GBDTのハイパーパラメータの意味を図で理解しつつチューニングを学ぶ
この記事は何か
lightGBMやXGboostといったGBDT(Gradient Boosting Decision Tree)系でのハイパーパラメータを意味ベースで理解する。
その際に図があるとわかりやすいので図示する。
なお、ハイパーパラメータ名はlightGBMの名前で記載する。XGboostとかでも名前の表記ゆれはあるが同じことを指す場合は概念としては同じ。ただし、アルゴリズムの違い(Level-wiseとLeaf-wise)によって重要度は変わるし、片方にのみ存在するハイパーパラメータもあるので注意。
また、記事の構成などは以下を大いに参考にさせていただいた。
網羅的には以下の記事もよさげ
- この記事は何か
- そもそもGBDTとは
- ハイパーパラメータ
- おまけ:ハイパーパラメータをどういじるか
- 良い結果のために特に重要
- 速度を上げる
- 精度を上げる
- オーバーフィッティングを避ける
- 小さなmax_binを使う
- 小さなnum_leavesを使う
- min_data_in_leafやmin_sum_hessian_in_leafを増やす
- bagging_fractioとbagging_freqをつかってbaggingの調整をする
- feature_fractionを使って特徴量のサンプリングを調整する
- トレーニングデータを増やす
- lambda_l1、lambda_l2、min_gain_to_splitで正則化の調整をする
- max_depthを小さくする
- extra_treesでExtremely Randomized Treesを作る
- path_smoothを増やしスムージングの調整をする
- 参考
そもそもGBDTとは
ハイパーパラメータの話のために、最低限ざっくりGBDTとは。
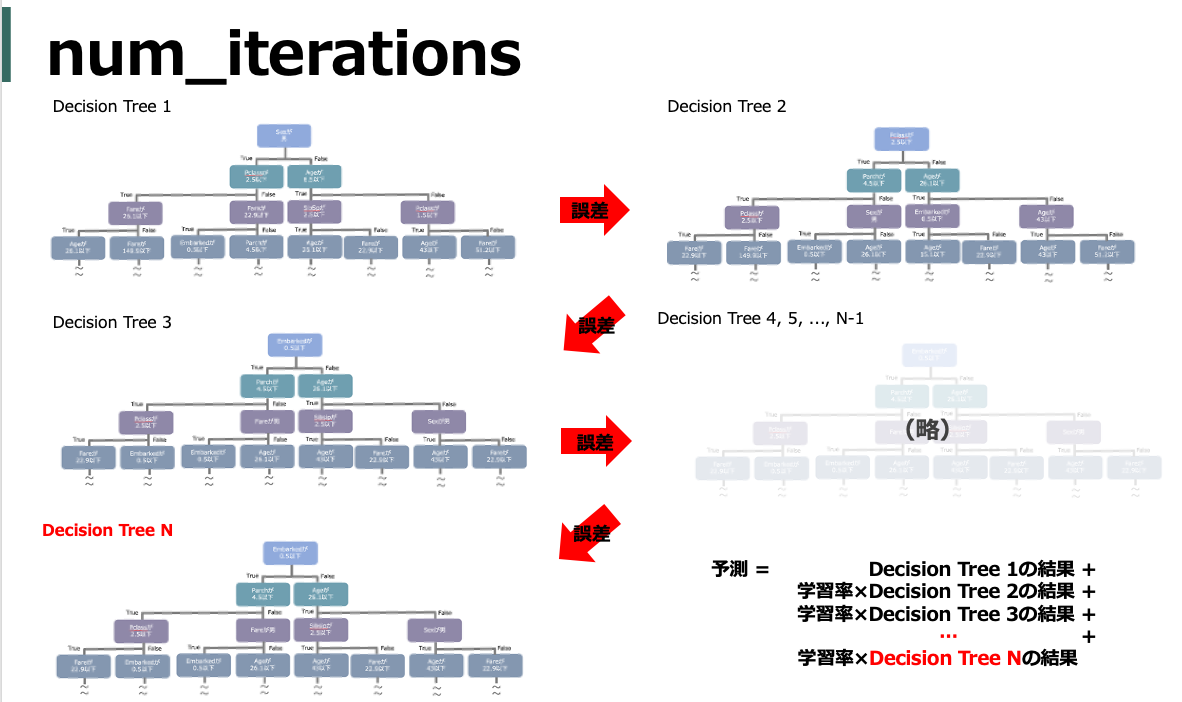
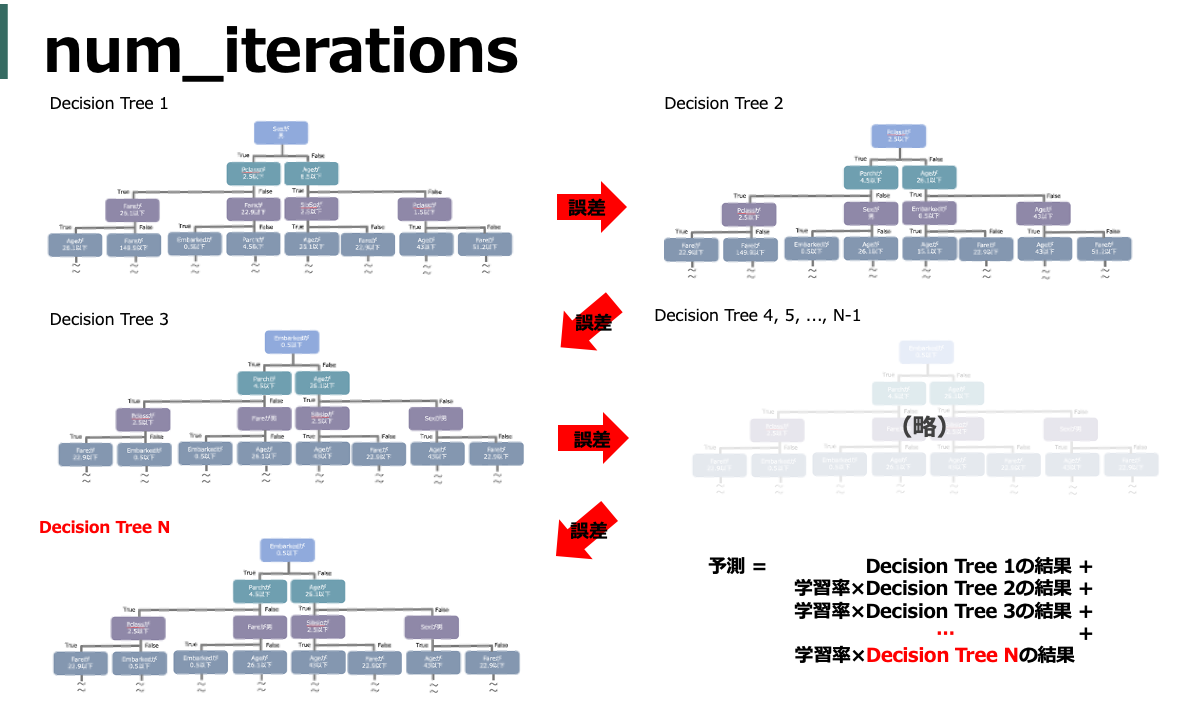
まず決定木(Decision Tree)を作成し、その決定木で学習しきれなかった部分(誤差)を予測するための新たな決定木を作成し、更にその決定木で学習しきれなかった部分(誤差)を予測するための...ということを繰り返し、それらのシーケンシャルな決定木の結果を統合(Boosting)することで高い精度で予測をおこなう手法です。
