成長するためには手癖でやらないためのシステムが必要
前回に引き続き怪文書ポエム。
記事に書いたが、最近手癖で行動してしまっている。
手癖、つまり慣れたやり方は楽。しかし成長の観点で言えば、同じことをなんとなくやっているだけなので成長は皆無は言いすぎかもしれないが非常に緩やかになるし、飛躍はない。
生産性と成長
話は変わるが、会社の上長と話していて生産性の話になった。そこで、以下の本を勧められた。

その中に、「生産性 = 得られた成果 ÷ 投入した資源 = アウトプット ÷ インプット」という記載があります。生産性を上げるには、得られた成果を増やす or 投入した資源を減らす の2つしかない。
つまり、「時間を増やさずにどうやったらより良い成果物になるか」「時間をかけないにはどうすればよいか」を考えていくことで、「短時間でより良いアウトプットを出す」ことができ生産性を上げることができる。
成長とは何か考えると、「より良い成果物が出せるようになること」だと考えていたし正しい側面ではあるが、より良い成果物を出すために今まで以上に時間がかかっていたらそれは成長といえるのか。時間は有限なので、例えばあるアウトプットを出すのに8時間使っていたので類似案件はよりよいものを出すために10時間使いました。そのあと、さらに類似案件をよくするために12時間使いました...となるとキリがないし24時間を超えたところで「成果物のより良さ」は頭打ちになる。
一方で、生産性を意識しながら行動をすると頭打ちにならずに、成果物をより良くし続けることができる。また、使う時間は同じあるいは減るので他のことに時間を回すことができるので、さらなる学習機会を得ることができる。これがまさに成長かと。
ちなみに、上記書籍の作者(と言われている別名)で生産性と成長というそのものズバリな内容について書いている。
脱手癖
成長のためには手癖でやらない。
では手癖でやらないためには?
以前の記事でも書いたが、「xxしない!」は根性論なので長続きはしない。そのため、システム化が必要になる。
一番簡単なのは、「どうすれば同じことを短時間でできたか」「どこを改善すべきだったか」といったPDCAをまわす作業を自動化することだろう。日報とかはその一環かな、と思う。
では、どのように自動化するか。他者に宣言して半強制力を生むことでやり忘れを回避、グーグルカレンダーにリマインド登録をする、あたりがよくある方法だと思うのでとりあえずそれを試してみる。
データ分析プロジェクトを主体的にこなすためには
ただの雑記怪文書です。
近況と問題意識
最近、分析プロジェクトの全フローを担当するようになった。
前期では表面上は「先輩データサイエンティストと共におこなっていた」ことになっているが、実質的には「先輩データサイエンティストの考えたモデルに沿ったコードを書いて数値を報告する」ことをおこなっていた。
つまり、以下のようなことは先輩データサイエンティストに無意識に丸投げしていた。
- 何が目的か考える(&そのために、クライアントとのやりとりをメールなど漁ったり営業に詳細を聞きにいく)
- 目的に沿った手法/モデルは何か考える(&類似目的の論文など調べる)
- 出た結果に関して解釈を考える(&ドメイン知識がある人と結果について考察し合う)
- 結果をまとめる
問題点
ありていに、一言で言うと「考えることは先輩に丸投げした脳死で作業していた」ことになる。
何故そんな状態になったか考えたのだが、理由として「自分で考えないでも先輩が勝手に考えて進めてくれる」から。手法や解釈を考える場は先輩と議論していた。一人より複数人で議論しながらの方が良いアイデアが思い浮かぶので、都度議論するのは当たり前だが、このとき私は何も考えてなくてただただ先輩の壁打ち役になっていただけのように思う。
