SQLで連続課金日数を計算し、その最大値を求める
ユーザー毎の最長連続課金日数を求める。
Redshiftを想定。
データイメージ
「課金」列はその日課金した場合は1、課金してなかった場合は0となる。

『連続して○○した日数』をどうやってSQLで求めるか?がポイントとなります。
SQLなので、集約関数やWINDOW関数などを使えば簡単に連続した日数を計算できると思いきや、
SUM関数を使おうにも、下図のように、「同じuser_id」かつ「連続している日」を集計領域にする必要があり、案外頭を使った。

ポイント
- 「同じuser_idで課金日が連続している」部分を集計領域にした集計関数を使う。
- そのために、「同じuser_id」かつ「課金している日が連続している」という集計領域を指定するための判定列を作成する。
======= 2021/06/26追記 =======
自社の技術ブログにこの記事をリライトしたものを載せていました。
記事中に積み上げ和を表現するのに、SUM(x) OVER (PARTITION BY xx)というコード記述があるのですが、以下のような御指摘を(技術ブログの方に)受けました。
先日の「連続で結果xが出た回数」の時もでてきたのだけど、もしかしてPostgreSQL/redshiftとBigQueryでwindow関数のsumの挙動が違う?BigQueryだと積み上げにならないでウィンドウごとの和(user_idごとのフラグの数)になる。「ROWS BETWEEN UNBOUNDED~」を入れないと積み上げにならない。 https://t.co/pRWULYlrGG
— しんゆう@データ分析とインテリジェンス (@data_analyst_) 2021年6月25日
御指摘の通り、BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW が無いと**積み上げ和ではなく、PARTITION内での総和となってしまいます。
たしかに。僕もいつも累積和のときはROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWいれてるんですが、記事だと入ってないですね。
— 森下光之助 (@dropout009) 2021年6月25日
いま試してみたんですが、redshiftでもこれいれないと積み上げにならないっぽいですね(ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWINGになる) pic.twitter.com/sNe9Sho6GC
そのため該当箇所をORDER BY user_id, log_date BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWを加えて修正致しました。
御指摘ありがとうございますm( )m
なお、技術ブログの方がリビルドしている分シンプルに書いてます。
======= 追記ここまで =======
1.同一user_idでの手前のuser_id, log_date, pay_flgを取得
ユーザーID・課金状況・日付が「連続しているか」を判定するための準備として、いったん手前のレコードの値をLAG関数を用いて取得する。
LAG(user_id,1) OVER (PARTITION BY user_id ORDER BY log_date) AS lag_user_id ,LAG(log_date,1) OVER (PARTITION BY user_id ORDER BY log_date) AS lag_log_date ,LAG(pay_flg,1) OVER (PARTITION BY user_id ORDER BY log_date) AS lag_pay_flg
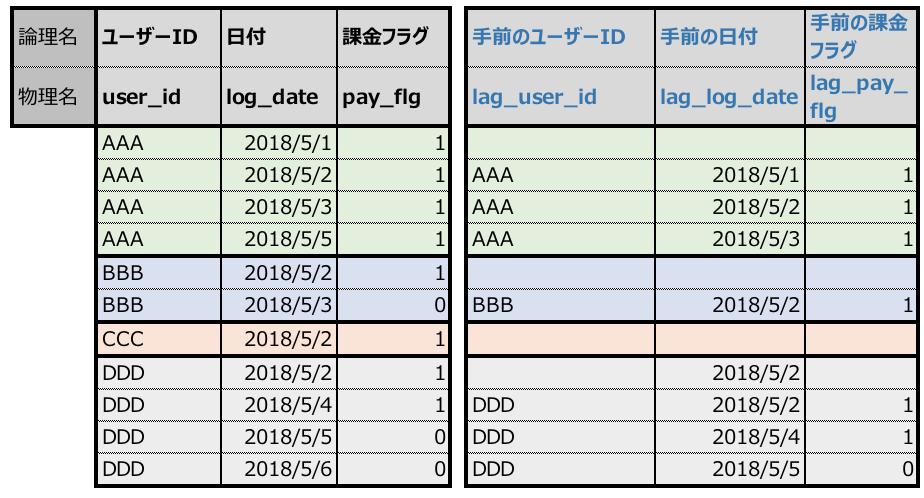
2.同一user_idで「日付が連続していないか」を判定。
1.で取得したLAG関数を用いた列を利用して「日付が 連続して いない か」を判定。
4.で後述するが、ここでは「連続して いる か」ではなく「連続して いない か」を判定して、「連続していない」場合は1、「連続している」場合は0を取る。
CASE WHEN user_id = lag_user_id AND log_date <> DATEADD(day, -1, lag_log_date) THEN 1
ELSE 0
END AS not_cont_date_flg