つまり、「決定木を」「複数つくり」「結果を統合する」。この3点を意識するとGBDT系のハイパーパラメータの意味は概ね理解できる気がします。

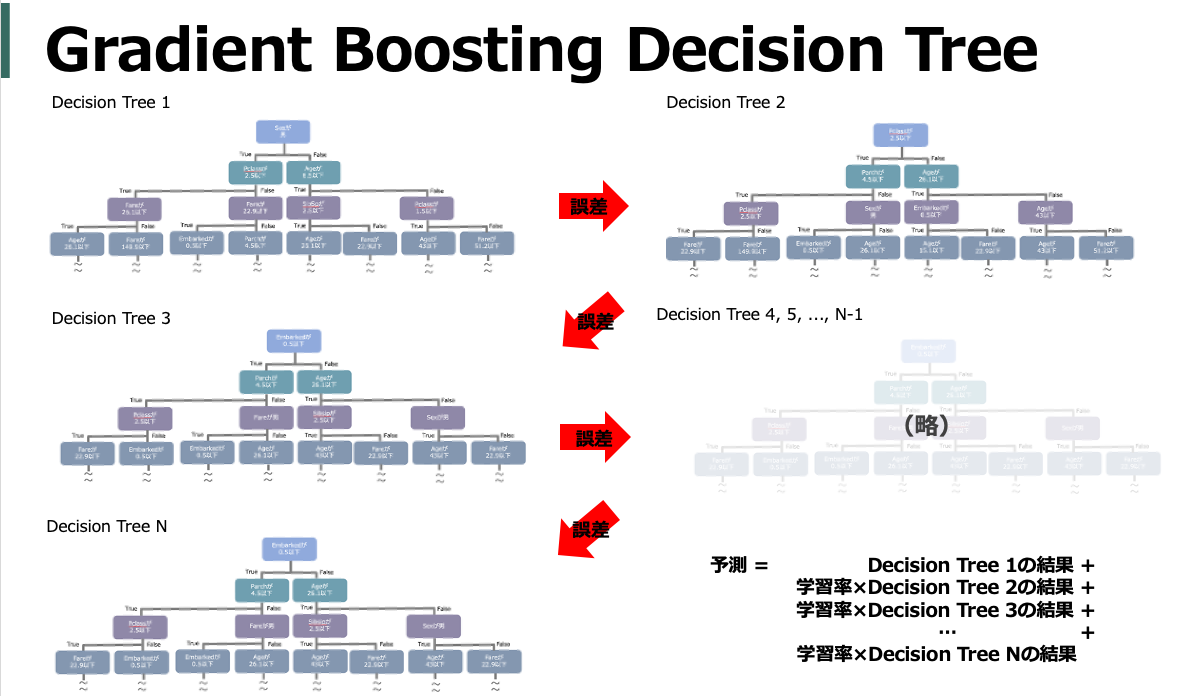
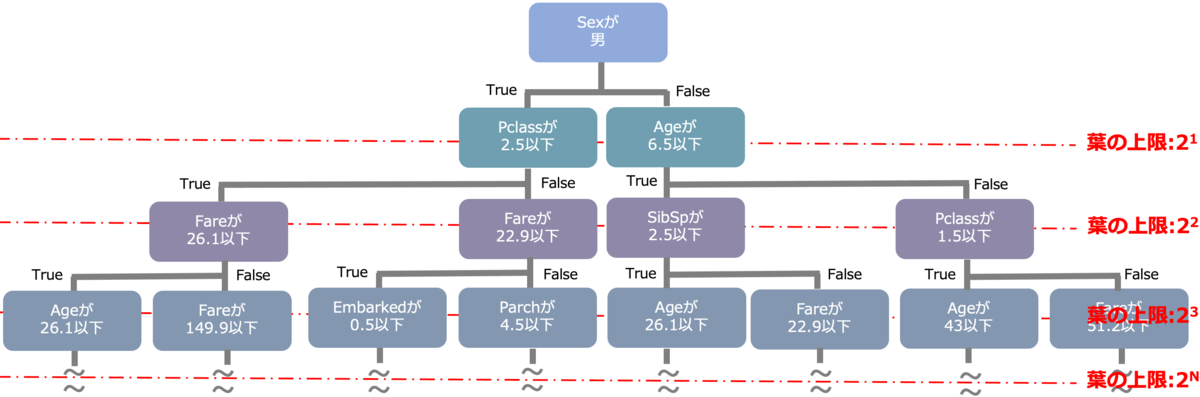
以降では基本的に上図をベースに図示しつつポイントを赤字で記載していきます。
ハイパーパラメータ
ハイパーパラメータは主に
- どのような決定木を作るか
- どういった目的関数にするか
- どうやって学習していくか
の3パターンがあります。
以下では、それぞれ主要なハイパーパラメータを記載します*1。なお、名前はドキュメントのはじめに書いているものを記載しますが、よくみるエイリアスとなるハイパーパラメータ名を()で併記しています*2*3。
どのような決定木を作るか
num_iterations (n_estimators)
作成する木の数(図中のNに相当)。基本的にアーリストッピングを使うと思うので、その場合は実質無限に相当する値を指定しておけば良いっぽい。
default = 100
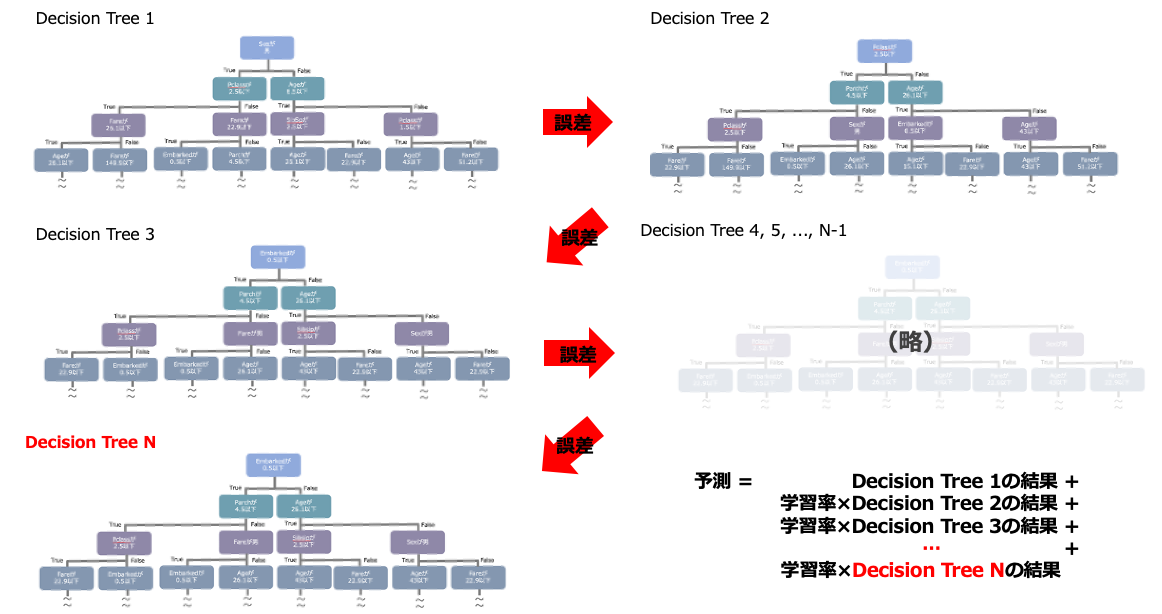
max_depth
木の深さの最大値。大きすぎるとオーバーフィッティングに繋がるので3~8くらいでやることが多い。7ぐらいが無難っぽい。
default = -1(上限なし)

num_leaves (max_leaves)
葉(ノード)の最大数。大きいほど複雑になるが過学習につながる。複雑さに直結するので最重要かもしれない。
例えば、下図では葉が6つあるのでnum_leavesを5以下にすると木の形が変わる。
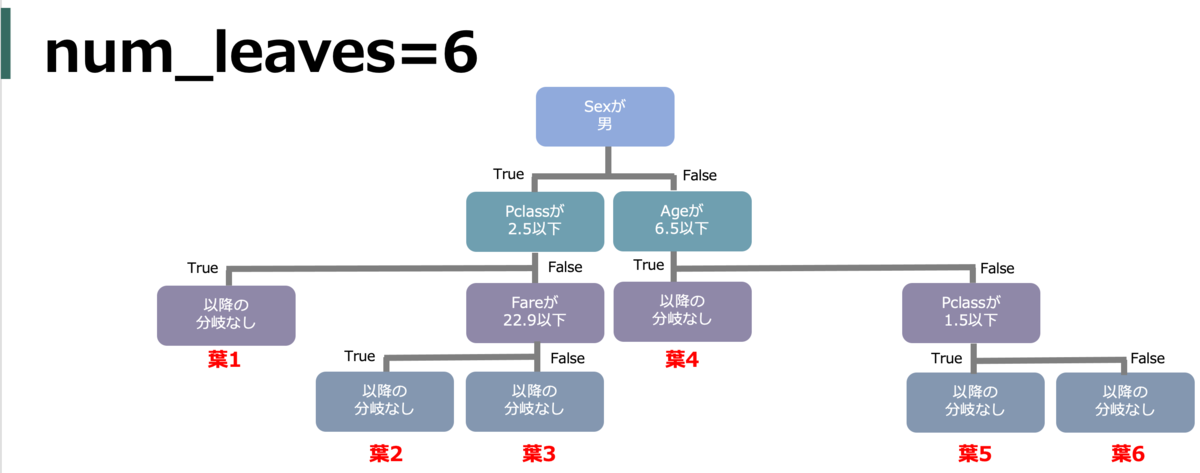
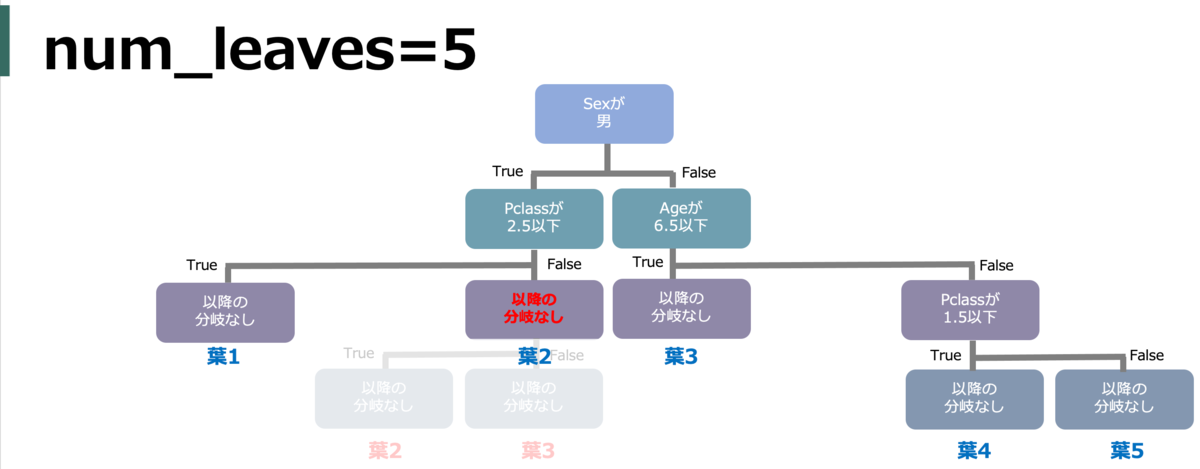
1分割される毎に葉は2つ増える*4。つまり、max_depthが大きいほど分岐が深くなり葉は増えがちなので合わせて調整する。また、理屈上2^max_depthより大きくはならないのでそれ以上大きい値にするとエラーになる。
転じて、最大ノード数の7割にしたい場合max_leaves = int(0.7 * 2 ** max_depth)のように指定したりするらしい。