何故壁役になっていたか考えると「先輩が強い」から。正確には「先輩が強いと思い込んで萎縮しているから」「今まで考えてきていないから壁以外できないから」。
また、要件定義のために「何を目的とするか」自体をちゃんと考えていないし、そのためのドメイン知識もあまり持っていない。故に、そもそも考えが出てこない。
このままではいつまでたっても先輩がいないと何もできないゴミカスである。また、市場価値はゼロとなる。
さらにいえば、営業などのステークホルダーとのコミュニケーション、例えば「全体のワークフロー/スケジューリング/結果イメージを考えて、営業などと結果イメージ/スケジュールに合意を得る」といったようなこともしていなかった。
つまり、自分以外のステークホルダーからすると全体感と進捗が読めないことになる。そうなると、「どういう内容ならはどれくらいの作業工数になりそうか」という見積もりがステークホルダーができないし、「進捗どおりなのか」もわからない。更にいえば、「何を作ろうとしているかわからないので、完成したものが筋違いな可能性がある」。
これも要は何も考えずに来たものを処理することしか考えていない脳死行動を取っているのが原因だと思う。
対策
脳死にならないためには。
一言で言えば、手癖が「脳死で目の前のことをただ処理する」なので、「手癖でやらない」が対策となる。
「xxしない!」は根性目標なので、はじめは続いても続くわけがない。つまり、システム化する必要がある。
分析プロジェクトが立ち上がったら、プロジェクトテンプレートを用意しその項目を自分で埋める形で行動していく。営業や先輩データサイエンティストにその旨を伝えることで常にそのテンプレートを使わざるを得ない環境を作る。
また、要件定義の議論は気づいたら何も考えていないで先輩が決めた要件定義になってしまうのでプロジェクトテンプレートのtoDoは「要件定義を先輩と考える」ではなく「自分なりの要件定義を一人でx分考える」を挟んだ上で「要件定義を先輩と考える」とすべき(x分、としているのは考える行為はキリがないので時間で区切るため)。
もちろん、結果的には先輩発案の要件定義内容になることが大半だとは思うが、自分で考えることを繰り返していくことで要件定義の精度が上がったり、先輩とは別の視点での定義が生まれると思う。とにかく、「自分の頭で考える」トレーニングを積むべき。
また、考えるのに必要な素材としてドメイン知識が必要なので、営業と目的についてすり合わせたり、考えたアウトプットイメージをすり合わせる、といったコミュニケーション系もテンプレートに入れておくことで手癖でやってしまうと漏れそうな必要な行為を防ぐ。
2019年3Q OKR
2019年2Q振り返りを踏まえて、3QのOKR作成。
OKRについては以下にざっくりまとめてる。
Objective
「独立したDSに!」
まぁ前期OKRとほぼ同じだがちょっと意図変えた。
下流はまぁそれなりにできるようになったので今期は上流(要件定義)ができるDSになる。
要件定義は
①ドメイン知識に沿った需要を満たす目的
②目的を達成するために道具をどう使うか
この2つに分解できるかと。それぞれに対応するKRを立てる。
KR
KR1
「案件において、自分で要件定義をしたものが8割」
他の人の意見でよりよくはなると思うので、正確には「ベースとなる定義は自分で考える」。
そのための週の行動指針は
- 案件xxについてコンサル部門/営業部門の人と話す
- 営業/コンサルとの接点を増やしてドメイン知識を得る
とかか
KR2
「案件を3つ作る」
需要考えて自分で案件を考え提案する。
そのための週の行動指針は - (ビジネスフローを分解したときの)領域xxについて、需要がありそうなこと考える - 上記について、営業/コンサルと議論する - 営業/コンサルが言っていた○○について解決策をx個考える
とかか?
