データ解析のための統計モデリング入門① 2章 最尤推定
通称緑本こと、「データ解析のための統計モデリング入門」の再読をしたのでメモ。
今回は最尤推定について(2章)
")
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者:久保 拓弥
- 発売日: 2012/05/19
- メディア: 単行本
最尤推定とは
得られたデータを元に、数理モデルのパラメータを特定する方法として、最尤推定(maximum likelihood estimation)がある。
ある数理モデルにおいて、観測データ(標本集団)の当てはまりの良さ、言い換えると、観測データの尤もらしさを尤度という。
尤度は、観測データのそれぞれの値がその数理モデルから得られる確率の積、つまり数理モデルからその標本集団になる確率 = 同時確率のことをいう。
例えば、ポアソン分布において、 なので、尤度は
となる。
尤度が最大になるときのパラメータを最尤推定値という。尤度が最大とは、つまり標本集団が得られる同時確率が最も高くなるパラメータと考えることもできる。
また、計算上の理由で対数化した対数尤度から計算することが多い。
シミュレーション
ポアソン分布から生成された(母集団の分布がポアソン分布)となっている観測データを考える。 ポアソン分布に従うデータは、平均値をパラメータλとした以下の式に従うとされている。
平均値λ=3.5として観測データを生成する。
>data <- rpois(10000, 3.5) > data [1] 1 1 5 4 4 3 2 3 2 3 6 1 2 5 3 2 1 2 3 0 0 5 3 1 1 2 4 5 4 3 3 2 1 7 5 6 4 5 1 9 4 1 3 2 2 4 3 5 5 2 ...
この、パラメータλ = 3.5のポアソン分布から乱数選択したデータを、何も知らない状態で考える。
このデータはポアソン分布から生成されたと仮定して未知のパラメータλの最尤推定をおこなう。
logL <- function(m) sum(dpois(data, m, log = TRUE)) lamdba <- seq(2, 5, 0.1) plot(lamdba, sapply(lamdba, logL), type = "l")
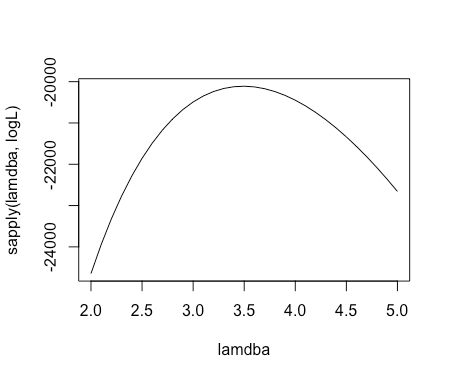
最尤推定したλは3.5前後あたりに存在しそう。
この値は真のパラメータλは3.5なので、最尤推定法によりこのモデルの真のパラメータをおおよそ推定することができた。
最尤推定法はポアソン分布以外のあらゆる数理モデルで用いることができる。ただし、複雑な数理モデルでは最尤推定値を導出するのが難しいので近似値などを用いる。
なお、データがどのような確率分布から生成されたかは以下の点に着目して考える。
- 説明したい量は離散か連続か?
- 説明したい量の範囲は?
- 説明したい量の標本分散と標本平均の関係は?
上記のような特徴を得られたデータから考え、特徴に当てはまる確率分布を用いる。例えば下記のようなものがある。
- ポアソン分布 : データがリアんち、ゼロ以上の範囲、上限なし、平均≒分散
- 二項分布:データが離散値、ゼロ以上の範囲、上限あり、分散は平均の関数
- 正規分布:データが連続値、範囲が[-∞, +∞}、分散は平均と無関係
- ガンマ分布:データが連続値、範囲が[0, +∞}、分散は平均の関数
余談
当たり前のことだが、最尤推定法はあくまで観測データに対してある確率分布の仮定をしたときに最も尤もらしいパラメータ(当てはまりの良いパラメータ)を求めているだけなので、分布仮定が誤っている場合(真の分布ではない分布を仮定したとき)はパラメータが真のモデルのときと最尤推定では大きく異なる。
最尤推定を用いたモデルの推定である一般化線形モデル(GLM)などについて多くの場合、大規模データでは中心極限定理より確率分布が正規分布に近似できるので、(別記事で書いた条件を満たした場合は)最小二乗推定値の方がモデルの係数についてゆるい仮定のもと推定できるため頑強(ロバスト)に推定できる。
ただし、あくまで近似なので確率分布の仮定が正しい場合は最尤推定値の方が真の値に近いので状況によって使い分ける必要がある。