default = 31
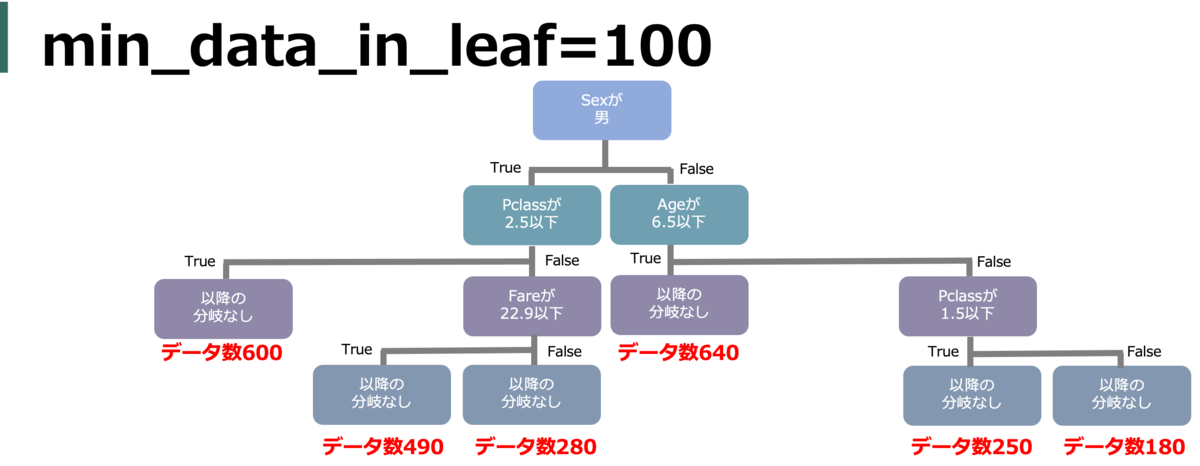
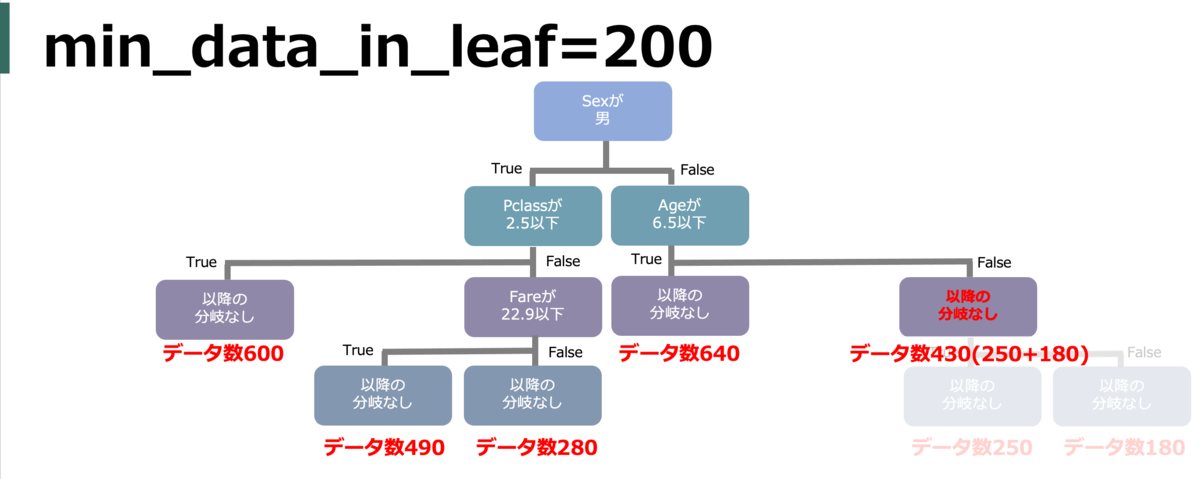
min_data_in_leaf(min_child_samples)
葉に所属する(割り振られる)最小データ数。つまり、分岐条件で割り振り数がこれ以下になるような分岐はされなくなる。値が小さいと細かい葉の分割もされるようになるが過学習に繋がるし、逆に大きいと分割が大雑把になる。
そもそも学習に使うデータが少ないと、各葉内のデータ自体が少なくなりがちなので学習データ数によって小さくする必要がある。また、前述のnum_leavesにも影響される。
default = 20
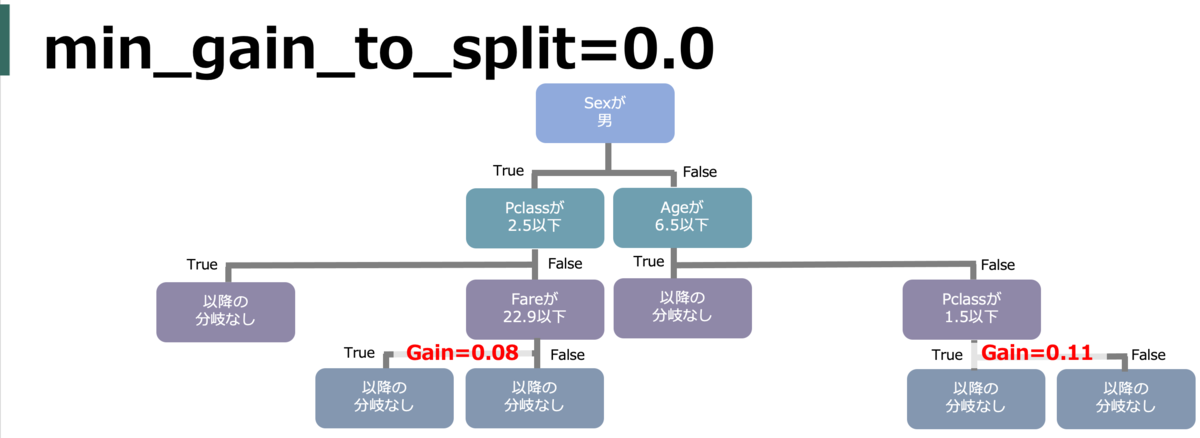
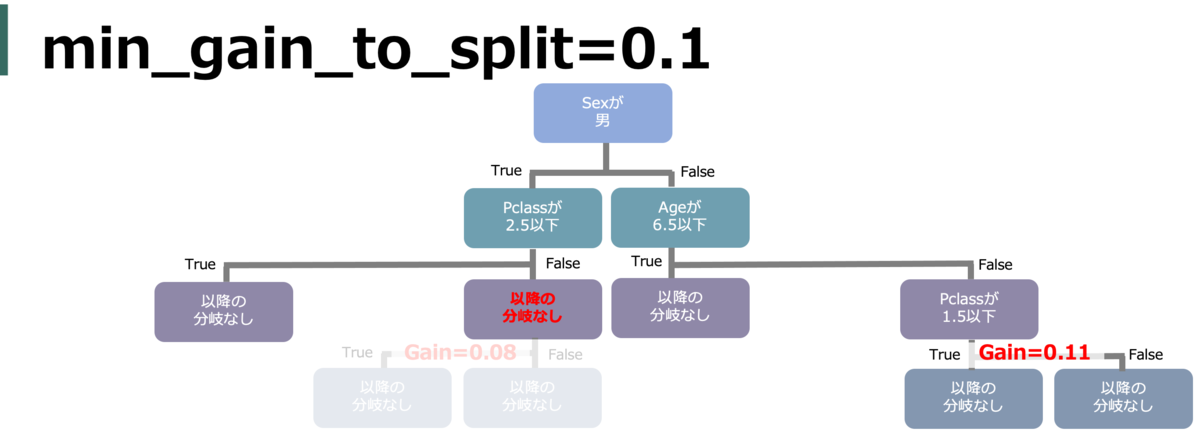
min_gain_to_split (min_split_gain)
決定木ではゲインが最大となるような分割がされる。
その分割するゲインの最小値を指定。それ以下のゲインでしか分割ができない場合は分割がされない。
default = 0.0
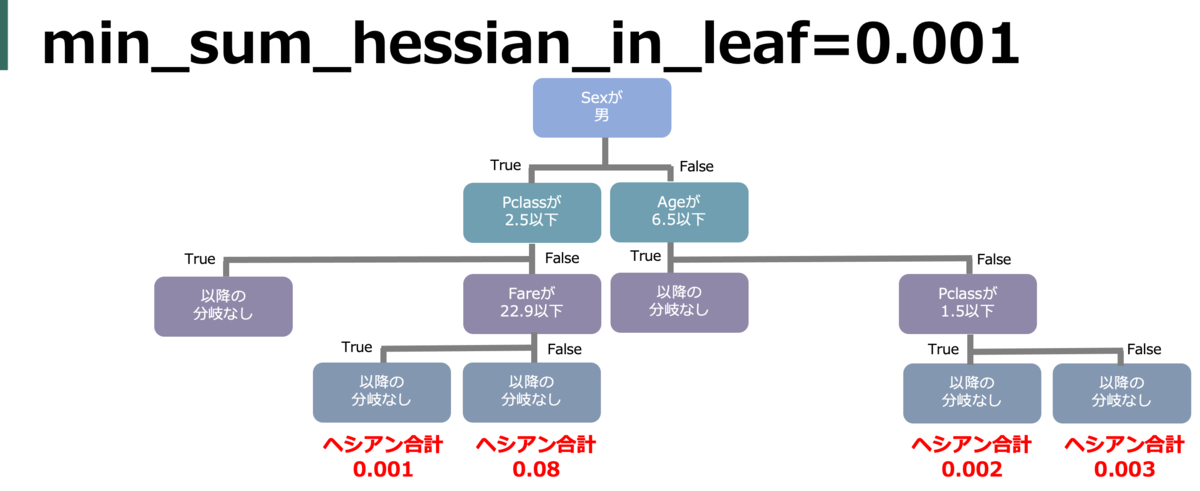
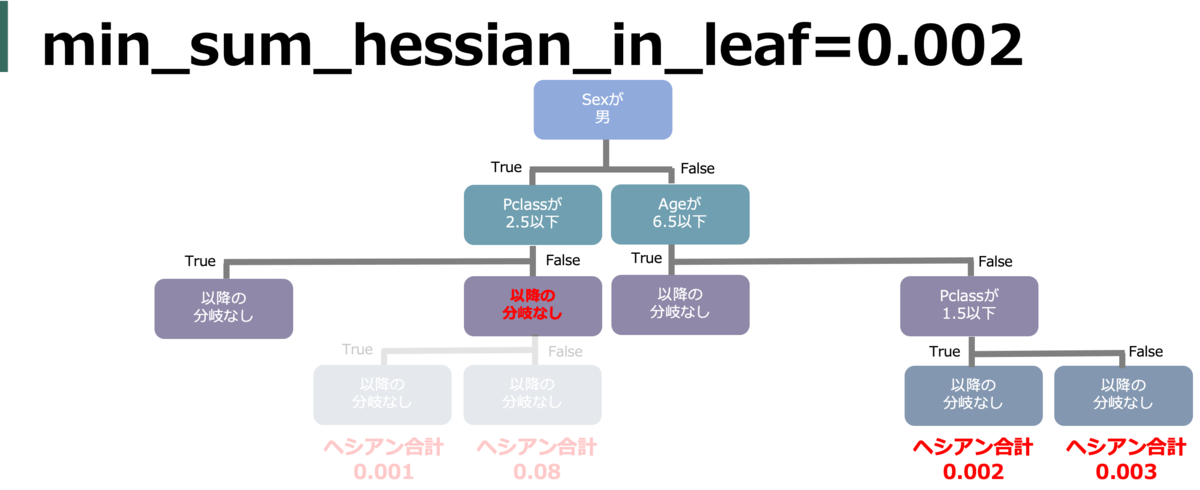
min_sum_hessian_in_leaf (min_child_weight)
葉を分割するのに必要な(ロスの)hessianの合計値。小さければ小さいほどロスを小さくしようと葉を分割するが、オーバーフィッティングを引き起こす。
default = 1e-3(=0.001)
正直私もちゃんと理解できてないが、意味の詳細は以下に詳しい(min_sum_hessian_in_leafはXGBoostではmin_child_weight)
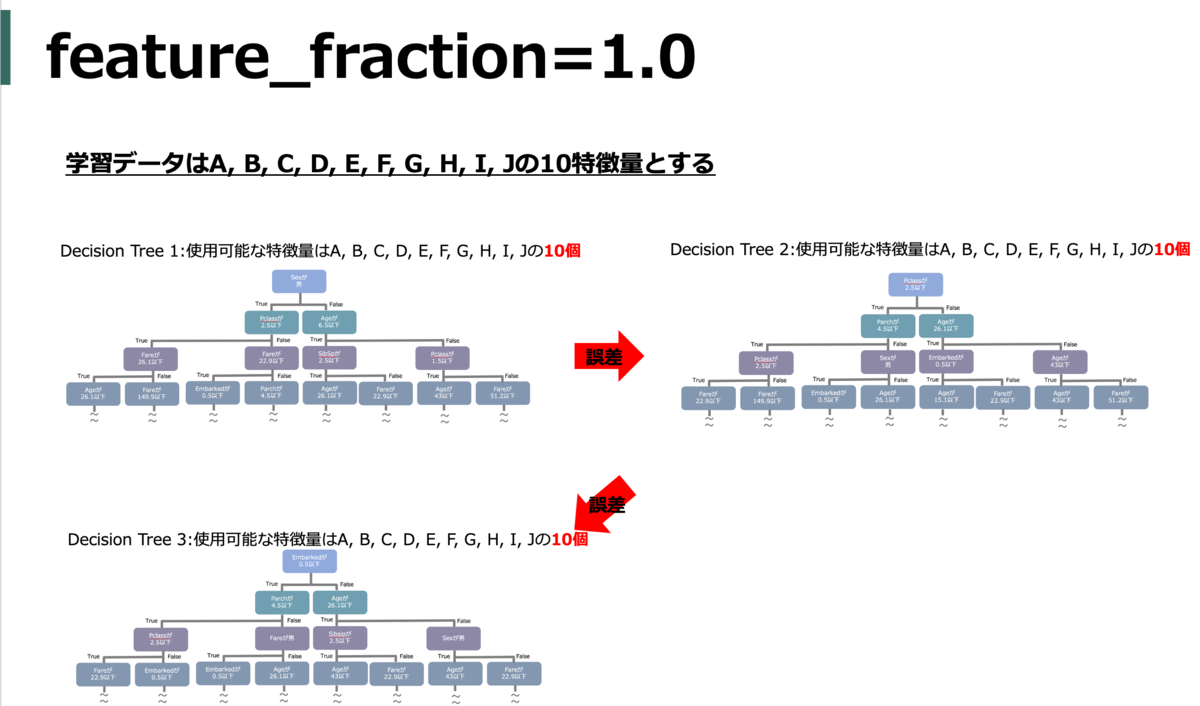
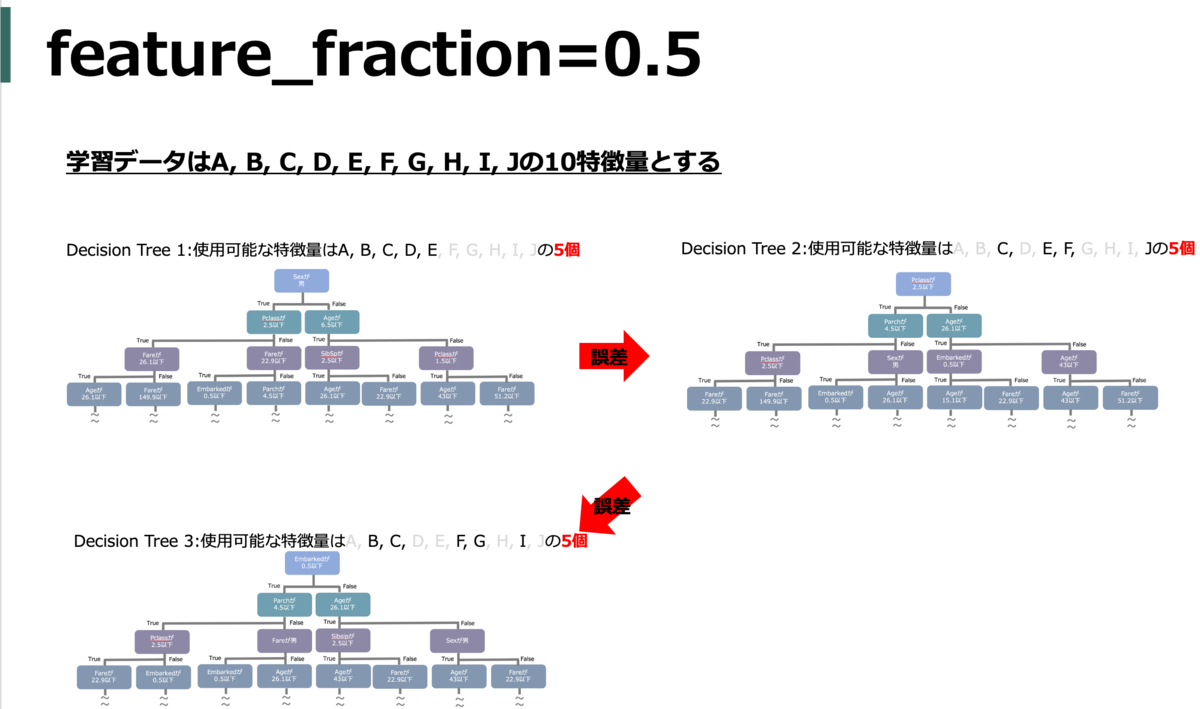
feature_fraction (colsample_bytree)