KR3
**「仕事関連の論文を10本読む」
道具を増やす、道具のよりよい使い方を学ぶ
そのための週の行動指針は
- 調べたい領域を考える
- 論文何件か見つける
- 読む
- そのために必要な理論学ぶ
- ブログ書く
あたりか
その他
OKRちゃんと振り返るの難しいから、どうするかですね。。。問題意識のもと、OKRに沿った行動は無意識にやってはいるけど定期振り返りはしてないからOKRではないよね。。。
てか自転車通勤だから自転車乗りながら振り返ればいいのか。。。
勉強する時間はある程度決まっているので、グーグルカレンダーかなんかに時間割みたいにやることを曜日毎に決めてスケジュール先に入れたらいいんかなー。
あとKRを達成するために今週はなにをするか?が毎回難しい。というか同じになる。だからやらなくなるんのかな。
解決策
- めんどいし土日は不確定要素多いので振り返りと翌週の目標(P)設定は週初めにまとめてする
- KR考える/振り返る/見直す系は出勤中(雨天時以外は自転車)にする
- 知人巻き込んで、週振り返り/週目標設定を一方的に報告する会設立→半強制力でちゃんとする&リマインドになる
- 内容はTrelloで管理
まぁこんなところか。
2019年2Q振り返り
今期やったこと
仕事
- 階層ベイズ
- シミュレーション
- ログ解析(Rでくそめんどい集計して傾向見る)
- 簡単な集計多数
自学
- 使った技術と、それをベースに横展開した技術を学んだ
- ブログでちゃんとアウトプットをした(6月は案件炎上したから1ヶ月くらい書けなかったけど)
OKR振り返り
一応OKR立ててたけど相変わらずほぼ見てない。このダメさは運用の仕方に問題あるなこれは。。。 knknkn.hatenablog.com
ちなみにKR1「過去のDSプロジェクトを把握し使いこなす」のと、3「ドキュメント(英語)をちゃんと読む」はまぁそれなりにできたかな、と。
KR2「自分でモデルを考える」はゴミ。というか、モデルというより要件定義自体だな。
環境
禁煙しました(2ヶ月目)。
今まで10年近く、喫煙しながら勉強していたのでそのあたりの勉強とセットになる習慣が禁じられたため慣れるまで苦労した。
反省
Objective「ある程度自立したDSになる」だったが、ある意味で達成、ある意味でゴミ。
というのも、手を動かすことに関しては、必要になると超速で学習しながらやることで割とできるようになった。一方で、要件定義が完全思考停止で言われた定義に沿って手を動かすだけマンと化していた。
言い訳をするならば、上流の人の要件定義力が強いためこっちが考える間もなく(あるいは、考えなくても)勝手にそれ以上の要件定義が思い浮かばないなぁとなって決まるので自然とそうなっていた。
ただ、そうなると「なんのためにこの分析をしているか」という目的がなんとなくでしか理解していなかったりすることが多いので、結果の解釈がしづらかったり、細部の要件が漏れていることに気づけなかったりとムダが多い。
なによりも、自分で分析設計ができないDSの市場価値は低いためキャリア的に死ぬ。
今期を踏まえて
アウトプット
学習したらアウトプットするのはこのまま続ける。正直、自分用メモに近いので「自分が思い出せてわかればいいや」程度の書き方をしていて読者を想定した書き方にあまりなっていない。ここは改善の余地はあるのだが、そのことで書くハードルが上がることが懸念される。
もちろん、読者を想定するとちゃんと調べるためより学習が深まるという効果はあるが、今もまぁそこそこ調べているので個人的にはこれくらいのバランスでいいと思う。
学習対象
割と事前にやっといた方がよい基本的なハードスキルはやり終えた感。
あとは、仕事で必要になったら(横展開含む)学習していく方向で。
ただ、論文を調べる能力や解釈すること、それ以前に数式(特に行列)がへちょいのでここをどうするか。分野の論文把握は、使える道具を増やすことになるのでマスト。ただし、細かい理論となると俺にその部分は必要か?となる。
まぁ例えば、「機械学習の細かい理論までは知らなくていいけどざっくり把握をしとくとパラメータチューニングや使い分けができるようになる」といったような効能はあるので、ざっくり把握ができる程度の解釈能力は必要そう。
要件定義力
これはもう慣れかな、と。慣れだが、前述のような理由で自然状態ではいつまでも慣れることはない。ゆえに自分から取りに行くスタイルが必要。
案件がくると、いつのまにか要件定義をされているのでいったん他の人の意見を聞かないでいったん考える時間をもらうようにする。そうしないと結局何も考えれない。
あと、そもそもどういうことをすれば会社的に需要があるか、という部分が弱い気がする。実際、入社1年目はワンオペで手を動かすことで手一杯だったし、人が増えてからはスキルを得ることにていっぱいだったしで、ドメイン知識よりも他のことをまず得よう!という意識でいたのでわざとだけど。
とりあえず手を動かせるようになったのでドメイン知識を得に行こう。それがないとそもそも、いい感じの分析設計はできないかと。
資源の最適な配分を、ディリクレ分布を用いたシミュレーションから求める
