最適な場合もあります。
その場合、Tableauなどのダッシュボードツールを使えるようにしたり、Python DjangoやR Shinyでプロダクトとして作成する必要も出てきます。
言い方を変えると、「プロトタイプに落とし込むスキルがある」と、アクションに繋がる落とし所を持った分析案件をすすめることができるので選択肢が非常に広がります。会社によっては、プロダクト開発のエンジニアを持っている会社もあるとは思いますが、DSが自分でそこまで落とせる方がスピード感が違うので会社へのバリューに繋がりやすいです*9。
ただし、このときにただスキルがあるだけでは使いづらいUI/UXのプロトタイプが出来上がるので、ある程度プロダクト開発の手法を学ぶ必要があります。

- 作者:丹野瑞紀
- 発売日: 2020/08/26
- メディア: 単行本(ソフトカバー)


行動を変えるデザイン ―心理学と行動経済学をプロダクトデザインに活用する
- 作者:Stephen Wendel
- 発売日: 2020/06/11
- メディア: 単行本(ソフトカバー)

正しいものを正しくつくる プロダクトをつくるとはどういうことなのか、あるいはアジャイルのその先について
- 作者:市谷聡啓
- 発売日: 2019/06/14
- メディア: 単行本
ちなみに余談ですがホクソエムさんは「DSはプロダクトマネージャーを目指すのが(キャリアとして)一番いい」といったことを記事で言っていたりするのは、このあたりの話もあるのかな、と思います。
終わりに
「記事を書く目的と背景」に書くか迷いましたが、こちらに書いたほうが締めとしてはよいのでこちらに書きます。
エンジニアで「コード以外の仕事が多い」という議論がよくあるようにDSでも同様のことがいえます。キャリアとして、「ただただデータサイエンスを極めるんや!」というのはそれはそれでいいと思います。しかし、極めようにも世の中にはやべーやつがゴロゴロいる中で戦っていけるのか?と考えると多くの人は難しいように思います。少なくとも私はデータサイエンス力偏差値63くらいまではできても、偏差値70の世界で戦っていく気概はありません。地球人なので、地球人の中では戦えても超サイヤ人に混じっては無理なクリリン/ヤムチャみたいな感じです。
そう考えると、一般的に多くのDSにはデータサイエンス以外の仕事が付随してくるし、そもそもそういうことができるDSはまだ少ないという話もあるので、偏差値63くらいありつつも、63→70になる努力をするよりも、その努力分をデータサイエンス以外の部分につぎ込んで価値を出していく方がコスパがいいと感じたのである程度のデータサイエンススキルを確保しつつ「データサイエンス以外のスキル」について上手くやれるようにしていこうと思い今年は過ごしました。
ちなみに、他にも分析案件以外もやるにあたって時間がめっちゃ足りなくなったのでタイムマネジメント系の学習も結構しましたが、そちらはDSの話ではなくなるので割愛しました。
来年もみなさんそれぞれのキャリアをがんばっていきましょー。
*1:話を聞いてもらって色々意見や感想を聞いてもらう
*2:そのため、定例会議で関係なさそうな話のときは会議中他の作業をしておく旨を営業系部署に合意を得たり、slackの読み方にも注意が必要です
*3:レビュー文化がない会社も多いという噂も聞いたりする
*4:エンジニア向けなのでDSが読むには必要以上な箇所もあります
*5:ただし、性質上あくまで「正しいデータか」という点のみしか検証ができないので「モデルが正しく機能しているか?」「適切なモデルか」といった点は検証できないのでその点はレビューで賄うしかないように思います。
*6:簡易化するにあたり落ちる情報があるので、クライアント先DSに資料が回ったときのことも考えてAppendixにちゃんとした数式を載せる方がベターです
*7:例えば前述のモデルだと、「認知率は表示回数と相関しているけれど、広告によって認知率への表示回数効果が異なるということはよくある(グラフで例示)。その原因として、広告の質によって表示回数効果が変わるのでは?という仮定を置いてモデルを立てた(質が高い広告と質が低い広告のイメージ図示)」みたいな。実際のように、この記事中でも文字ではなくスライド形式で見せた方が伝わりやすいと思うのですが割愛
*8:もちろんこれは最低限必要なスキルですし、そもそも自分が分析する際に必要なスキルも別途磨いていく必要性はあります
*9:もちろん、完成度においてはプロダクト開発のプロより劣るとは思うので、プロトタイプをDSが作成し、ある程度かたちが定まったり利用される見込みがたってからエンジニアに頼るのが一番いいフローな気がします
Tableau Serverユーザー追加メモ
Tableau Serverにユーザー追加する際に諸々めんどかったのでメモです。
ユーザーの追加
Tableau Serverにユーザーを追加。
Serverコンピュータからは以下、 http://localhost/#/users
外部コンピュータからの場合 http://自tableauサーバーアドレス/#/users からユーザーを追加。
ただし、この際にTableau Serverに空いているライセンスがないとユーザーにライセンスを割り当てられない。
そのため、そういう場合は以下のライセンス処理をおこなってからユーザーの追加をおこなう。
Tableau Serverにライセンスを追加
以下でライセンスを追加
1.Serverコンピュータから以下にアクセス
https://localhost:8850/#/configuration/licensing (port8850は設定による)
ちなみにこのときはServerの管理者ユーザー(Admin)でログイン?
2.LicensingでActivate Licenseする
ライセンスキーから適応する。
ライセンスキーは以下にある。
https://customer-portal.tableau.com/s/my-keys
3.サーバの再起動(やらないとユーザー追加時に反映できない)
コマンドラインからtsm stop を打つ。状態にもよるだろうが5分くらい。
stop処理が終わったら tsm start する。こっちは10分くらい。
終わり。