各木を作成するときに使用可能な特徴量の割合(何パーセントの特徴量をランダムで利用するか)。ちなみに、ランダムなので各木で選ばれる特徴量は基本的に異なる(たまたま同じなことはある)。
default = 1.0
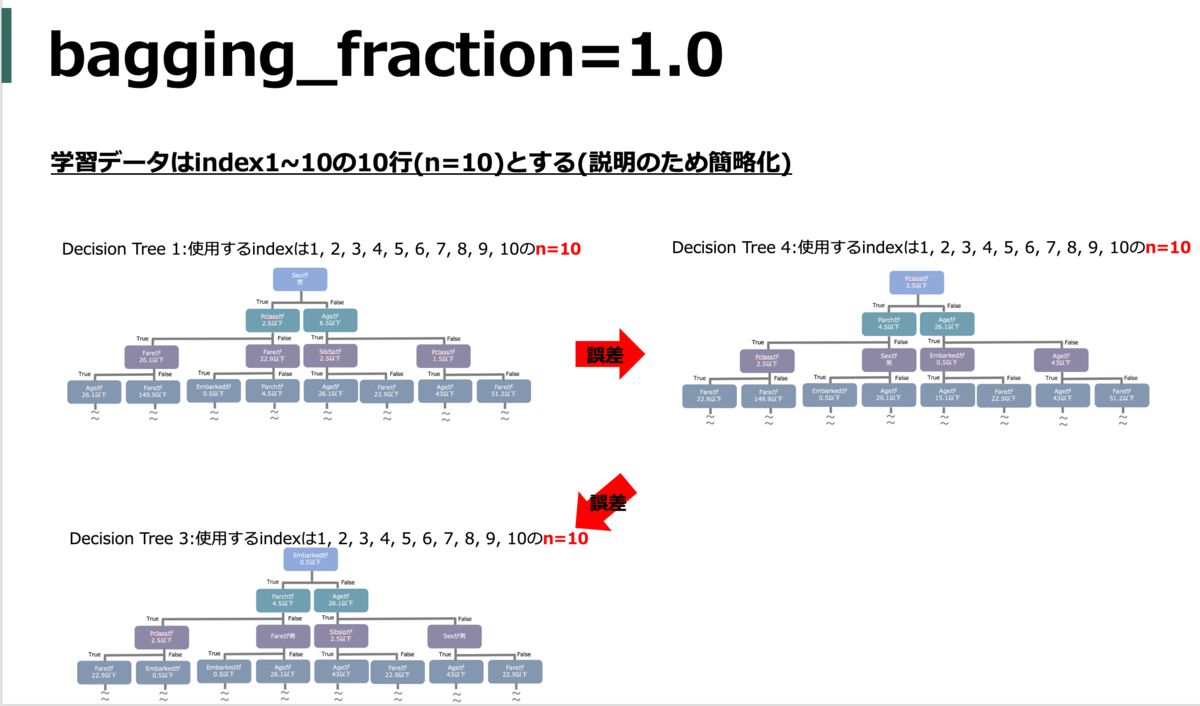
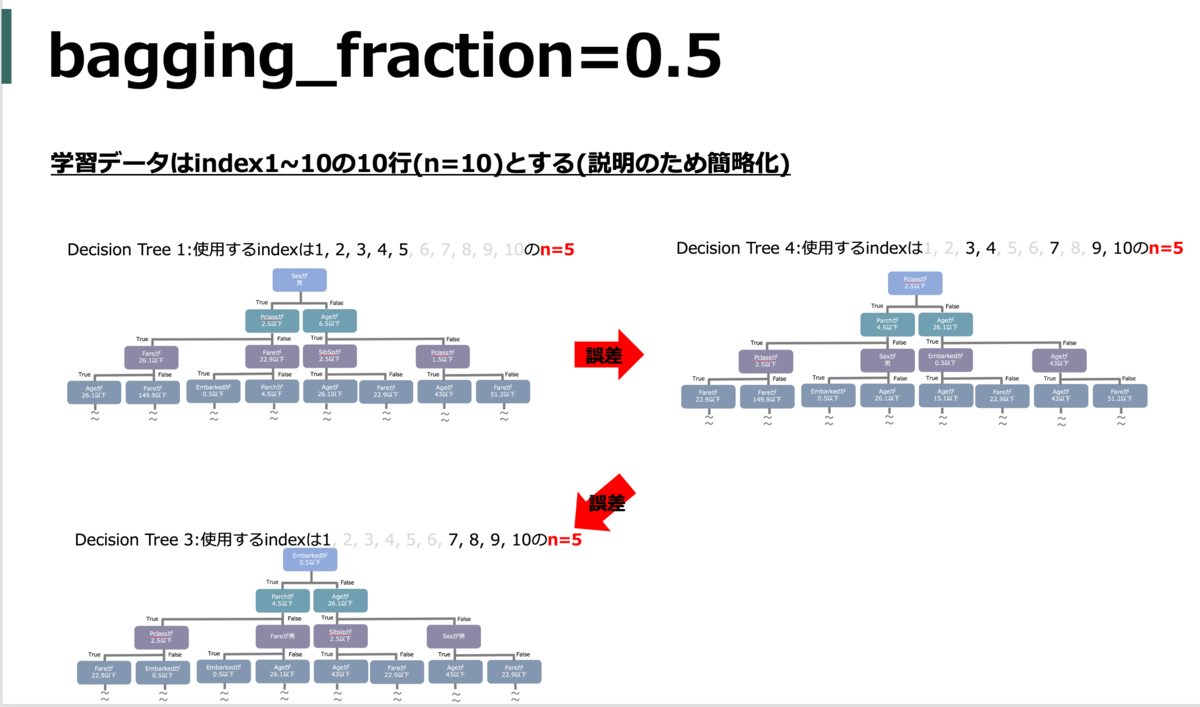
bagging_fraction(subsample)
使用するデータの割合(何%の訓練データをランダムで利用するか)
subsample_freqと合わせて使う。
default = 1.0
boosting(boosting_type)
boostingのアルゴリズムをどうするか。
基本的にはgbdt(勾配ブースティング)を使う。ただ、dart( Dropouts meet Multiple Additive Regression Trees) や, rf(random foreset )、goss(Gradient-based One-Side Sampling) も指定できる*5。
stacking前提だとgbdt以外のアルゴリズムを使うとアルゴリズムだけ変えたモデルが複数できるので多様性的によさげ。
どういった目的関数にするか
目的関数は 目的関数 = 損失関数 + λ正則化項で表され、この目的関数を最小化(最大化)するようなパラメータを求めるのが機械学習のタスク。以下ではこの各項をどうするかのハイパーパラメータ。

objective
損失関数をなににするか。これはハイパーパラメータではなく、機械学習の目的自体なので調整対象外。

lambda_l1 (reg_alpha)
L1正則化項の影響力を調整する係数λ*6部分。
L1正則化に相当するため、重要じゃない特徴量が落とされる。過学習を抑制する。
default = 0.0のため、デフォルトでは正則化はかからない。

lambda_l2 (reg_lambda)
L2正則化項の影響力を調整する係数λ部分。
L2正則化に相当するため、重要じゃない特徴量の影響が小さくなる。過学習を抑制する。

default = 0.0のため、デフォルトでは正則化はかからない。
なお、lambda_l1とlambda_l2どちらとも指定する場合、いわゆるエラスティックネットの形になる。

どうやって学習していくか
以下はチューニングしても意味がないのでチューニング対象外(参考)。