やりたいこと
なにかしらの資源をどう分配したら効用を最大化できるか、ということを解析ではなくシミュレーションによって求める。
例題
今回、例として「総予算上限10万円分で各時間帯にCMを打つ。そのとき、3回以上CMに接触した人数が多いCM投下パターンを求めたい。」という例題で考える
条件
CMを打つ時間によって広告費が変わる
設定
テキトーに以下のような値段設定にする(なんとなく人が多そうな時間ほど高くした)。
| 時間 | 広告費 |
|---|---|
| 0時 | 1000 |
| 1時 | 800 |
| 2時 | 600 |
| 3時 | 400 |
| 4時 | 200 |
| 5時 | 600 |
| 6時 | 900 |
| 7時 | 1500 |
| 8時 | 2000 |
| 9時 | 1500 |
| 10時 | 1500 |
| 11時 | 1500 |
| 12時 | 2000 |
| 13時 | 1500 |
| 14時 | 1500 |
| 15時 | 1500 |
| 16時 | 1500 |
| 17時 | 1500 |
| 18時 | 3000 |
| 19時 | 5000 |
| 20時 | 4500 |
| 21時 | 4500 |
| 22時 | 3000 |
| 23時 | 2000 |
実装
CM投下パターン
各時間帯にどれくらいの金額を使うか、ランダムに配分をおこなう。
その際、ディリクレ分布を用いる。ディリクレ分布とは簡単にいうと「各面の出やすさをパラメータで設定した多面サイコロを振ったときの各面の出る確率」を出すことができる。「各面の出やすさが同じなら確率は等しいのでは?」と思うし、実際無限回行えばそうなるが乱数生成する場合は回数に制限があるため各面の確率はゆらぎがある。
以下に5種類の3面サイコロ結果を示す。
rdirichlet(5, rep(1, 3)) [,1] [,2] [,3] [1,] 0.44650941 0.3393241 0.2141665 [2,] 0.23953497 0.5266908 0.2337743 [3,] 0.05629639 0.4216316 0.5220720 [4,] 0.03596511 0.1777634 0.7862715 [5,] 0.40526176 0.3653088 0.2294295
確率なので各面を足し合わせると1.0になる。
ディリクレ分布のパラメータをサイコロに例える | コード7区
今回、(サイコロで例えると)どの面も出る確率が等しい24面サイコロを振ることで各面、つまり各時間帯が選ばれる確率を生成できる。
前述のように、確率なので各面を足し合わせると1.0になる。考え方を変えると、これは1.0という数字を24つに対してランダムに配分していることになる。そのため、この確率に今回使用する予定の10万円をかけると各時間に10万円をランダムに配分した結果が得られる。
このランダム配分を1000回シミュレーションをする。
library(gtools) all_money = 10^5 # 使用する金額 n_simulation = 10^3 # シミュレーション回数 # 各シミュレーションでの、時間毎使用料金 use_simulation = tibble(simulation_no = rep(seq_len(n_simulation), each = 24), # id=セット数 hour = rep(0:23, n_simulation), money_rate = rdirichlet(n_simulation, rep(1, 24)) %>% t() %>% matrix(ncol = 1, byrow = T) %>% c()) %>% mutate(use_money = money_rate * all_money) # # A tibble: 240 x 4 # simulation_no hour money_rate use_money # <int> <int> <dbl> <dbl> # 1 1 0 0.0432 4322. # 2 1 1 0.103 10302. # 3 1 2 0.0165 1646. # 4 1 3 0.0251 2508. # 5 1 4 0.0472 4724. # 6 1 5 0.00851 851. # 7 1 6 0.0316 3157. # 8 1 7 0.156 15562. # 9 1 8 0.0373 3728. # 10 1 9 0.171 17112. # 11 1 10 0.0531 5306. # 12 1 11 0.00363 363. # 13 1 12 0.0112 1121. # 14 1 13 0.0884 8845. # 15 1 14 0.0184 1844. # 16 1 15 0.00720 720. # 17 1 16 0.00863 863. # 18 1 17 0.00893 893. # 19 1 18 0.000429 42.9 # 20 1 19 0.0668 6685. # 21 1 20 0.0152 1515. # 22 1 21 0.00644 644. # 23 1 22 0.0546 5456. # 24 1 23 0.0179 1790. # 25 2 0 0.0563 5627. # # … with 215 more rows