3.同一user_idで「手前の課金状況と変わっているか」を判定。
- 「手前のレコードが課金している」&「現レコードで課金してない」
- 「手前のレコードで課金してない」&「現レコードで課金している」
で1となる。
つまり、課金について変化があれば1になるし、手前と同じ課金状況なら0となる。
先程取得したLAG関数を用いた列を利用して判定。
CASE WHEN user_id = lag_user_id AND pay_flg <> lag_pay_flg HEN 1
ELSE 0
END AS change_pay_flg

4.「日付が連続していないか」「手前の課金状況と変わっているか」の積み上げ和を作成
この節で、 「同じuser_id」かつ「課金している日が連続している」という集計領域を指定 を積み上げ和を利用して実現する。
同じ集計領域に所属させる、つまりGROUP BYで指定した列の値が同じにするためにはどうしたらいいだろうか。 同じ集計領域では0を足し、別の集計領域になったときに1を足す積み上げ和をおこなうことでこれを実現できる。 今回、同じ集計領域としたいのは「日付が連続している」かつ「課金状況が連続している」ものである。
そのため、2,3で、「日付が連続している」「課金状況が連続している(課金状況が変化しない)」場合はそれぞれ0、違う場合は1。言い換えると「日付が連続していない」「課金状況が変化している」場合はそれぞれ1、違う場合は0とすることで、これらに対してそれぞれ積み上げ和をすると、集計領域の指定用列を作成できる。
一般化した言い方をすると、「集計領域が同じ場合は0、集計領域が変わる 切れ目 で1となるような列を指定して積み上げ和を作成する」と集計領域の指定用列が出来上がる。
SUM(not_cont_date_flg) OVER (PARTITION BY user_id ORDER BY user_id, log_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_not_cont_date_flg ,SUM(change_pay_flg) OVER (PARTITION BY user_id ORDER BY user_id, log_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_change_pay_flg

5.課金しているもののみに絞り、cum_not_cont_date_flgとcum_change_pay_flgで集計をおこない、個数を数える
・pay_flg = 1のみに絞る
・cum_not_cont_date_flgとcum_change_pay_flgをGROUP BYに指定し、レコード数を数える
以上で、「同じuser_id」かつ「課金している日が連続している」という集計領域を指定できたため、課金の連続日数が求まる。
SELECT
cum_not_cont_date_flg
,cum_change_pay_flg
,SUM(1) AS cont_pay_date
FROM
hogehoge
WHERE
pay_flg = 1
GROUP BY
cum_not_cont_date_flg
,cum_change_pay_flg
;

6.user_id毎で最大連続日数を取得する
あとは、同じユーザーID内での最大連続日数を取得すると目的の値が求まる。
SELECT
user_id
,MAX(cont_pay_date) AS max_cont_pay_date
FROM
fugafuga
GROUP BY
user_id
;

まとめ
連続した◯◯を取る場合、
1. 連続して課金している部分/連続して課金していない部分で集計領域を分けてGROUP BYする
2. 集計領域を識別させるために、連続してる場合は0、連続しなくなった 切れ目 を1取るようにする
このあたりを意識すると作成できる。
参考
最大連勝、連敗を抽出するSQLyone64.wordpress.com
こちらのエントリを参考にさせてもらった。
違いとしては
1. 上記エントリでは、本記事でいう「連続した日数」のみが連続条件となっているが、本記事では連続の条件が「連続した日付」「連続した課金」の2つ
2. 上記エントリではグループ化に際して自己結合をおこなっているが、本記事では「変化したか」でグループ化をおこなっている。
そのため、自己結合と較べて記述が楽&クエリコストが相対的に低い