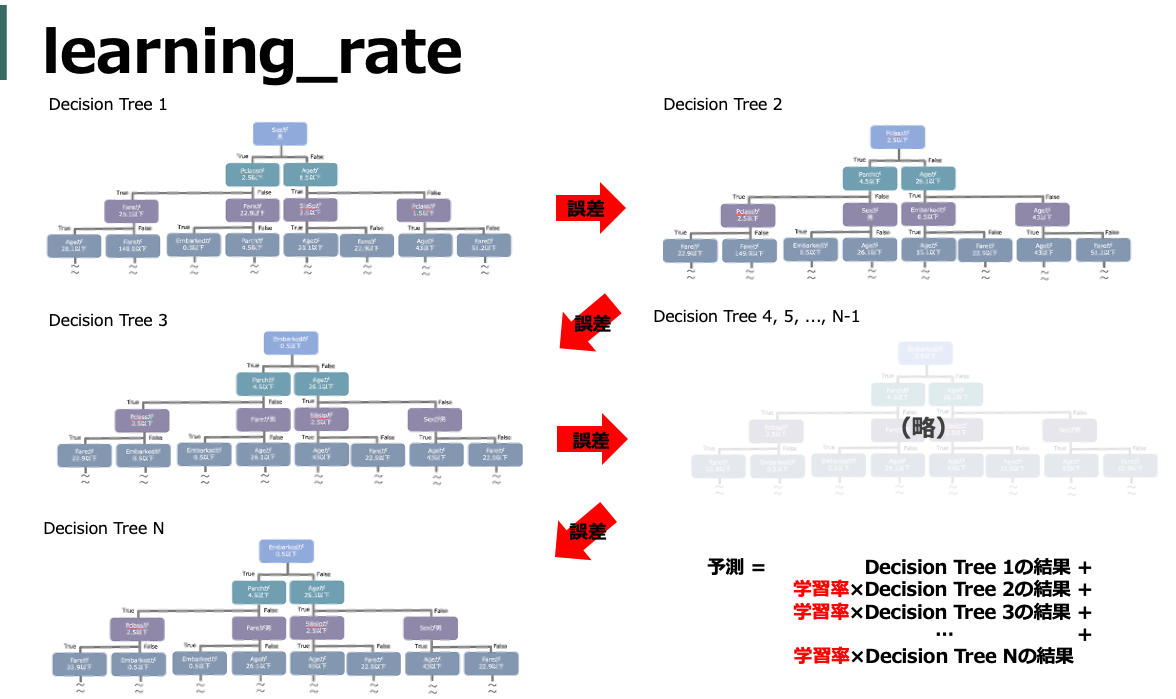
learning_rate
学習率。各木を足し合わせるときの重み。つまり、大きくするほど誤差に対して各木1つ1つの情報を多く使うのでトータルとして使用する木の数が減る。つまり、学習完了までの時間が短縮できるがその分学習に使用する木の本数が減っているので精度は落ちる。 そのため、時間が無限にあったらものすごく小さくすればいい気もするがいったん0.01あたりに固定するのが無難なようだ。
default = 0.1
eval_metric
validation データを評価する損失関数。デフォルトではobjectiveと同じになる。
early_stopping_round(early_stopping)
validation データに対して損失関数(eval_metric)の改善がされなかったら学習を途中で止める(いわゆるアーリーストッピング)。
default = 0 なので、デフォルトではアーリーストッピングはかからずnum_iterationsの指定数の木で学習する。


verbose
指定した学習回数毎にeval_metricを出力。

seed (random_state)
新たな木を作成する際の初期値として、木の学習に使うインスタンスの選択や特徴量候補の選択はランダムにで選択される(Bagging。なお、それぞれ自体の割合はbagging_fractionとfeature_fractionで制御)。そのときの乱数シード。
固定しておかないと再現性が担保できないので固定しとく。
おまけ:ハイパーパラメータをどういじるか
lightGBMのドキュメントにXをしたい場合はどのハイパーパラメータをどう調整すればいいのか?といったことが書いている。
前述のように、それぞれのハイパーパラメータがなにを調整しているか意味を理解した上で読むとなるほどねーとなると思うのでおまけとして書いておく。ちなみに、図は先程までの図のコピーです。
なお、以下の記事の「5. LightGBMのハイパーパラメータ」に端的に書いている。
良い結果のために特に重要
以下の3つがTreeの複雑さに関する重要度なハイパーパラメータなので、とりあえずこれらをちゃんと調整すると良さげ。
num_leaves