各時間のCM放送回数
時間毎CMの料金を先程求めた、時間毎使用料金にJOINする。各時間に使用できる料金(予算上限)は先程求めたので1回あたりのCM料金で割ることで、各時間で何回CMを放送するか決まる。
# 時間毎CM料金 hourly_price <- read_csv('./cm_price.csv') # # A tibble: 24 x 2 # hour price # <dbl> <dbl> # 1 0 1000 # 2 1 800 # 3 2 600 # 4 3 400 # 5 4 200 # 6 5 600 # 7 6 900 # 8 7 1500 # 9 8 2000 # 10 9 1500 # # … with 14 more rows simulation_hourly_cm_cnt = use_simulation %>% inner_join(hourly_price) %>% # 各時間の1回あたりCM料金 rename(hourly_price = price) %>% mutate(cm_cnt = floor(use_money/hourly_price)) # 放送可能回数 # # A tibble: 240 x 6 # simulation_no hour money_rate use_money hourly_price cm_cnt # <int> <dbl> <dbl> <dbl> <dbl> <dbl> # 1 1 0 0.0442 4423. 1000 4 # 2 1 1 0.111 11096. 800 13 # 3 1 2 0.0881 8806. 600 14 # 4 1 3 0.0497 4968. 400 12 # 5 1 4 0.0252 2524. 200 12 # 6 1 5 0.0932 9319. 600 15 # 7 1 6 0.0253 2525. 900 2 # 8 1 7 0.0113 1127. 1500 0 # 9 1 8 0.0463 4627. 2000 2 # 10 1 9 0.0238 2383. 1500 1 # # … with 230 more rows
時間毎の人の有無
今回はテキトーに乱数で作成するが、実務においては実際のユーザー行動からユーザー毎に各時間帯の滞在確率を求める。
観察できるユーザー人数は1000として、各ユーザーの各時間帯の滞在率を乱数で作成。
library(tidyverse) n_user = 1000 # 対象ユーザー数 # ユーザー毎の、各時間の滞在確率 user_prob = tibble(user_id = rep(seq_len(n_user), each = 24), # ユーザーIDを24時間分 hour = rep(0:23, n_user), #時間 prob = rep(sample(0:100, 24 * n_user, replace=TRUE)/100) # 滞在確率 ) # # A tibble: 24,000 x 3 # user_id hour prob # <int> <int> <dbl> # 1 1 0 0.84 # 2 1 1 0.1 # 3 1 2 0.82 # 4 1 3 0 # 5 1 4 0.14 # 6 1 5 0.51 # 7 1 6 0.69 # 8 1 7 0.55 # 9 1 8 0 # 10 1 9 0.75 # # … with 23,990 more rows
接触回数
各時間毎のCM放送回数と、各時間毎のユーザー毎滞在確率が求まった。そのため、これらをかけ合わせると各時間毎のユーザー毎滞在期待値が求まる。
このとき、期待値が1以上の人は1回以上接触するユーザーと考えることができるし、期待値が3以上の人は3回以上接触するユーザーと考えることができる。
simulation_resulut = simulation_hourly_cm_cnt %>% inner_join(user_prob) %>% mutate(exp_reach = cm_cnt * prob) %>% mutate(reach_1over = if_else(exp_reach >= 1.0,1,0), reach_3over = if_else(exp_reach >= 3.0,1,0)) %>% group_by(simulation_no) %>% summarise(reach_1over_cnt = sum(reach_1over), reach_3over_cnt = sum(reach_3over)) %>% arrange(-reach_3over_cnt) # # A tibble: 1,000 x 3 # simulation_no reach_1over_cnt reach_3over_cnt # <int> <dbl> <dbl> # 1 226 9106 5781 # 2 721 10618 5549 # 3 882 9026 5535 # 4 290 9649 5502 # 5 491 9694 5472 # 6 229 10332 5438 # 7 470 9940 5376 # 8 640 8784 5356 # 9 180 8813 5332 # 10 78 8286 5322 # # … with 990 more rows
3回以上接触者が多い投下パターン
上記結果より、simulation_no 226において3回以上接触者が5781を獲得していて、1000回シミュレーションをした結果では一番多い。
このときの10万円の使用配分(CM投下パターン)は以下のようになる。
simulation_hourly_cm_cnt %>% filter(simulation_no == 226) %>% print(n=24) # # A tibble: 24 x 6 # simulation_no hour money_rate use_money hourly_price cm_cnt # <int> <dbl> <dbl> <dbl> <dbl> <dbl> # 1 226 0 0.107 10677. 1000 10 # 2 226 1 0.0695 6947. 800 8 # 3 226 2 0.0597 5966. 600 9 # 4 226 3 0.0270 2698. 400 6 # 5 226 4 0.0410 4096. 200 20 # 6 226 5 0.152 15150. 600 25 # 7 226 6 0.0595 5951. 900 6 # 8 226 7 0.00883 883. 1500 0 # 9 226 8 0.00989 989. 2000 0 # 10 226 9 0.0182 1816. 1500 1 # 11 226 10 0.0163 1630. 1500 1 # 12 226 11 0.0534 5337. 1500 3 # 13 226 12 0.0289 2895. 2000 1 # 14 226 13 0.00924 924. 1500 0 # 15 226 14 0.00603 603. 1500 0 # 16 226 15 0.130 12969. 1500 8 # 17 226 16 0.0312 3125. 1500 2 # 18 226 17 0.0810 8097. 1500 5 # 19 226 18 0.0257 2566. 3000 0 # 20 226 19 0.00753 753. 5000 0 # 21 226 20 0.0184 1842. 4500 0 # 22 226 21 0.0295 2946. 4500 0 # 23 226 22 0.00714 714. 3000 0 # 24 226 23 0.00427 427. 2000 0
おまけ
実際のCM投下はここまで単純ではないです。
また、時間帯ごとCM回数は切り捨てにしているので各シミュレーションで全使用料金が変わる問題があります。
さらに言えば、そもそも投下回数が1回の時間帯では、接触期待値部分は1 * 確率(1以下) ≦ 1 となるので100%じゃない限り誰も接触していないことになるのでそれは直感とは反していることになるので少し不適切な気もします。
Stanのmodelブロックの意味
Stanを書くとき、モデル式を書いてそれをコードに落とし込むという流れで書いている。感覚的にコードを書いているのだが、冷静に振り返ると何故ここにこれを書くのか?ということがわからなくなってきたのでメモ。
というか、前の記事みたいにエラーが出た際に「データが複雑すぎるから初期値で条件を縛る必要性が出た」という判断をしましたが、「そもそもこの書き方であっているのか? = 意図しない意味わからんモデルになっているから初期値問題が出るのでは?」という疑問もあってちゃんと理解しないとな、と思いました。
具体的には、「modelパラメータにif文である条件のときは0・・・というのできないからnormal(0,0)で実質的に0にするかー」とかいう処理をしたけど明らか問題あるよなこれ。って思ったからです。
サンプルコードおよび解釈として、Logic of Blueさんの以下の記事を参考に使用させてもらいます。
(どうでもいいのですが、Logic of Blue管理人さんのサイトや書籍はいつも勉強になっているのですが、私の出身高校の1つ下の学年ということを最近知って驚いた)
Stanによるベイズ推定の基礎 | Logics of Blue
data {
int n;
vector[n] Nile;
}
parameters {
real mu; # 確定的レベル(データの平均値)
real<lower=0> sigmaV; # 観測誤差の大きさ
}
model {
for(i in 1:n) {
Nile[i] ~ normal(mu, sqrt(sigmaV));
}
}