Treeの複雑さを制御する。理論的には2max_depthが最大の複雑さだが、オーバーフィッティングに繋がる。
前述のように、最大ノード数の7割にしたい場合max_leaves = int(0.7 * 2 ** max_depth)のように指定したりするらしい。
min_data_in_leaf
num_leavesと同様にTreeの複雑さを制御する。オーバーフィッティングを防ぐのに重要。サンプルサイズとnum_leavesに依存するが大規模データセットだと一般的に数百から数千くらい。
max_depth
木の最大の深さを制御するので、深くなるほど複雑になる。つまり、Treeの複雑さを制御する。
速度を上げる
計算リソースを増やす
num_threadsで並列計算をするスレッド数を増やせる。
ツリーのノード数を減らす
LightGBM の総学習時間は、使用するツリーノードの総数に応じて増加するのでツリーのノード数を少なくすると高速化する。具体的にはmax_depth、num_leavesを小さくする。ただし、学習が浅くなるので精度が落ちる可能性があるので注意。
(max_depth=2と4) (max_depth=2と4)
また、min_gain_to_splitを増やす(デフォルトは0.0)ことで、分割をするために必要な最低ゲインを調整できる。例えば、ゲインが0.00001のような分割はほぼ分割されてないのと同じ(情報量が増えない)なのであまり意味のない分割となる。そのため、意味のあまりない分割しかできないくらい分岐がされたらその段階で分割をストップするようにする。
更に、レコードがあまり存在しないようなノードが作成されることがあるがこれはオーバーフィットの要因にもなり捉え方によっては不要な分割となる。前述の'max_depth' 'num_leaves'で結果的に制御されることもあるがmin_data_in_leafと min_sum_hessian_in_leafで明示的に制御することもできる。
具体的には、min_data_in_leafはノードを作るのに最低限必要なレコード数 で、 min_sum_hessian_in_leafはノードを分割するときのロスの(hesianの合計の)小ささ。なのでこれらを大きくすることでノードを作成しづらくできる。
木の数を減らす