このStanコードのうちModelブロックで書いているNile[i] ~ normal(mu, sqrt(sigmaV))が何なのかが今回の疑問点です。
まずベイズの定義を考えます。
それぞれ分解すると、
は、データXが得られたときにパラメータθが従う確率分布。いわゆる 事後分布 。MCMCサンプリングによって得られる確率分布。・・・(1)
は、パラメータθのある値が得られたときにデータXが観測される確率。要するにパラメータθの尤度L(θ)
は、データXが従う確率分布。いわゆる 事前分布
は、Xが得られる確率で定数。
つまり、以下のように書き換えることができる。
また、コード中の表記に合わせると以下のようになる。
このときのf(ナイル川データ | mu, sigmaV)、「あるmu, sigmaV(未知)のときのナイル川のデータ(実データ)」というのがコードのNile[i] ~ normal(mu, sqrt(sigmaV))に相当する。
ナイル川データは実データなので、「mu,sigmaVを動かしたときにどういう値ならば実データのナイル川データが得られるか」という尤度関数を得ることができる。このときの尤度を求める計算としてnormal(正規分布)を用いる、というのがこのModelブロックに記載されているNile[i] ~ normal(mu, sqrt(sigmaV))の意味。
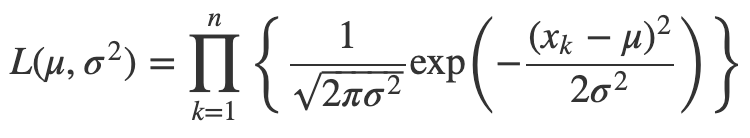
そして、Modelブロックで尤度の指定がされ、Parametersブロックで事前分布の指定がされたことでベイズの定理よりパラメータの事後分布を推定することができる。
言い方を換えると、「Modelブロックで確率モデルを記載するとその確率モデルに従う尤度関数を通すことで、確率モデルに用いたパラメータがMCMCによりベイズ推定される」「Nile[i] ~ normal(mu, sqrt(sigmaV))に従うmu, sigmaVをMCMCで推定する」
階層ベイズなどで例えばNile[i] ~ normal(mu[i], sqrt(sigmaV))、mu[i] ~ normal(mu_avg, sqrt(sigmaV))のようになっている場合、「mu,sigmaVを動かしたときにどういう値ならば 実データ のNileデータが得られるか」となるが、ここのmuはベイズ推定なので一意な値ではないためmu[i] ~ normal(mu_avg, sqrt(sigmaV))の「mu_avg,sigmaVを動かしたときにどういう値ならば ベイズ推定値(一意でない) のmuが得られるか」となる気がするが全組み合わせについてやってるのだろうか。謎だ。
はじめの話
はじめに書いた「modelパラメータにif文である条件のときは0(Sales ~ ... ではなく、Sales = 0)・・・というのできないからnormal(0,0)で実質的に0にするかー」とかいう処理の話。
modelブロックの意味を考えると、そもそもnormal(0,0)ってなんも推定してないやんけということがわかるし、尤度関数もそもそも1点に定まるっていう。それが原因でエラーになっているのかどうかはわからんが、少なくともModelブロックに書くのはおかしい気がする。
ただ、そうなると閉店フラグが0のとき値が一意(0)になるようなモデルはどう作れば。。。欠損値処理のように、そこだけ値を除去してあとで0で埋めるとかか?そもそもある条件のときだけ別のモデルに従うような場合ってどう書けばいいのだろう。
参考
http://rtokei.tech/stan/bayesian-inference-with-stan-005/
")
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者:久保 拓弥
- 発売日: 2012/05/19
- メディア: 単行本
Stanで統計モデリングを学ぶ(2): そもそもMCMCって何だったっけ? - 渋谷駅前で働くデータサイエンティストのブログ
P.48あたりから。
Stan勉強会資料(前編) from daiki hojo
www.slideshare.net
状態空間モデルをstanでやりたかった② パネルデータに対する状態空間モデル(階層ベイズ)
前回では以下のようなModelを考えた。
tが閉店日の場合、
それ以外の場合、
だが、結果としてsamplingがおこなわなかった。そのため、今回もプロットは無しで理屈のみ。。。
前回のモデルと今回のモデルの差
前回のモデルは「ある1店舗」の時系列を考えた。今回は、「全店舗」について考えたい。
店舗についての情報として、
- StoreType(店舗タイプ)
- Assortment(装飾のレベル)
などがある。
StoreTypeとAssortmentをかけ合わせたStoreTypeAssortmentを用いて、「StoreTypeAssortmentが同じ店舗の動きは似ているだろう」という仮設を入れた階層ベイズモデルを作成する。
このとき、以下のようなモデルとなる(id=店舗id、SA = StoreTypeAssortment) 。