作成する木の数(boosting round)を制御するnum_iterationsを小さくする。なお、その際は学習時間には関係ないが精度が落ちるのでlearning_rateを増やす必要がある。
また、アーリストッピング(early_stopping_rounds)を用いることで学習する木の数を小さく(途中で学習をやめる)することができる。
分割数をへらす
木の分割数を減らすことで学習時間を短縮できる。ただし、その分木がシンプルになるので精度が落ちる可能性が高くなる。
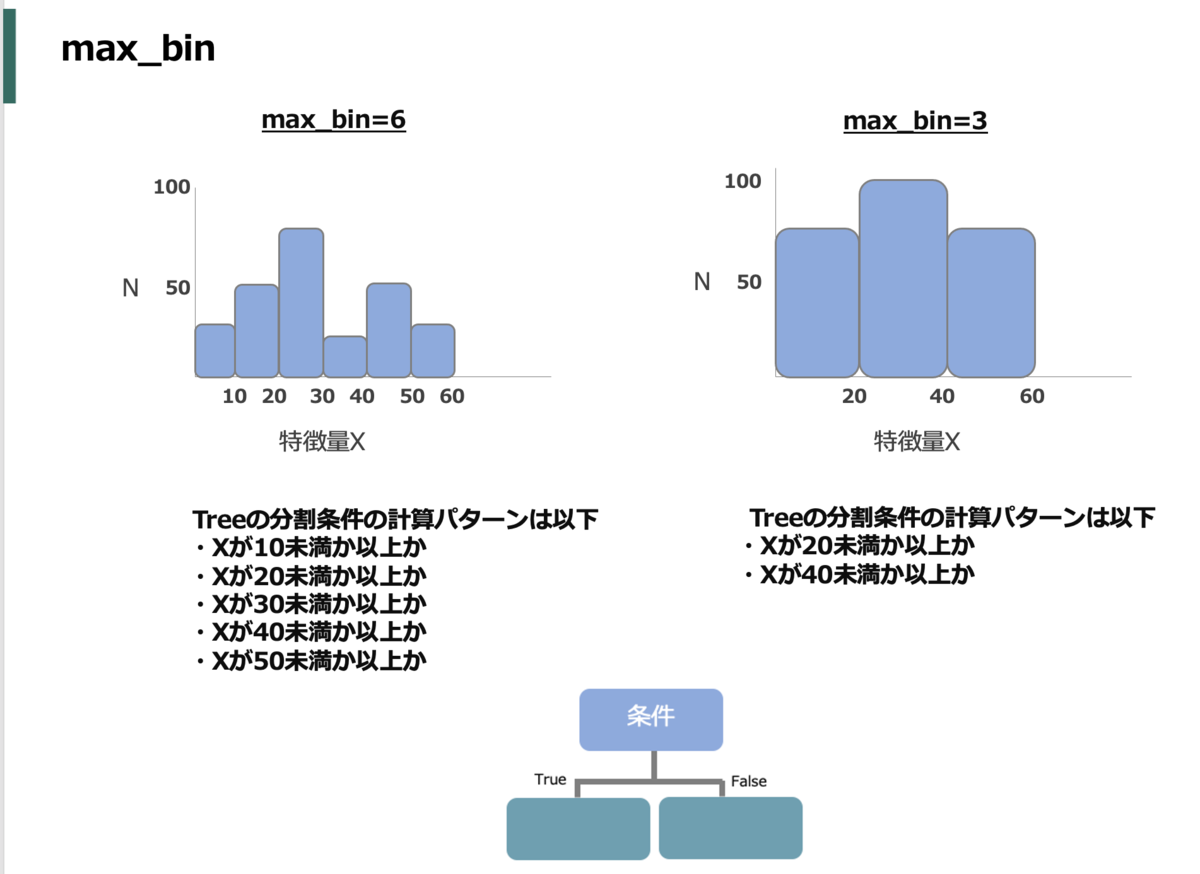
lightGBM特有だが、データを読み込んだ際に各特徴量ごとに値のbinningが自動でされる。これはmax_binで binを最大でいくつ作るかを制御できるので値を小さくするほど作るbinの数が減って分割時の計算が簡単になる(max_bin_by_featureで特徴量毎に決めれる)。
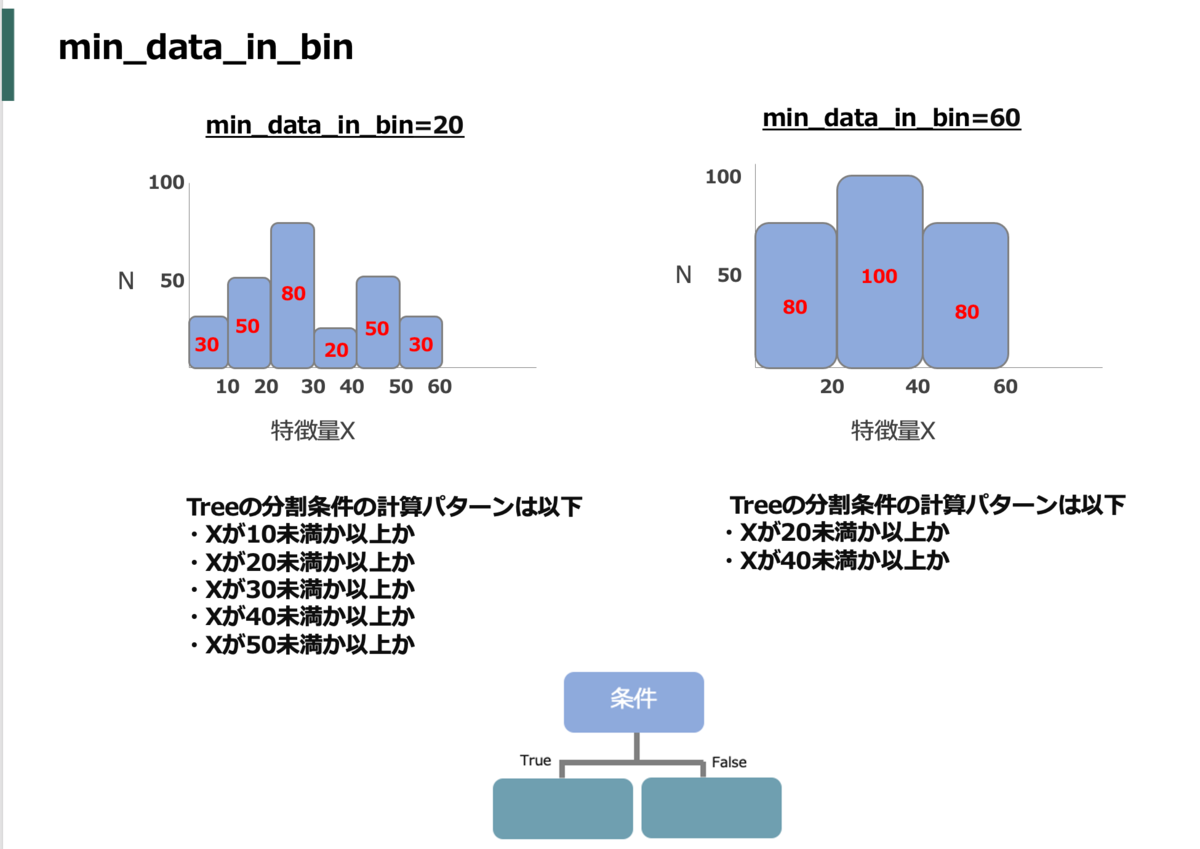
また、max_binと似ているがbin内のデータ数の最小値min_data_in_binを大きくすることで結果的にmax_binを小さくするのと同じようなことが起きてbinの粒度を荒くできる(イメージとしては)。
feature_fractionは分割の検討をする特徴量の割合を制御する。デフォルトでは1.0なので全特徴量を検討するが、例えば0.5のときはランダムで半分の特徴量しか分割の検討をしない。つまり、検討数が減るため高速化する。
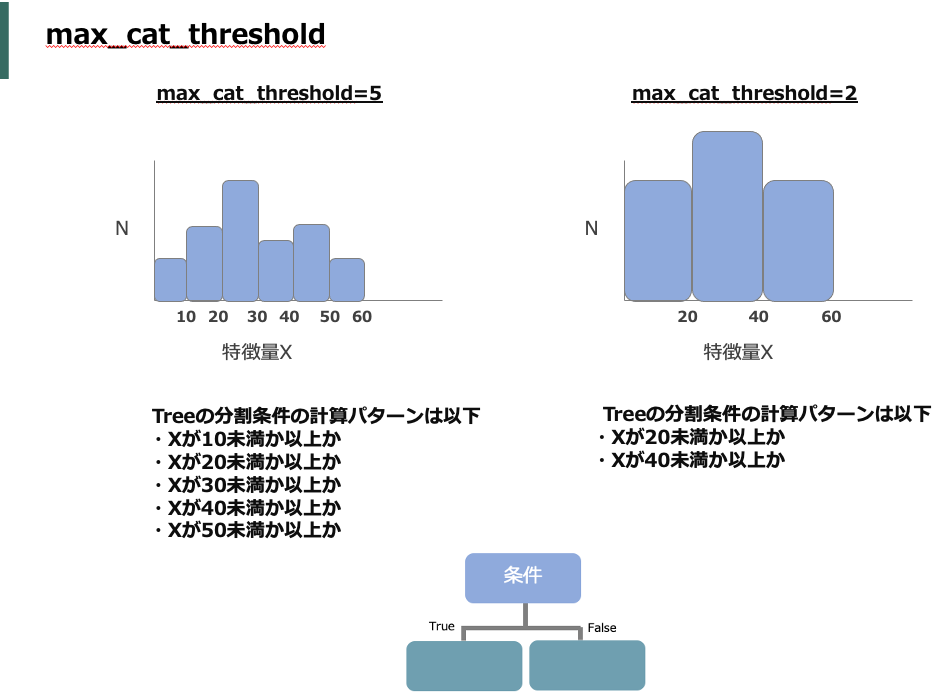
max_cat_thresholdは特徴量の分割点数を制御する。例えば3であれば分割の仕方が最大で3分割となる。そのため、小さくするほど計算が少なく住むので値を小さくすると高速化する。
データ数を減らす
各木の作成時にデフォルトでは常に全データを使うが、bagging_fractionを用いることで使用するデータの割合(ランダムサンプリング)を制御することができる。なお、セットで使うbagging_freqで何回ごとにランダムサンプリングをするかを制御できる。
精度を上げる
以下は力尽きたので詳細は省き、端的に。基本的には複雑な木を作る、という意味合い。そのため、どの場合も学習時間が伸びるとともに、(トレーニングデータへの)過学習に繋がりやすいので注意。
大きなmax_binを使う
max_binを上げるということは 、要は分割点を増やす=複雑な木にする、ということなのでその分精度が上がる。
小さいlearning_rateと大きなnum_iterationsを使う
learning_rateを小さくするほど多くの木を使用することになるので精度を上げることができる。また、この際に作成する木の上限数自体が少ないとあまり意味がないのでnum_iterationsも増やす。
大きなnum_leavesを使う
複雑な木を作成
トレーニングデータを増やす
学習に使うデータは多いほど良いよね的なよくある話。
boostingのアルゴリズムでdartを使う
GBDT(のMART)の正則化としてDrop Outの概念を入れて過学習を防ぐアルゴリズムらしい。
詳細は以下がよくまとまっている。
オーバーフィッティングを避ける
こっちも力尽きたので詳細は省き、端的に。こっちはシンプルな木を作る、という意味合いが強い。そのため、どの場合も学習時間が速くなるが、(トレーニングデータへの)精度は落ちやすいので注意。
小さなmax_binを使う
binの数が減るのですなわち分岐点を大雑把にする
小さなnum_leavesを使う
木をシンプルにする
min_data_in_leafやmin_sum_hessian_in_leafを増やす
データの分割を大雑把にする
bagging_fractioとbagging_freqをつかってbaggingの調整をする
木毎に使われるインスタンスが異なりやすくなるため、木の多様性に繋がる。
feature_fractionを使って特徴量のサンプリングを調整する
木毎に使われる特徴量が異なりやすくなるため、木の多様性に繋がる。
トレーニングデータを増やす
学習に使うデータは多いほど良いよね的なよくある話。
lambda_l1、lambda_l2、min_gain_to_splitで正則化の調整をする
正則化項の影響を強める
max_depthを小さくする
木が深くなりすぎないようにすることで複雑さを抑える
extra_treesでExtremely Randomized Treesを作る
理屈上、多様な木ができるため汎用性が上がる
path_smoothを増やしスムージングの調整をする
正則化項の影響を強めるのと同意。
参考
有名ライブラリと比較したLightGBM の現在のP29あたり